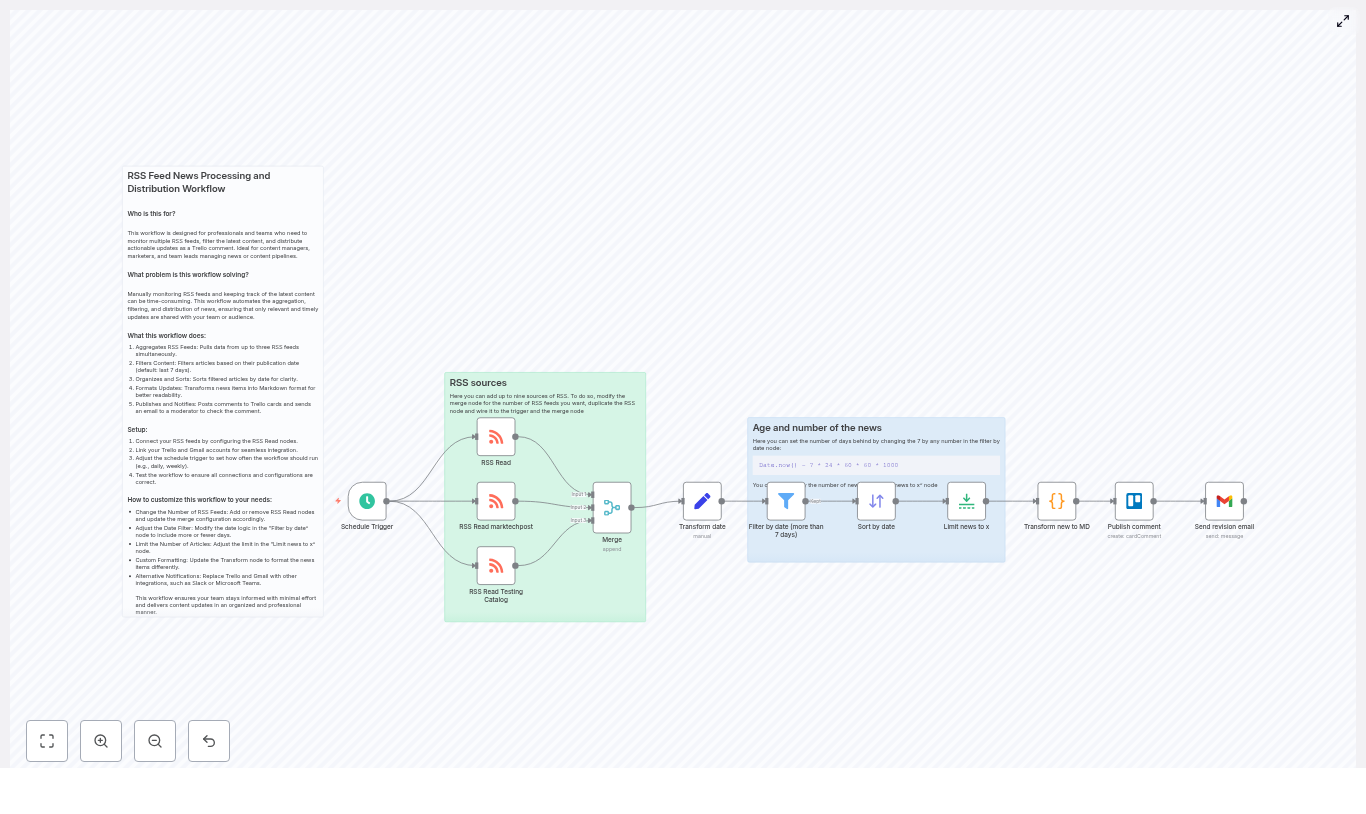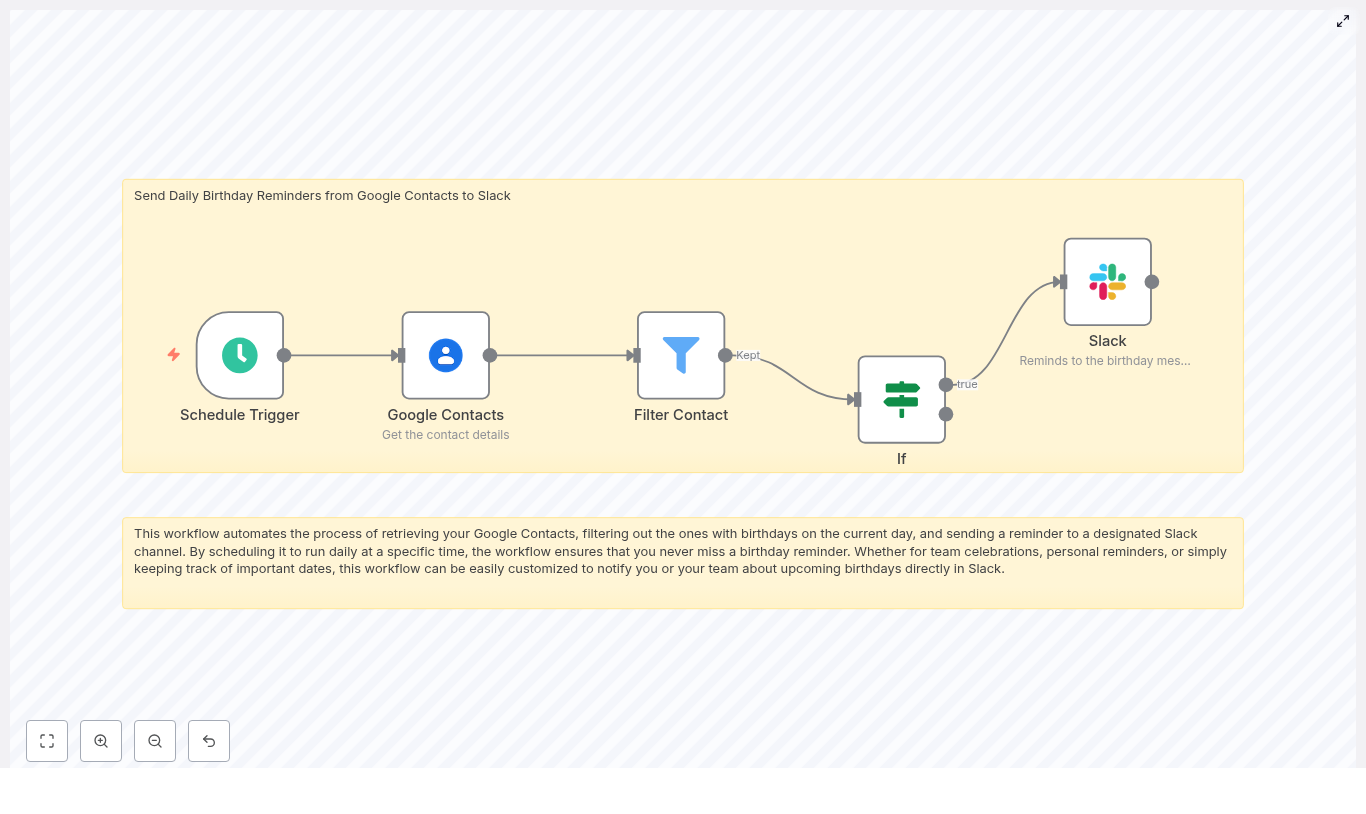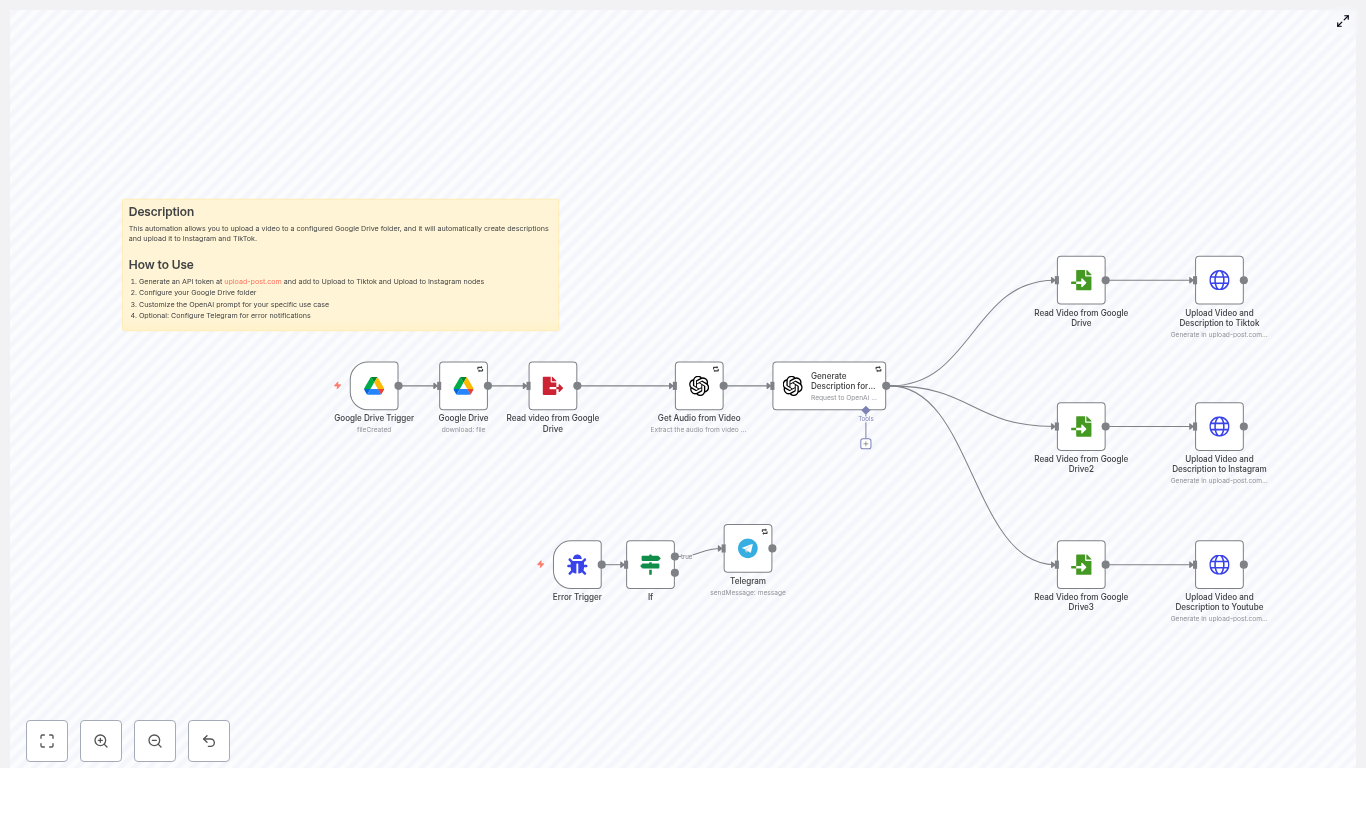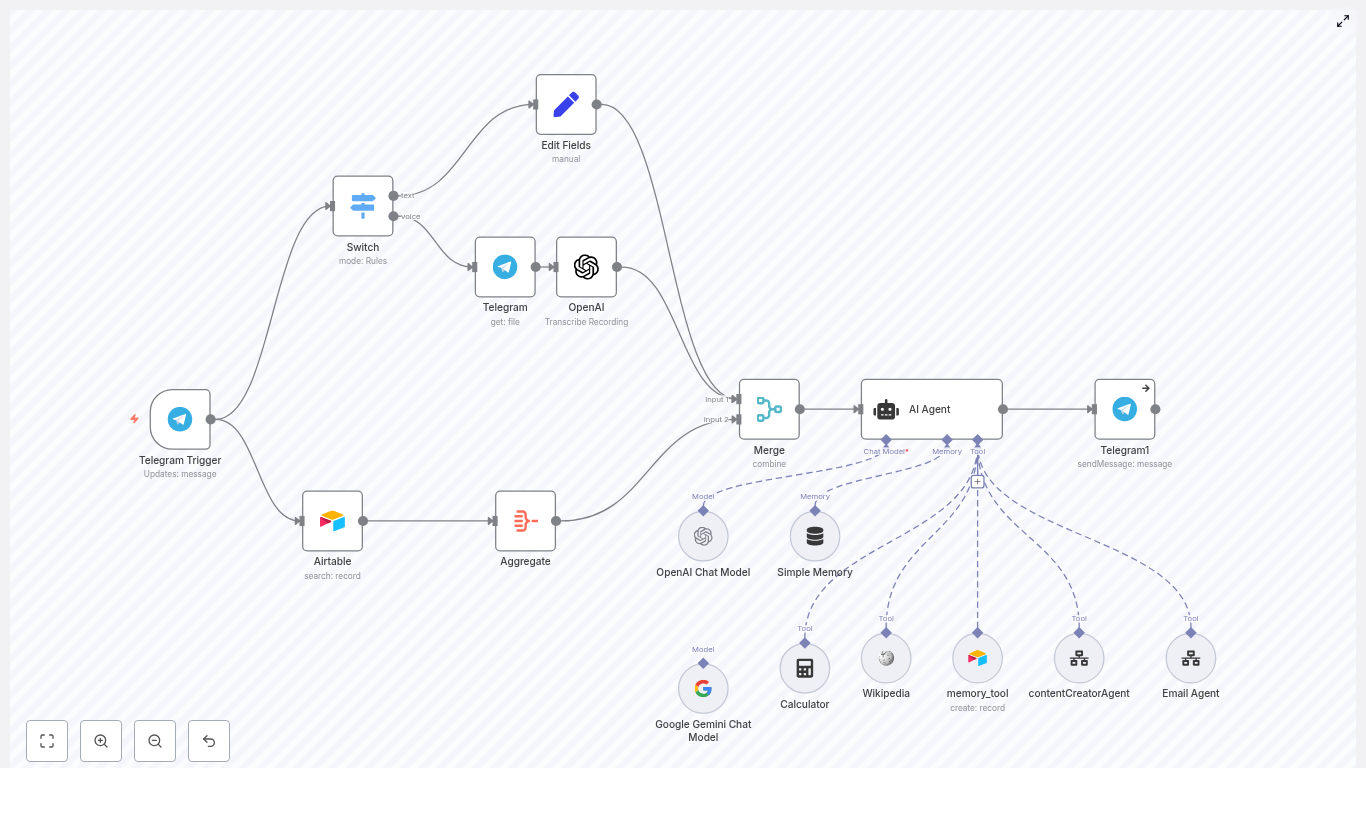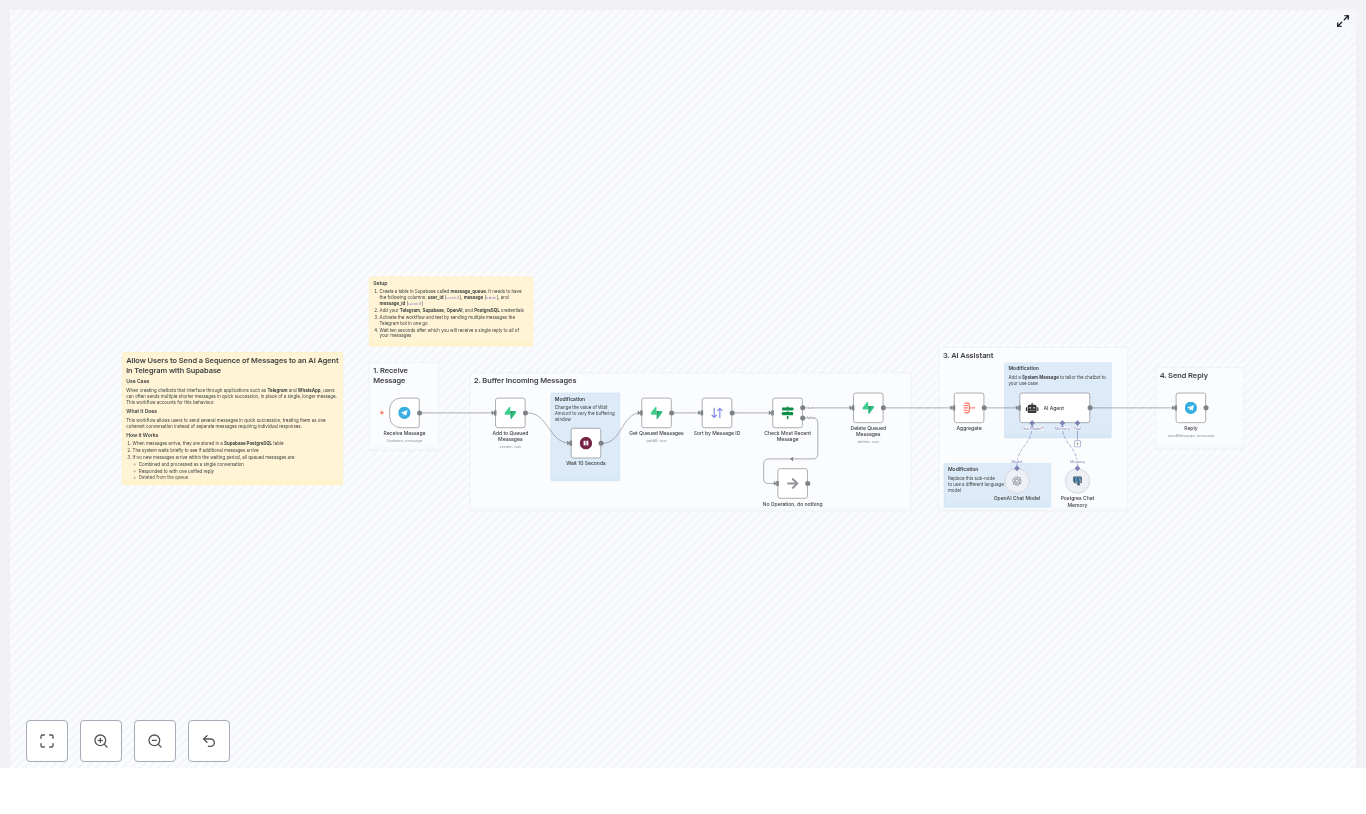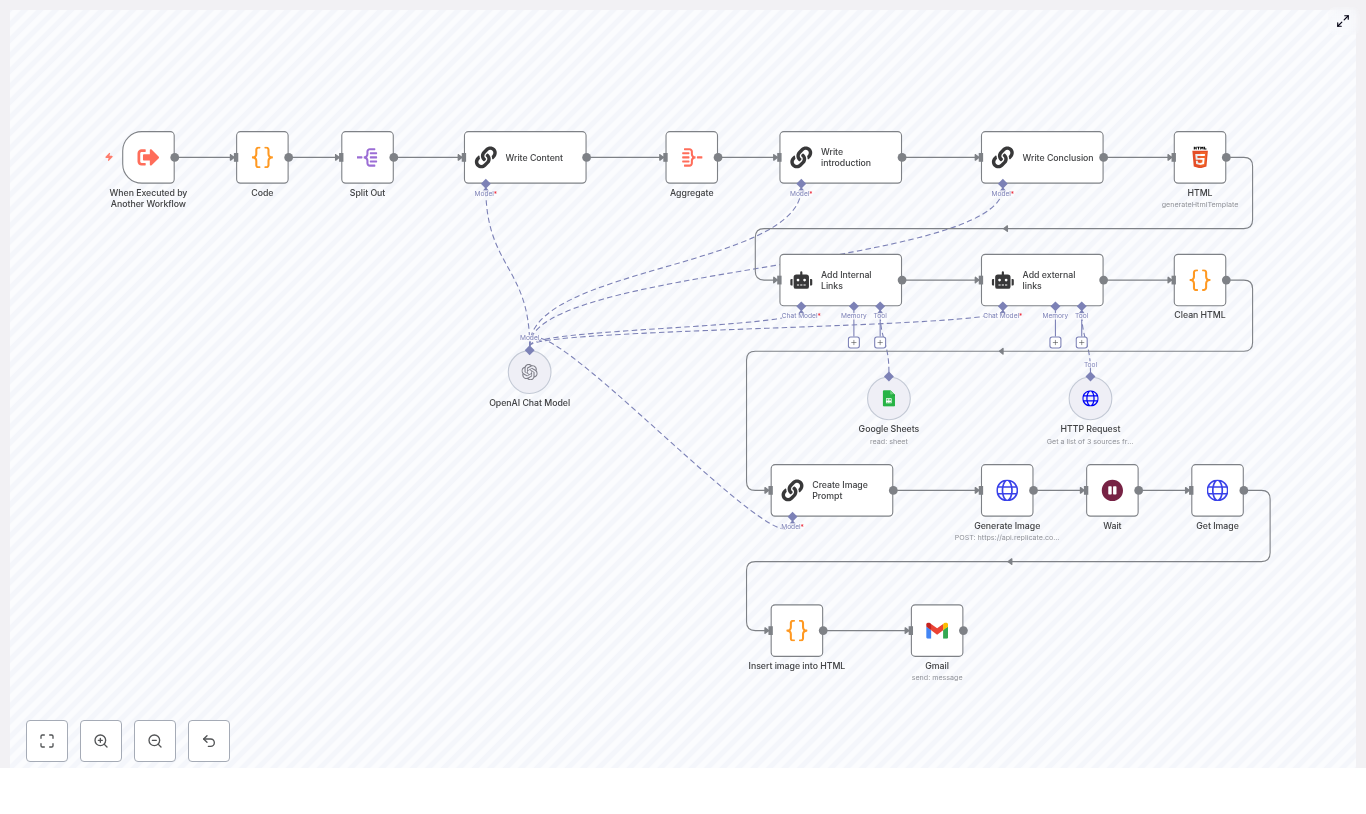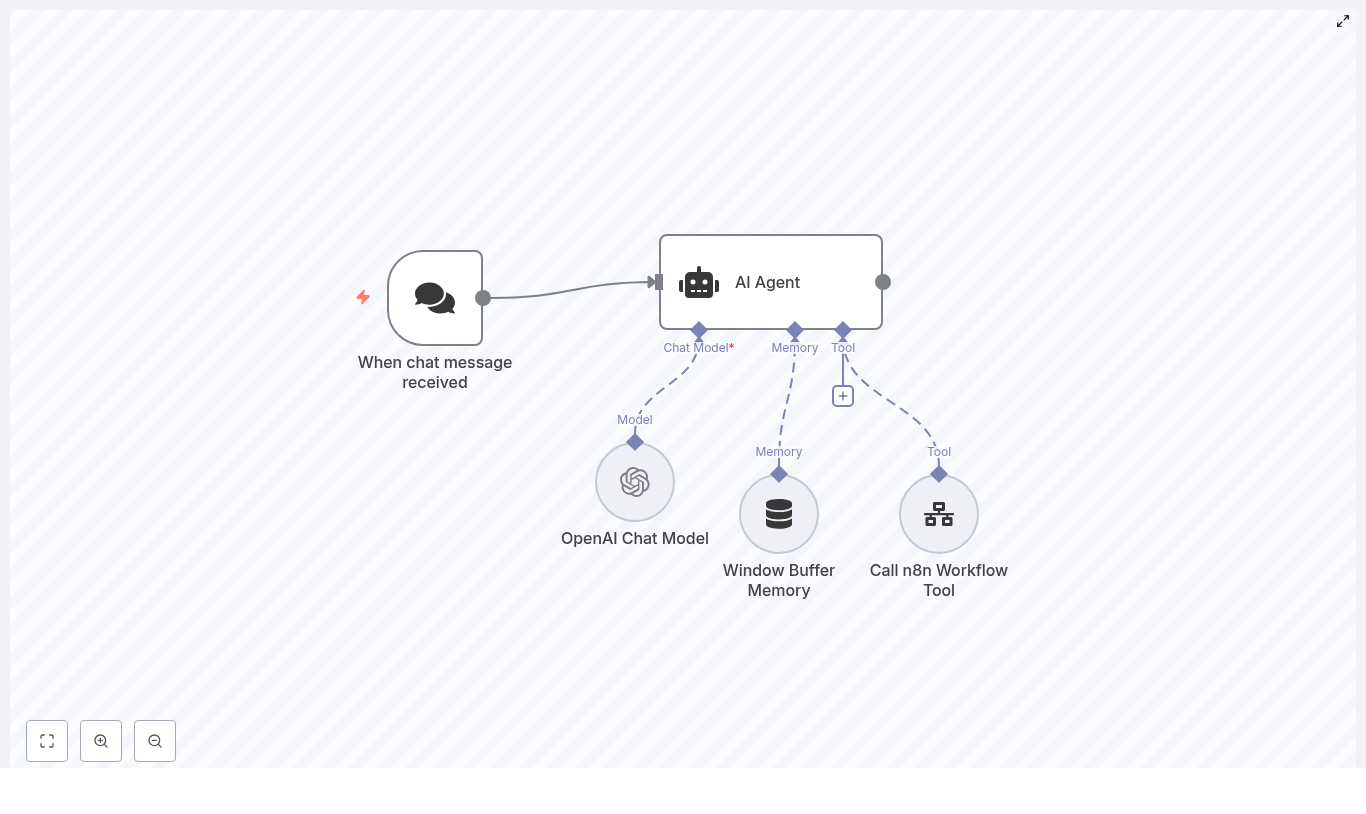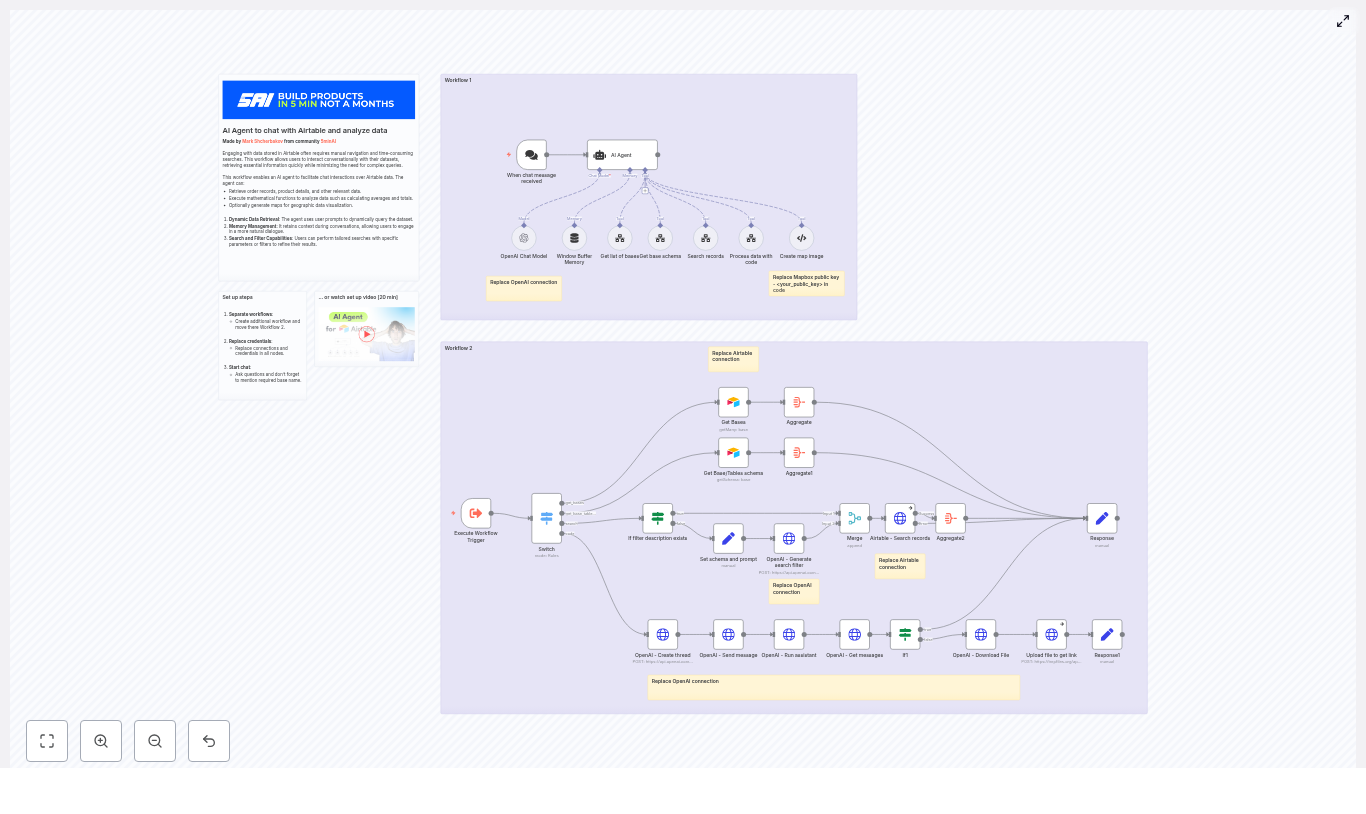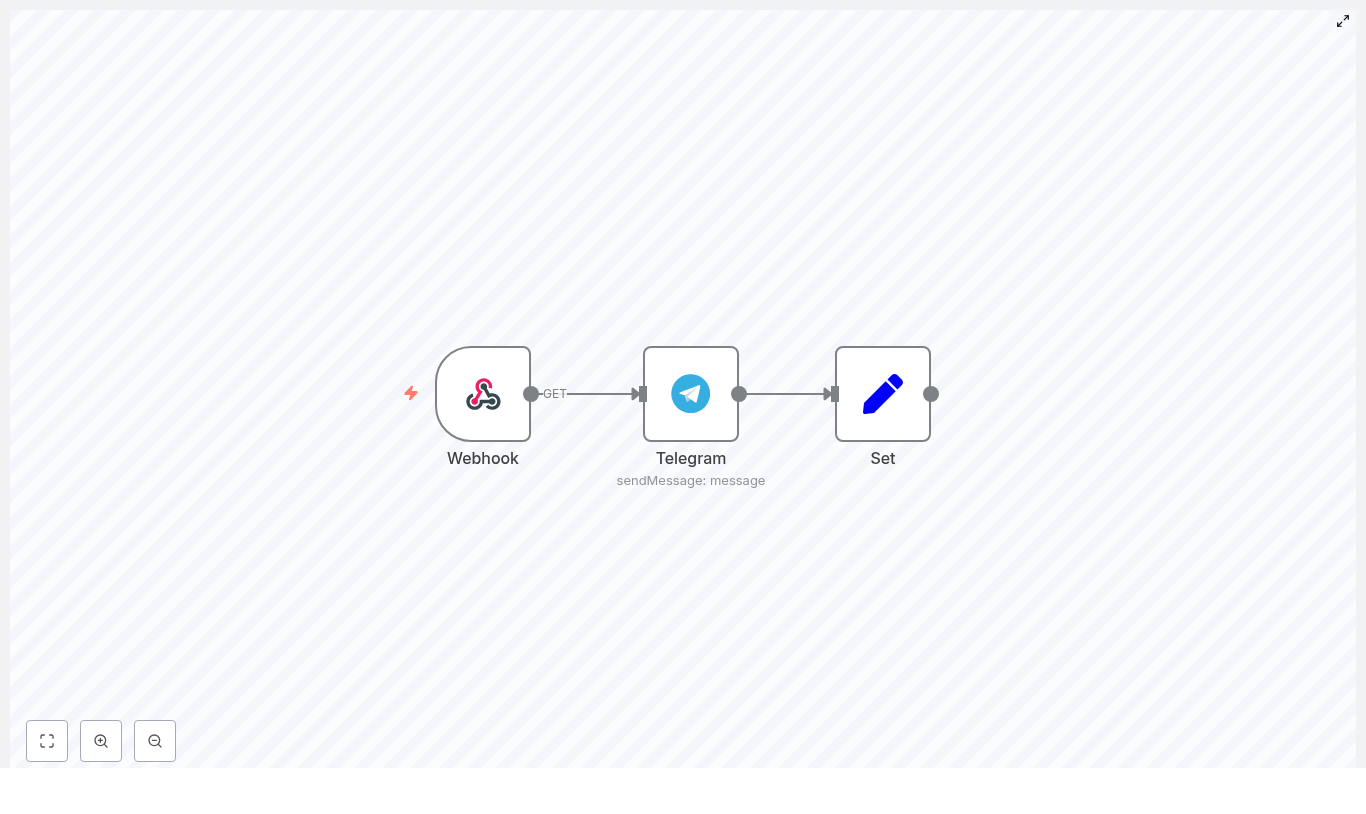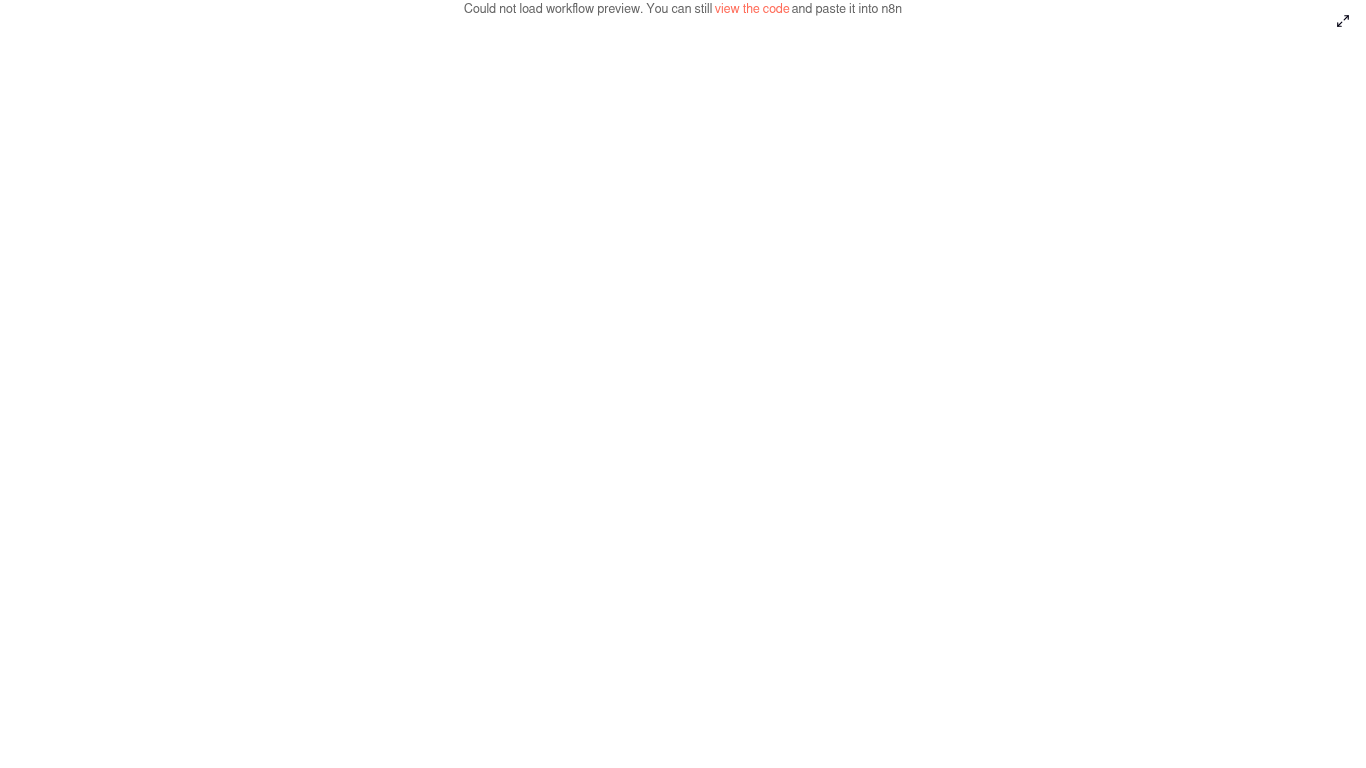
Fix “Could not load workflow preview” in n8n (Without Losing Your Mind)
You sit down, coffee in hand, ready to admire your beautiful n8n workflow. You click to open it and instead of a glorious node diagram, you get:
“Could not load workflow preview. You can still view the code and paste it into n8n.”
Blank white panel. No nodes. No joy.
Annoying? Absolutely. Permanent? Usually not. This guide walks you through why this error appears, what is actually going wrong behind the scenes, and how to get your workflow preview working again so you can get back to automating away your repetitive tasks instead of troubleshooting them.
What this n8n error actually means
That “Could not load workflow preview” message is n8n’s polite way of saying:
“Something blew up while trying to render your workflow UI, but I am not going to tell you exactly what in this box. Please check somewhere else.”
In practice, it is a generic fallback when the frontend cannot render the workflow diagram. The workflow itself is often still usable, but one or more of these issues is getting in the way:
- Broken or incompatible custom nodes bundled with the workflow, such as syntax or compile problems.
- Node.js version mismatch between the environment that exported the workflow and the n8n instance where you are opening it.
- Missing dependencies or peerDependencies required by a node, for example native modules or packages that need Node 18 or higher.
- Corrupted or malformed workflow JSON, or unexpected fields n8n does not know what to do with.
- Browser or server errors such as CORS issues, network failures, or server-side exceptions while generating the preview.
The good news is that almost all of these can be diagnosed with a bit of log-watching and version-checking.
Start here: quick checks before you dive deep
Before you start rebuilding half your stack, do a quick triage. These simple checks often reveal the problem immediately.
- Open your browser developer tools with F12 and watch both Console and Network while loading the workflow preview. Note any red errors or failed requests.
