Automated Meeting Scheduler with n8n & OpenAI
Manual meeting coordination is a classic time sink for operations and technical teams. Parsing free-text requests, checking calendars, avoiding conflicts, and sending confirmations all introduce friction and context switching. Using n8n with an OpenAI-based agent, you can automate this entire workflow end to end: interpret natural-language scheduling requests, validate availability in Google Calendar, create events, and send confirmation emails, all within a single orchestrated automation.
This guide walks through a production-ready meeting scheduler built on n8n. It uses an OpenAI agent (configured in a LangChain-like pattern) together with Google Contacts, Google Calendar, and Gmail. The result is a robust, extensible scheduling system that can be adapted to your internal processes and compliance requirements.
Business value of automated scheduling
For organizations that handle frequent customer calls, demos, or internal meetings, automating scheduling is a straightforward way to reduce operational overhead. An n8n-powered scheduler delivers:
- Lower coordination overhead by eliminating back-and-forth emails to find suitable times.
- Reduced double-bookings through automatic calendar conflict checks.
- Centralized audit trail with a single, automated source of truth for invitations and responses.
- Natural-language flexibility using AI to interpret unstructured scheduling requests from email, forms, or call transcriptions.
For automation professionals, this pattern is also a reusable blueprint for other AI-assisted workflows that blend natural language understanding with deterministic business logic.
Architecture overview
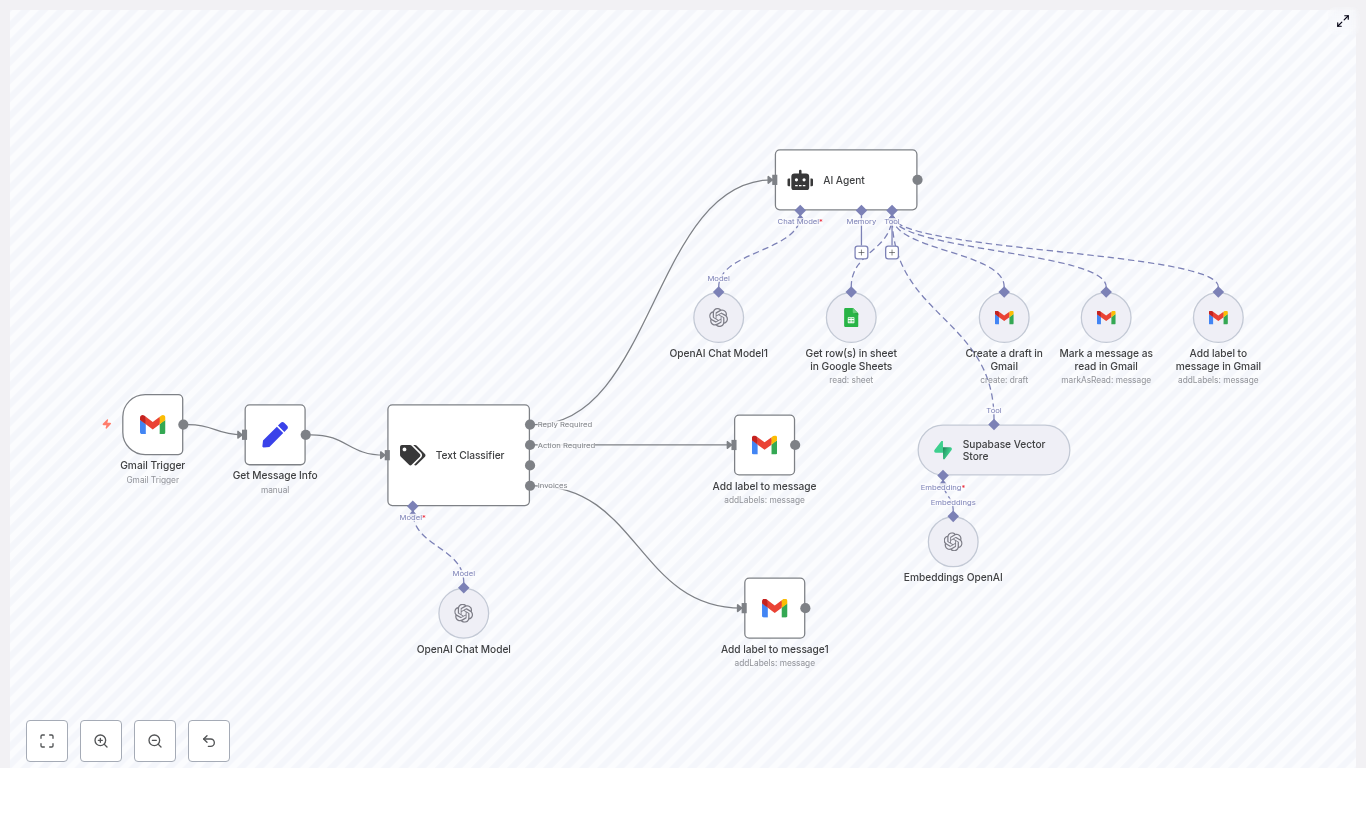
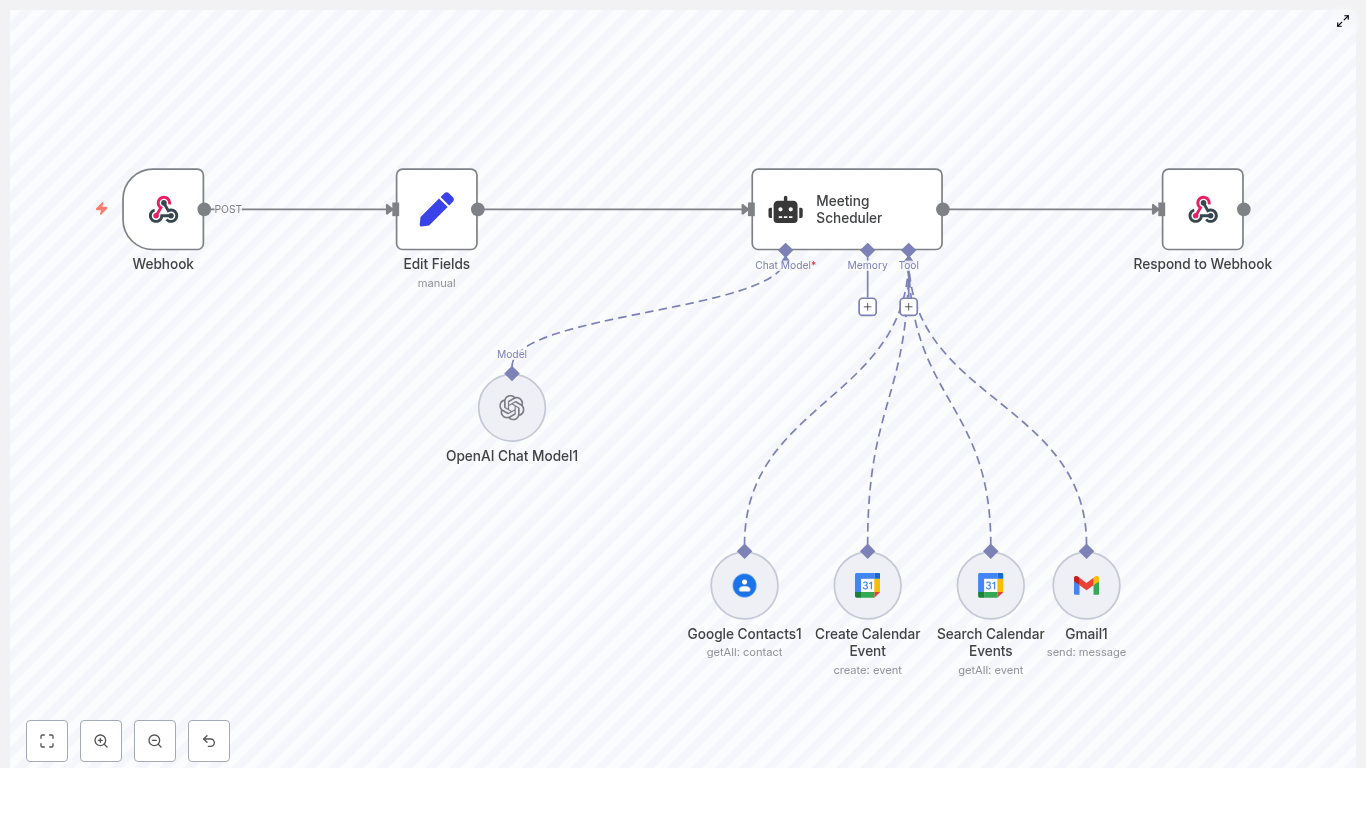
The workflow is implemented as an n8n pipeline that starts with a webhook trigger, hands off interpretation to an OpenAI agent, and then uses Google services as tools for contact lookup, availability checks, event creation, and notifications.
