Build n8n Developer Agent Workflows (Template Guide)
This guide explains how to install, configure, and extend the n8n Developer Agent template so you can automatically generate, validate, and deploy importable n8n workflows. It covers the overall architecture, key nodes, integration patterns, setup sequence, and operational best practices for automation professionals who want to industrialize workflow creation with AI.
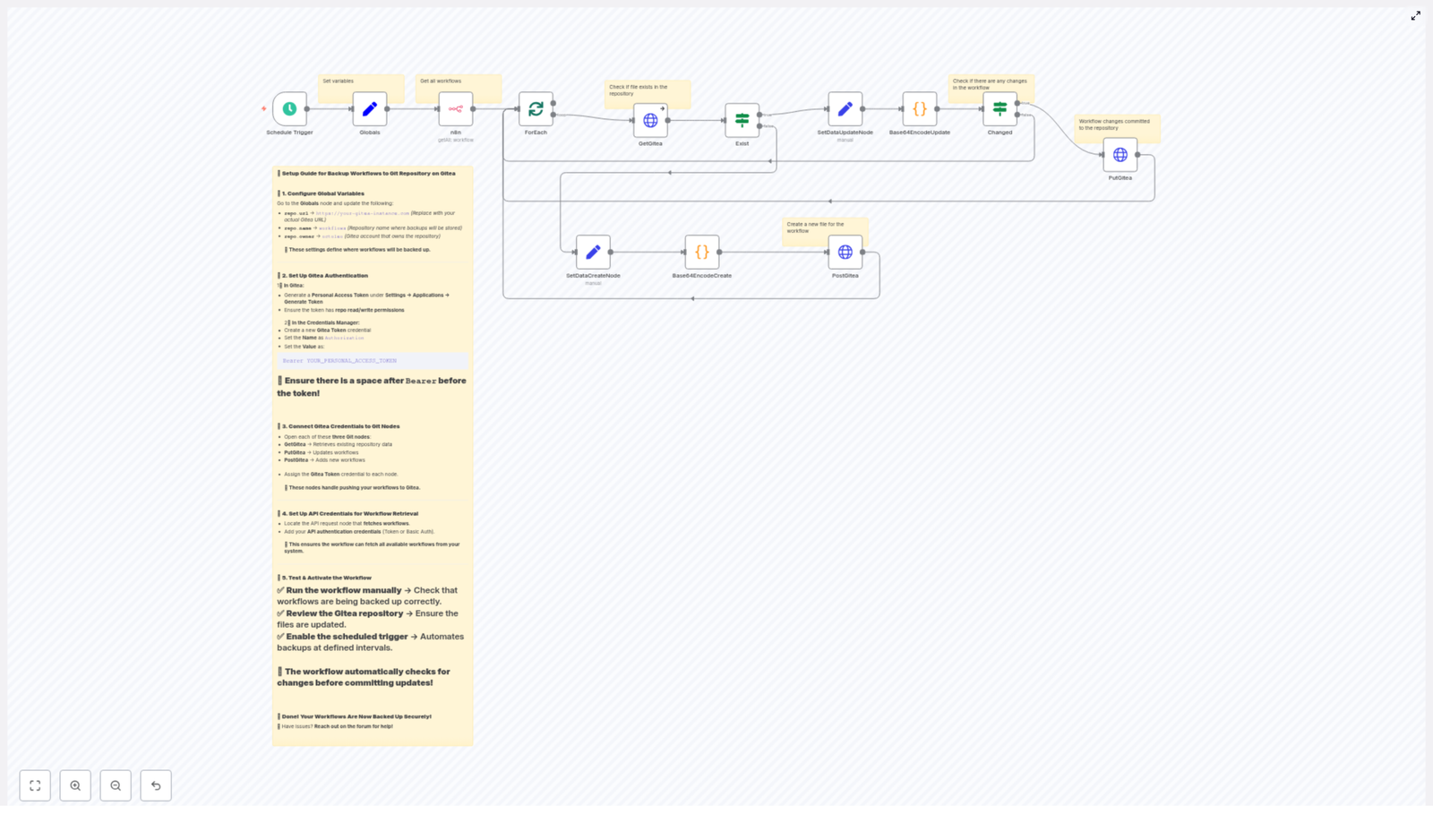
Overview: What the n8n Developer Agent template does
The n8n Developer Agent template is designed to turn natural-language requirements into production-ready n8n workflows. It combines:
- A conversational chat or webhook trigger
- LLM-based developer agents (GPT and Claude)
- Memory for multi-turn context
- Tooling that generates valid n8n workflow JSON
- Optional documentation context from Google Drive
- Automatic workflow creation through the n8n API
The result is a repeatable pattern where non-developers can describe automations in plain language, and the system produces a complete workflow that can be imported or directly instantiated in your n8n instance.
