YouTube AI Agent with n8n: Automate Insights
Transform raw YouTube data into structured, decision-ready insights with an n8n-powered AI agent. This workflow template combines the YouTube Data API, OpenAI, Apify, and a Postgres-backed memory layer to automate channel analysis, video intelligence, comment mining, and thumbnail evaluation.
This guide walks through the architecture, key n8n nodes, configuration steps, and practical usage patterns so automation professionals and technical marketers can deploy a robust YouTube analysis agent in production environments.
Strategic value of a YouTube AI agent
For content teams and growth-focused organizations, YouTube is both a brand channel and a rich dataset. Manually reviewing comments, transcribing videos, and evaluating thumbnails does not scale. An n8n-based AI agent centralizes these tasks and provides:
- Audience intelligence at scale – Automatically summarize comments to identify recurring pain points, feature requests, objections, and emerging content themes.
- Content repurposing workflows – Transcribe videos to generate SEO-optimized articles, social posts, and internal knowledge assets.
- Conversion-focused creative feedback – Use AI to critique thumbnails and copy for clarity, emotional impact, and click-through potential.
- Operational efficiency – Offload repetitive API calls, pagination handling, and data preparation so teams can focus on strategy and creative direction.
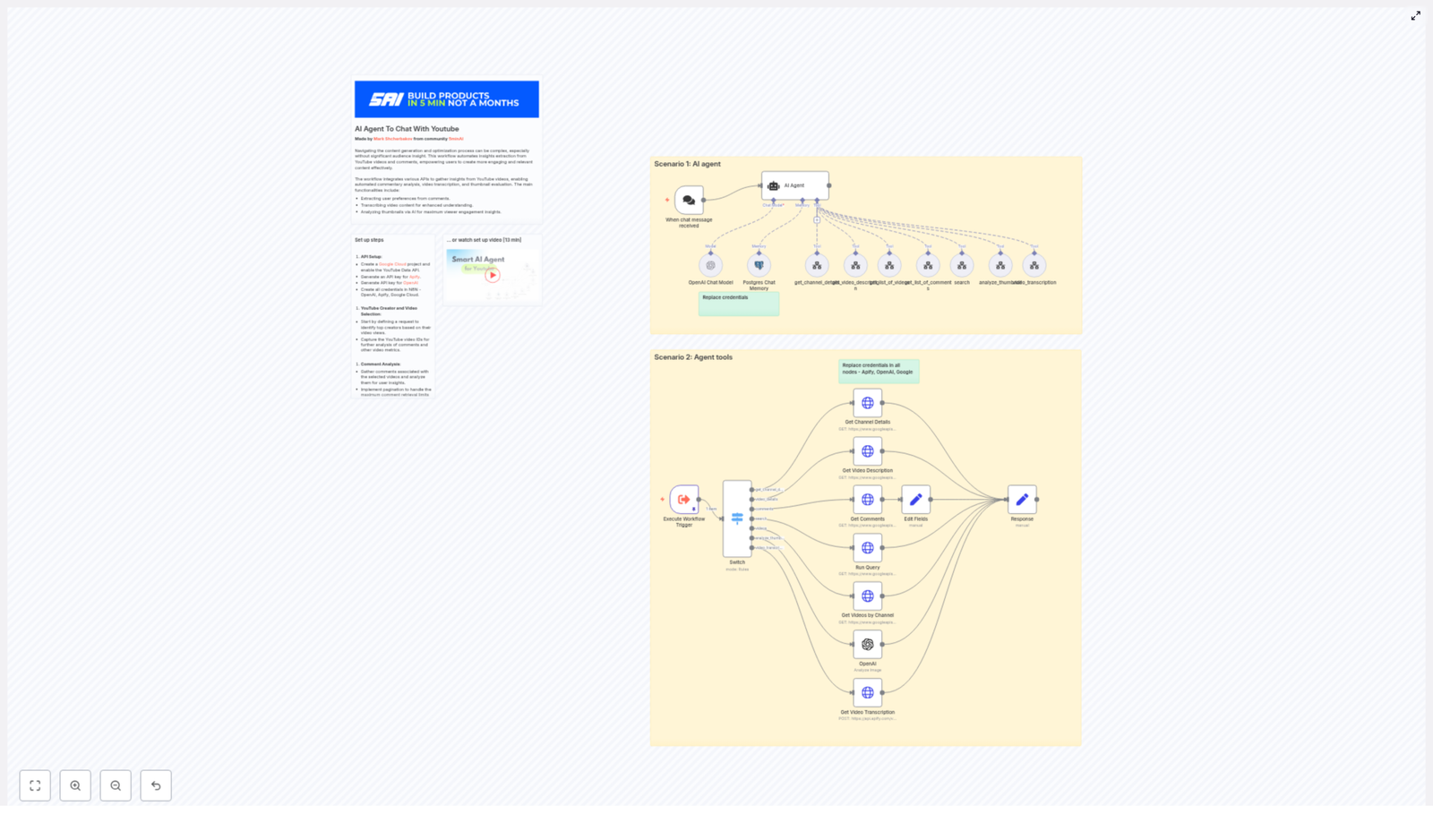
Workflow overview: two core operating modes
The template is structured around two primary scenarios that work together:
- AI Agent scenario (conversational entry point)
A chat-based trigger receives a user query such as “Analyze top videos for channel @example_handle”. The AI agent interprets intent, selects the appropriate tools, orchestrates YouTube and AI calls, and returns a synthesized answer. - Agent tools scenario (specialized helper workflows)
A set of tool workflows perform targeted operations: retrieving channel metadata, listing videos, fetching detailed video information, collecting comments, initiating transcriptions via Apify, analyzing thumbnails, and composing structured responses.