Core components and nodes
- Webhook – Entry point for scheduling requests, accepting JSON payloads from forms, systems, or transcription services.
- Edit Fields – Normalizes and maps incoming payloads into a consistent schema for the agent.
- Meeting Scheduler (AI agent) – An OpenAI-driven agent configured with tool access to Google Contacts, Google Calendar, and Gmail.
- OpenAI Chat Model – The underlying LLM that interprets the request and orchestrates tool calls.
- Google Contacts – Resolves attendee information and email addresses from contact data.
- Search Calendar Events – Queries Google Calendar for existing events to check availability.
- Create Calendar Event – Creates the final meeting in the target Google Calendar.
- Gmail – Sends confirmation or follow-up emails to the requester and other participants.
- Respond to Webhook – Returns a structured response payload to the original caller or upstream system.
End-to-end flow: how the scheduler operates
1. Ingest scheduling requests via webhook
The process begins with the Webhook node, which exposes an HTTP endpoint. Any client that can send JSON can initiate a scheduling request. Typical sources include:
- Web forms or internal tools submitting structured data.
- Customer support systems sending ticket details.
- Voice transcription services posting call transcripts.
Example request payload:
{ "requester": "alex@example.com", "text": "Can we meet next Tuesday afternoon for a 30-minute product demo?", "timestamp": "2025-09-10T09:00:00Z"
}
This payload contains the requester identity, the natural-language description of the meeting, and a reference timestamp that can help interpret relative time expressions such as “next Tuesday afternoon”.
2. Normalize and map fields for the agent
Raw inputs often vary across channels. The Edit Fields node standardizes these differences by mapping the incoming fields into a clean set of variables that the agent expects. Typical mappings include:
summaryordescriptionfor the meeting topic.- Preferred
startandendwindows derived from the text or timestamp. requester_emailfor follow-up and confirmation.- Optional metadata such as priority or meeting type.
Defining clear, consistent field names simplifies prompt engineering and reduces ambiguity in the agent’s decision logic.
3. Delegate interpretation and decisioning to the OpenAI agent
The Meeting Scheduler node is configured as an agent that can call specific n8n tools. It uses the OpenAI Chat Model as its language model, guided by a system message that defines its role and constraints.
Within this agent, you grant access to:
- Google Contacts to resolve attendee details.
- Search Calendar Events to validate availability.
- Create Calendar Event to schedule meetings when appropriate.
- Gmail to send confirmation or clarification emails.
The agent analyzes the natural-language text and any normalized fields, then decides:
- Which contact(s) to invite using Google Contacts lookup.
- Which time range(s) to query in Google Calendar for conflicts.
- Whether it has sufficient information to create an event or should request alternative times.
This pattern combines flexible language understanding with explicit tool boundaries, which is a best practice for production-grade AI workflows.
4. Validate availability using Google Calendar
Before any event is created, the workflow checks the calendar. The agent calls the Search Calendar Events node with a timeMin and timeMax window that reflects the proposed slot, for example “next Tuesday afternoon” resolved into concrete timestamps.
Key behaviors at this stage:
- If the Search Calendar Events node returns conflicting events, the agent can propose alternate windows and respond accordingly.
- If no conflicts are detected, the workflow proceeds to event creation.
For high-volume environments, it is advisable to perform a final availability check immediately before creating the event to avoid race conditions.
5. Create the calendar event and send notifications
Once a free slot is confirmed, the agent triggers the Create Calendar Event node. This node writes the finalized meeting to Google Calendar, including:
- Title or summary derived from the request context.
- Start and end time in the correct timezone.
- Attendees resolved via Google Contacts.
- Optional description or agenda items.
After successful creation, the workflow uses the Gmail node to send confirmation emails. Typical patterns include:
- A confirmation email to the requester with event details and calendar link.
- An optional notification to the organizer or internal team.
Finally, the Respond to Webhook node returns a structured JSON response to the caller, indicating success or failure, the chosen time, and any relevant metadata. This makes integration with upstream systems straightforward.
Credential configuration and required permissions
For the workflow to run reliably, correct credentials and API scopes are essential. Configure the following in your Google Cloud and n8n environment:
- Enable APIs in Google Cloud Console:
- Google Calendar API
- Gmail API
- People API (for Google Contacts)
- Create OAuth 2.0 Client credentials and add your n8n instance’s redirect URI.