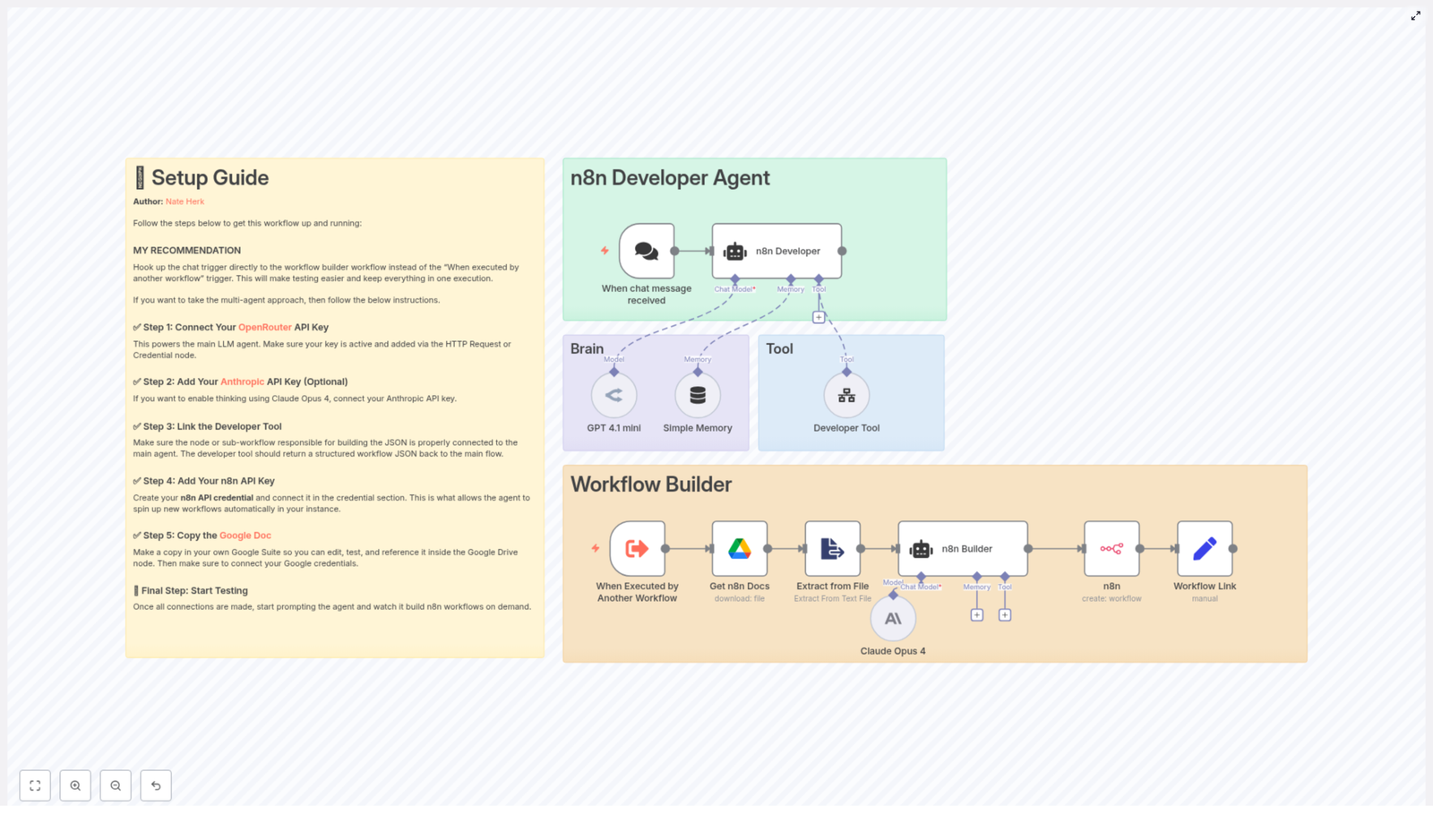
Architecture and main building blocks
The template is structured into two cooperating subsystems:
- Developer Agent – handles interaction, reasoning, and workflow design.