By separating orchestration logic from tool execution, the template remains modular, easier to maintain, and simple to extend with new capabilities.
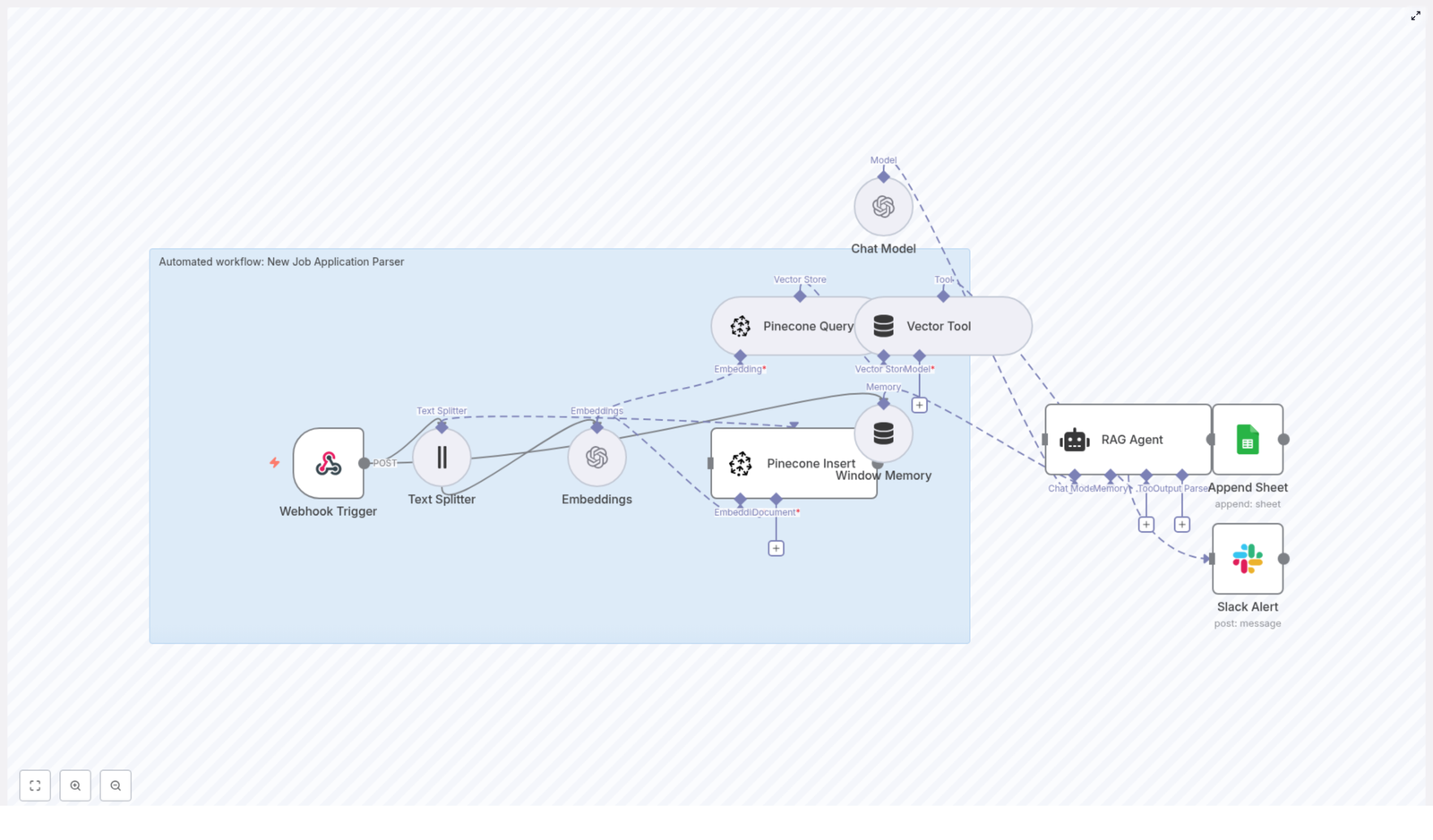
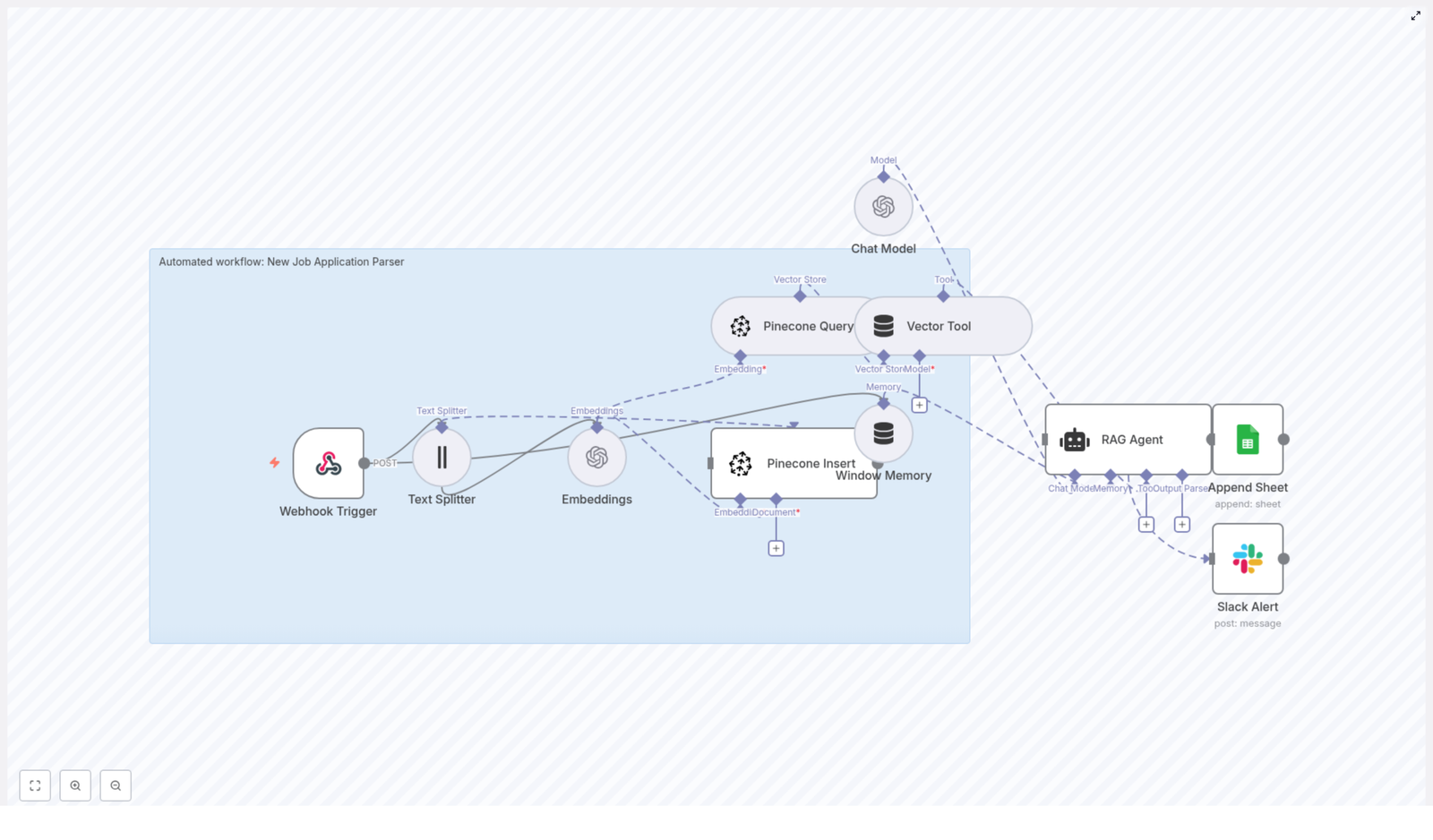
Core architecture and key n8n components
1. Chat trigger – conversational entry into the workflow
The chat trigger node acts as the primary entry point. It listens for incoming chat messages or user prompts, then forwards these inputs to the AI agent node. This design enables a natural language interface where users can request analyses using flexible phrasing instead of predefined parameters.