- In n8n, create:
- Google OAuth credentials with scopes that cover Calendar and Contacts.
- Gmail credentials for sending email, or a single Google OAuth credential that includes both calendar and Gmail scopes.
- OpenAI access:
- Provide your OpenAI API key to the OpenAI Chat Model node.
Validate that scopes include at least calendar.events and gmail.send to avoid runtime errors when creating events or sending emails.
Designing effective agent prompts and guardrails
The reliability of the workflow depends heavily on the agent’s system prompt. Clear, explicit instructions help constrain behavior and reduce unexpected actions. Recommended guidelines to include in the prompt:
- Only search Google Contacts using the exact name field provided by the user.
- Always check calendar availability via the designated calendar before creating any event.
- Send a confirmation email to the requester after a successful booking.
- Return a structured JSON response describing actions taken and any follow-up requirements.
Example system message for the agent configuration:
You are a meeting-scheduling assistant. Use the Google Contacts tool to find an attendee by the exact name provided. Check the specified Google Calendar for conflicts before creating an event. If the requested time is free, create the event and send a confirmation email to the requester. Always return a structured JSON response describing the action taken.
For production use, consider iterating on this prompt with real-world test cases and logging to refine behavior and error handling.
Implementation best practices
Time handling and consistency
- Normalize timezones: Convert all incoming timestamps to the calendar’s canonical timezone before searching or creating events. This avoids subtle off-by-one-hour errors, especially around daylight saving changes.
- Use reference timestamps: When interpreting phrases like “next Tuesday afternoon”, use the
timestampfield from the payload as the reference point.
Concurrency and reliability
- Avoid race conditions: If you anticipate concurrent requests, perform a final Search Calendar Events call just before Create Calendar Event to confirm that the time slot is still free.
- Graceful fallbacks: When the agent is uncertain about the correct contact or time, instruct it to request clarification instead of making assumptions that could create incorrect invites.
- Monitoring and observability: Add logging nodes or dedicated branches for error handling to track failed OAuth refreshes, API rate limits, or unexpected agent outputs.
Troubleshooting common issues
If events are not being created or emails are not sent as expected, verify the following:
- Scopes and credentials:
- Confirm that the Google OAuth token includes
calendar.eventsandgmail.sendscopes. - Ensure that the correct Google account is connected in n8n.
- Confirm that the Google OAuth token includes
- Payload integrity:
- Inspect the output of the Webhook and Edit Fields nodes to confirm that fields are correctly mapped and formatted.
- Agent behavior:
- Review agent logs or debug output to confirm that it is calling Google Contacts, Calendar, and Gmail as intended.
- Check the system prompt for overly vague instructions that might lead to skipped actions.
Security and privacy considerations
Meeting scheduling often involves personal data, including email addresses, names, and potentially sensitive topics in the request text. Treat this workflow as part of your broader security architecture.
- Secure the webhook endpoint:
- Use secret tokens, signatures, or IP allowlists to prevent unauthorized requests.
- Limit credential scope:
- Grant only the minimum required Google API scopes and store credentials securely within n8n.
- Data transparency:
- Inform users where their data is stored, including calendar entries and email notifications, and comply with relevant data protection regulations.
Extending and customizing the workflow
Once the core scheduler is stable, you can iterate and extend it to better match your organization’s processes.
- Slot selection interfaces:
- Integrate a UI that lets invitees choose from AI-proposed slots before finalizing the event.
- ICS support:
- Attach ICS files to confirmation emails for recipients who do not use Google Calendar.
- Context enrichment:
- Extend the agent to summarize the meeting agenda and attach relevant documentation or links automatically.
Conclusion and next steps
By combining n8n’s workflow orchestration with an OpenAI-driven agent and Google’s productivity APIs, you can build a sophisticated, natural-language meeting scheduler that significantly reduces operational friction. The pattern scales from simple one-on-one bookings to more complex internal scheduling scenarios while remaining transparent and auditable.
Use the template described here as a foundation, then refine the agent prompt, error handling, and logging to align with your organization’s standards. Over time, this workflow can evolve into a central scheduling service for multiple teams and tools.
Call to action: Deploy this workflow in your n8n instance, import the template, connect your Google and OpenAI credentials, and test with representative scheduling requests. For a downloadable template or tailored support in adapting this flow to your environment, subscribe to our newsletter or contact our team.