- Workflow Builder – materializes the design into a valid n8n workflow via the API.
Developer Agent subsystem
This part of the template is responsible for understanding user intent, planning the automation, and coordinating with tools that generate the final workflow JSON.
- When chat message received – the primary entry point. This can be a chat-based trigger or webhook that accepts the user request or specification.
- n8n Developer (Agent) – the central conversational agent node. It interprets the user prompt, maintains context, calls tools, and orchestrates subsequent steps required to produce a workflow.
- Language models:
- GPT 4.1 mini (OpenRouter) – configured as a core “brain” node for workflow design and generation.
- Claude Opus 4 (Anthropic) – optionally used for deeper reasoning, deliberation, or multi-model comparison.
- Simple Memory – a memory buffer that preserves conversational context across multiple turns, which is critical for refining complex workflows iteratively.
- Developer Tool – a dedicated tool node or sub-workflow that receives the refined specification and outputs a complete n8n workflow as JSON.
Workflow Builder subsystem
The Workflow Builder converts the JSON produced by the Developer Tool into a concrete workflow in your n8n instance and optionally enriches the generation with internal documentation.
- When Executed by Another Workflow – a secondary trigger that allows the Developer Agent to call the builder as an isolated execution. This supports separation of concerns between “design” and “deployment”.
- Get n8n Docs (Google Drive) – retrieves reference material such as internal standards, reusable patterns, or template workflows from Google Drive.
- Extract from File – converts or extracts plain text from the retrieved document so it can be used as context for the agent or builder logic.
- n8n (API node) – interacts with the n8n REST API to create new workflow objects from the generated JSON.
- Workflow Link (Set) – constructs a user-friendly, clickable URL that points to the newly created workflow in your instance.
Preparation and credential configuration
Before running the template in a production-like environment, you must configure all external integrations and credentials. This section outlines the recommended order.
1. Configure language model providers
The Developer Agent relies on LLMs to interpret requirements and design workflows. You can use one or both of the following:
- OpenRouter (recommended)
- Obtain an OpenRouter API key.
- Open the GPT 4.1 mini node and attach your OpenRouter credentials.
- Verify the model and endpoint settings match your OpenRouter configuration.
- Anthropic (optional)
- If you want to leverage Claude Opus 4 for advanced reasoning or multi-model responses, create an Anthropic API key.
- Attach the key to the Claude Opus 4 node credentials.
- Enable or tune any “thinking” or deliberation parameters as needed for your use case.
2. Connect the Developer Tool
The Developer Tool is the critical component that transforms a natural-language prompt into a valid n8n workflow JSON. Whether implemented as a tool node or a sub-workflow, it must:
- Accept the user prompt or refined specification as input.
- Generate a complete workflow JSON object, including:
namenodesconnectionssettingsstaticData(if required for the workflow)
- Return only valid JSON that:
- Begins with
{and ends with}. - Contains no additional commentary, markdown, or explanatory text.
- Begins with
Any deviation from strict JSON output will cause failures in the subsequent API creation step, so treat this as a contract between the agent and the builder.
3. Add n8n API credentials
To allow the Workflow Builder to create workflows automatically, configure an n8n API credential:
- Create a dedicated API token or credential in your n8n instance.
- Attach it to the n8n (API node) within the template.
- Verify the base URL, authentication method, and required headers align with your n8n deployment (cloud or self-hosted).
4. Set up Google Drive integration (optional but recommended)
If you want the agent to respect internal standards or reuse existing patterns, connect Google Drive so the builder can reference your documentation:
- Configure Google Drive credentials in n8n.
- In the Get n8n Docs node, specify:
- The target file ID, or
- A shared document path that contains your reference material.
- Ensure the Extract from File node is set to convert the document into plain text for downstream use.
5. Validate locally and in staging
Before enabling automated workflow creation in any production environment:
- Trigger the workflow via the chat or webhook entry point.
- Inspect the generated workflow JSON in the execution logs.
- Export that JSON and import it manually into a staging n8n instance.
- Confirm that:
- The workflow imports without errors.
- All nodes, connections, and settings behave as expected.
Prompting strategy for the Developer Agent
To obtain robust, production-grade workflows, prompts should be explicit and structured. Encourage requesters to specify:
- Trigger type – for example, Webhook, Schedule, Email, or another supported trigger.
- Input data sources – such as Google Sheets, external APIs, databases, or SMTP.