2. AI Agent (LangChain agent) – orchestration and reasoning
The AI agent is responsible for:
- Understanding user intent and extracting key parameters (channel handle, video URL, number of videos, analysis type).
- Selecting the right tools (helper workflows) to execute, such as channel lookup, video listing, comment analysis, or transcription.
- Planning the order of operations, for example: resolve channel, list videos, filter shorts, then analyze comments and thumbnails.
- Applying system-level rules, such as filtering out shorts under 1 minute using
contentDetails.durationor other length attributes.
A system message guides the agent to enforce constraints, maintain consistency, and protect against unnecessary or high-cost operations.
3. YouTube Data API integration nodes
The workflow uses HTTP-based nodes configured for the YouTube Data API. Typical operations include:
- Get Channel Details – Converts a channel handle or URL into a canonical
channel_id. This is the foundation for most subsequent queries. - Get List of Videos / Get Videos by Channel – Retrieves paginated video lists with support for ordering by
viewCount,date, orrelevance. The agent can request a specific number of top videos for focused analysis. - Get Video Description / Details – Fetches full video metadata, including
snippet,statistics, andcontentDetails. This data is used for performance comparisons, topic extraction, and filtering (for example, excluding shorts). - Get Comments – Collects threaded comments and replies. Pagination is essential here to capture representative audience sentiment.
4. Transcription via Apify or external service
For deeper content intelligence, the workflow can trigger a transcription service such as Apify:
- Send the video URL to Apify or another transcription provider.
- Retrieve a full text transcript once processing is complete.
- Use the transcript for topic extraction, keyword generation, summarization, and content repurposing.
Transcription is typically reserved for high-value videos due to cost and processing time. The agent can be instructed to confirm with the user or check duration before initiating this step.
5. Thumbnail analysis with OpenAI image capabilities
The workflow submits high-resolution thumbnail URLs to an OpenAI image analysis operation. A carefully designed prompt guides the model to evaluate:
- Color contrast and visual hierarchy
- Focal point clarity and subject visibility
- Text legibility at various sizes
- Emotional impact and relevance to the topic
- Call-to-action clarity and improvement suggestions
Sample prompt used in the template:
Analyze this thumbnail for: color contrast, focal point clarity, text readability, emotional impact, and suggested CTA improvements.
6. Postgres Chat Memory – persistent conversational context
A Postgres database is used as a chat memory layer so the agent can:
- Persist conversation state across multiple requests.
- Reference previous analyses or user preferences.
- Build multi-step, iterative workflows without losing context.
n8n credentials connect to Postgres, and the memory node automatically stores and retrieves relevant context for each session.
Prerequisites and configuration
Required accounts and API keys
Before importing or activating the n8n template, ensure you have:
- A Google Cloud project with the YouTube Data API enabled and an API key or OAuth credentials.
- An OpenAI API key for both language and image analysis operations.
- An Apify account and API token if you use Apify for transcription or crawler-based extraction.
- An n8n instance with credentials configured for HTTP query auth, OpenAI, Apify, and Postgres.
- A Postgres database instance for chat memory and structured output storage.
Configuring credentials inside n8n
- Create credentials in n8n for:
- OpenAI (language and image)
- Apify
- Google API HTTP Query Auth for YouTube requests
- Postgres (for memory and analytics storage)
- Open the template and replace all nodes marked as “Replace credentials” with your own credential entries.
- Individually test each HTTP request node (YouTube endpoints, Apify) using known channel IDs or video URLs to validate connectivity and permissions.
Implementation details and operational safeguards
Handling pagination and large result sets
The YouTube Data API returns limited items per request. To ensure complete coverage:
- Use
nextPageTokento iterate through pages for both video lists and comment threads. - Implement loops or a dedicated sub-workflow to aggregate results until all pages are processed or a threshold is reached.
- Consider limiting the number of items per analysis to manage latency and cost.
Filtering out shorts and irrelevant content
Many use cases focus on long-form videos. To exclude shorts or very short clips:
- Inspect
contentDetails.durationor derived video length. - Skip videos under a defined duration, for example 60 seconds, when the user requests full video analysis.
- Expose duration thresholds as configurable parameters so non-technical users can adjust behavior.
Cost control and resource management
OpenAI and transcription services can generate significant cost at scale. Recommended practices:
- Prompt the user or apply conditional logic before triggering full-length transcriptions.