- Click the “view the code” link in the error message if available and inspect the exported workflow JSON for anything obviously strange.
- Check your n8n server logs. Many preview failures are actually server-side errors that never show up in the UI.
- Verify your Node.js version. A lot of modern dependencies now declare
"engines": { "node": ">=18" }. If your n8n instance is still running on Node 16, you are likely to see runtime crashes.
If any of those already looks suspicious, you probably found your culprit. If not, keep going.
The usual suspect: custom nodes and dependency mismatches
In many cases this error shows up when a workflow uses custom nodes that bring their own set of dependencies and runtime requirements. For example, a package like n8n-nodes-mcp might depend on:
@langchain/core@modelcontextprotocol/sdkzod
These packages might:
- Require Node.js 18 or newer to run correctly.
- Include native bindings or peer dependencies that are not installed on your server.
- Break if your TypeScript or ESM/CommonJS settings are different from what the custom node expects.
As a result, n8n tries to evaluate the custom node while rendering the preview, the module explodes, and the UI falls back to “Could not load workflow preview”.
How to fix custom node problems
- Make sure your n8n server runs on the Node version required by your custom nodes. If the package.json says
"node": ">=18", then n8n should be running on Node 18 or higher. - Reinstall and rebuild the custom node package with the same Node version used by n8n:
npm ci # or npm install # then, if needed npm run build - If a dependency is ESM only, make sure the n8n process supports it, or bundle/convert it to CommonJS before publishing the custom node.