- Business logic – filters, transformations, branching conditions, error handling, and validation rules.
- Target actions – for example, create a ticket, send an email, update a record, or store data in a database.
Example prompt:
“Create a workflow that triggers on a webhook, validates the payload, saves rows to Google Sheets, and sends a Slack notification when amount > 1000.”
For complex automations, consider an iterative approach: start with a minimal viable workflow, then refine the prompt with additional constraints or enhancements.
Security and governance considerations
Security best practices
- Protect credentials – never embed production API keys directly in templates. Use n8n credentials or environment variables to manage secrets.
- Least privilege access – configure the n8n API credential as a service account with only the permissions required to create workflows, and avoid full administrative access where possible.
- Isolate validation – always validate generated JSON in a sandbox or staging instance before promoting workflows to production.
Operational best practices
- Use a staging pipeline – run the Developer Agent template against a staging n8n instance until you are confident in the quality of the generated workflows.
- Maintain a pattern library – curate a library of approved node patterns for authentication, error handling, logging, and observability. Reference these patterns in your documentation and prompt instructions.
- Enable detailed logging – turn on
saveManualExecutionsand extended logging while developing or tuning the Developer Tool and builder logic, so you can quickly diagnose issues.
Troubleshooting common issues
Invalid JSON from the Developer Tool
Symptom: The n8n API node fails to parse the workflow body or returns an error about invalid JSON.
Resolution:
- Confirm that the Developer Tool returns a single JSON object, not an array or text with commentary.
- Ensure the output starts with
{and ends with}. - Copy the output into a JSON linter or validator to identify syntax errors.
Workflow creation errors in the n8n API node
Symptom: The API request to create a workflow fails or returns a non-2xx response.
Resolution:
- Verify the n8n API credential, base URL, and authentication headers.
- Check that the JSON body includes all required top-level fields:
namenodesconnectionssettingsstaticData(if applicable)
- Inspect the n8n server logs for more detailed error messages.
Google Drive download or extraction failures
Symptom: The workflow cannot retrieve or parse documentation from Google Drive.
Resolution:
- Confirm the file ID or shared path in the Get n8n Docs node is correct.
- Check that the Google Drive credentials have read access to the file.
- Review conversion or export settings in the node to ensure the file is returned in a format supported by the Extract from File node.
Slow or timing out LLM responses
Symptom: Language model nodes respond slowly or hit timeouts, especially for complex prompts.
Resolution:
- Increase the timeout or “thinking” budget in the language model node configuration.
- Use a smaller or faster model for early iterations and only switch to Claude Opus 4 or similar models for final refinement.
- Simplify prompts or break large tasks into smaller, sequential steps.
Extending and customizing the template
The template is intentionally modular so teams can adapt it to their own governance, compliance, and domain-specific requirements. Common extensions include:
- Domain-specific documentation – add multiple reference documents to the Get n8n Docs node, for example:
- Finance automation standards
- HR onboarding templates
- IT operations runbooks
Use these to drive context-aware workflow generation.
- CI/CD integration – incorporate a pipeline step that runs automated tests against generated workflows before they are deployed or activated in production.
- Approval and governance flows – insert a review step that sends the generated workflow to a Slack channel, email group, or internal portal for approval before it is created or enabled in n8n.
Go-live checklist
Before enabling this template for broader use across your organization, validate the following:
- All external credentials (LLMs, n8n API, Google Drive) are configured, scoped appropriately, and tested.
- The Developer Tool consistently outputs valid, importable workflow JSON that meets your internal standards.
- End-to-end tests have been executed in a staging n8n instance, including manual imports where necessary.
- Monitoring, logging, and alerting are in place for automated workflow creations and any API errors.
Conclusion and next steps
The n8n Developer Agent template provides a powerful pattern for scaling workflow development with conversational AI, structured memory, and automated JSON generation. By combining a disciplined prompting strategy, strong security practices, and a clear staging pipeline, teams can significantly accelerate workflow delivery while maintaining control and governance.
To get started, import the template into a staging n8n instance, connect your credentials, and test it with a well-defined automation request. Iterate on the Developer Tool logic, refine your internal documentation, and then introduce approval or CI/CD gates as you move toward production usage.
If you require assistance customizing the Developer Tool, designing approval workflows, or integrating with your existing deployment processes, consider engaging a certified n8n expert or consulting the official n8n documentation for advanced patterns.