- Set a maximum duration limit for automatic transcription (for example, skip videos over a certain length unless explicitly approved).
- Batch comment summarization and thumbnail reviews where possible to reduce overhead.
- Monitor provider dashboards and configure budgets or alerts.
Respecting rate limits and provider constraints
Both YouTube and OpenAI enforce rate limits and quotas. To maintain reliability:
- Implement exponential backoff or queue-based processing for large channel audits.
- Throttle concurrent requests when analyzing many videos or channels in parallel.
- Cache stable data such as channel metadata or historic statistics where appropriate.
End-to-end example: analyzing a YouTube channel
Scenario: “Analyze top videos for channel @example_handle”
- Chat trigger receives the user prompt and forwards it to the AI agent node.
- AI agent identifies that it must:
- Resolve the channel handle to a
channel_id. - Retrieve the top N videos ordered by
viewCount. - For each video, gather details, comments, and optional transcription and thumbnail analysis.
- Resolve the channel handle to a
- Channel resolution – The agent calls the get_channel_details tool to fetch the canonical
channel_id. - Video selection – The agent invokes get_list_of_videos with:
order = viewCountnumber_of_videos = 5(or another configured limit)
- Per-video analysis:
- Fetch video metadata and statistics.
- Retrieve comments and replies, handling pagination.
- Optionally trigger transcription via Apify for deeper content analysis.
- Submit the thumbnail URL to OpenAI image analysis using the defined prompt.
- Response synthesis – The agent compiles:
- Top-performing topics and patterns across the selected videos.
- Sentiment highlights and recurring themes from comments.
- Thumbnail critique and improvement suggestions.
- Ideas for repurposing content into blogs, newsletters, or social formats.
This consolidated output is returned to the user via the response node.
Comment summarization behavior
The workflow aggregates top-level comments and replies, then uses OpenAI to categorize them into buckets such as:
- Praise and positive feedback
- Feature or content requests
- Confusion, friction, or frequent questions
- Ideas and requests for future topics
This structure enables content planners and product teams to quickly identify what resonates and where viewers struggle.
Best practices for automation professionals
- Start with a limited scope – Begin by analyzing a small set of recent videos to validate accuracy, latency, and cost before scaling to entire channels or multi-channel portfolios.
- Validate inputs – Add pre-flight checks to confirm that video URLs are valid, public, and not region-restricted to avoid failing API calls.
- Keep humans in the loop – Treat AI summaries and recommendations as decision support. Final editorial and strategic decisions should remain with domain experts.
- Persist structured outputs – Store topics, sentiment scores, thumbnail assessments, and key metrics in Postgres for longitudinal tracking and dashboarding.
- Iterate on prompts – Continuously refine OpenAI prompts for thumbnail analysis and comment summarization to align with your brand guidelines and KPIs.
Representative use cases
- Content strategy teams – Identify recurring themes, knowledge gaps, and high-performing angles from viewer comments and top videos.
- Marketing and growth teams – Systematically optimize thumbnails and titles based on AI feedback for improved click-through and watch time.
- Creators and thought leaders – Convert transcripts into SEO-friendly blog posts, newsletters, or social media threads.
- Agencies and consultants – Run scalable audits on client or competitor channels to surface opportunities, content gaps, and trend insights.
Cost, privacy, and compliance considerations
Running this workflow involves paid usage across multiple providers:
- Transcription services (for example Apify)
- OpenAI language and image models
- YouTube API quotas within Google Cloud
Recommended governance practices:
- Monitor usage in each provider dashboard and enforce budgets or alerts.
- Respect YouTube terms of service when storing or distributing comments and video-derived data.
- Anonymize viewer comments if you plan to publish analyses or share datasets externally, and obtain permissions where required.
- Ensure that Postgres and n8n instances are secured according to your organization’s security standards.
Getting started with the n8n template
To operationalize this workflow in your environment:
- Open the template in your n8n workspace.
- Replace all placeholder credentials for Apify, OpenAI, Google API, and Postgres.
- Run the example search or chat trigger using a known channel handle.
- Inspect the response node output for:
- Correct channel resolution
- Accurate video selection and filtering
- Reasonable comment summaries and thumbnail feedback
- Iterate on prompts and thresholds (video count, duration limits, pagination depth) before broad deployment.
Try it now: Configure your credentials in the template, run the workflow against a channel you manage, and review the generated insights. If you need a tailored prompt set for thumbnail evaluation or comment analysis aligned with your brand and KPIs, you can extend the system and tool prompts directly within the AI agent node.