Once the custom node and runtime are on speaking terms again, the preview usually starts working without further drama.
Step-by-step rescue plan for a workflow that will not preview
If the quick checks did not immediately solve it, here is a more structured way to recover the workflow. Think of it as a mini incident response, but for your sanity.
1. Inspect the workflow JSON directly
First, grab the raw workflow data.
- Use the “view the code” link from the error message or download the exported workflow JSON.
- Open it in a text editor and look for:
- Very large base64 blobs that might be causing memory issues.
customornodesfields that reference packages not installed in your n8n instance.
If you see references to custom node packages you do not have, that is a strong hint.
2. Reproduce and capture server-side errors
Next, you want to see what the server is complaining about while the preview fails.
On a Linux server, run n8n with logging visible:
NODE_ENV=production n8n
# or, if you run via Docker
docker logs -f <n8n-container-name>
Then try to open the workflow preview again and watch for stack traces or module errors. Match any failing module names with your package-lock.json or dependencies, especially those that specify "engines": { "node": ">=18" }.
3. Fix Node.js and dependency mismatches
If the logs show errors like:
SyntaxError: Cannot use import statement outside a moduleERR_REQUIRE_ESM
you are almost certainly dealing with an ESM vs CommonJS mismatch or an outdated Node.js runtime.
- Option A (recommended): Upgrade the Node.js runtime used by n8n to meet the package requirements, for example Node 18+.
- Option B: Rebuild your custom nodes so they:
- Target CommonJS, or
- Are bundled into a single compatible file using tools like Rollup or esbuild.
Once the runtime matches what the dependencies expect, those import errors should disappear.
4. Reinstall node modules for your custom nodes
If your workflow uses custom nodes, go to the root of the custom node project and reinstall dependencies cleanly:
npm ci
# or, if you prefer
npm install
# then build if you use TypeScript or bundling
npm run build
After the build completes, restart n8n so it can load the newly built node bundle.
5. Use manual import as a fallback
If the preview stubbornly refuses to load, the workflow itself can still often be imported and executed.
- In the n8n UI, go to Workflows → Import and paste the JSON content directly.
- Or use the CLI:
n8n import:workflow --input=path/to/workflow.json(Exact command may depend on your n8n version.)
This does not fix the preview issue, but it lets you keep working with the automation while you sort out the environment.
For custom node developers: how to avoid breaking previews
If you are the one publishing custom nodes, you can save your users a lot of headache by making your package easier for n8n to run.
- Document engine requirements clearly in your README and package.json, including Node.js version and any required npm packages.
- Bundle heavy or runtime-only dependencies like SDKs or LangChain, or mark them as optional and explain how integrators should provide them.
- Stick to one module system (ESM or CommonJS) and test the package in a fresh n8n instance before publishing it.
- Provide a prebuilt JS distribution so users do not have to run a build step just to use your nodes.
Why the engines field matters so much
In the dependency list you shared, many modules declare:
"engines": { "node": ">=18" }
If n8n is running on Node 16, and the preview UI tries to evaluate nodes that rely on newer Node APIs, the process will crash or throw runtime errors. The fix is straightforward but important:
- Run n8n on Node 18 or later, either by upgrading the host or using a container image with the correct Node version.
Once the Node engine matches what your dependencies expect, a lot of mysterious preview issues vanish.
Do not forget the browser: front-end checks
Sometimes the backend is fine and the problem lives entirely in your browser. Before you rewrite your workflow from scratch, check for client-side issues.
- In DevTools → Network, look for failed requests when the preview loads, especially CORS related errors.
- Disable browser extensions or open an incognito window to rule out extension interference.
- Clear cache and reload the n8n UI to make sure you are not dealing with stale assets.
It is surprisingly common for a browser plugin to cause more trouble than all your Node dependencies combined.
Still stuck? What to collect before asking for help
If you have tried the steps above and the preview still will not cooperate, you will get better help if you come armed with a bit of diagnostic data.
Gather the following before posting in the n8n community or opening an issue in a custom node repository:
- Browser console logs and any visible errors.
- Server logs from the n8n process, including full stack traces.
- The exported workflow JSON (with secrets removed or sanitized).
- Your n8n version, Node.js version, and whether you are running via Docker or directly on the host.
- A list of custom nodes you use and their
package.jsoncontent, especially theenginesanddependenciessections.
With that information, it is usually possible to pinpoint the exact module or version causing the preview to fail.
Checklist recap: turning “Could not load workflow preview” into “All good”
- Open browser console and n8n server logs to capture any errors.
- Confirm that your Node.js version matches dependency requirements, and upgrade to Node 18+ if needed.
- Reinstall and rebuild custom nodes, then restart n8n.
- If you use ESM-only dependencies, bundle them or publish CommonJS builds that n8n can require.
- If the preview still fails, import the workflow JSON manually via the UI or CLI so you can continue working.
Wrapping up
“Could not load workflow preview” looks intimidating, but it is usually just a symptom of something more mundane, like:
- A Node.js version lagging behind modern dependencies.
- A custom node that was built for a different environment.
- A browser or network quirk blocking the preview request.
By checking logs, confirming your Node.js and dependency compatibility, and rebuilding or bundling any custom nodes, you can usually get the preview working again without sacrificing your entire afternoon to debugging.
If you would like a second pair of eyes on it, share your workflow JSON or the package.json of your custom node (especially the engine constraints), and you can get a tailored set of rebuild or packaging steps to make everything n8n friendly again.
Call to action: Have a stubborn workflow export or custom node repo? Share the details and get a step-by-step repair plan with example build commands so you can get back to automating repetitive work instead of repeating debugging steps.