n8n + Iterable: Create, Update & Retrieve Users Reliably
A detailed, production-ready walkthrough for designing an n8n workflow that creates or upserts, updates, and retrieves users in Iterable using the native Iterable node, n8n expressions, and automation best practices.
Strategic value of integrating n8n with Iterable
Iterable is a leading customer engagement platform used to orchestrate targeted communications and manage rich user profiles. n8n is an extensible, open-source automation platform that connects APIs, services, and data pipelines through visual workflows.
Combining n8n with Iterable enables you to operationalize user lifecycle management across systems. Typical use cases include:
- Automating user creation and updates across multiple data sources
- Keeping Iterable profiles synchronized with CRM, product, or billing systems
- Fetching Iterable user data for downstream workflows such as analytics, personalization, or reporting
The workflow described below provides a minimal yet robust pattern for user upsert and verification, which you can extend into more complex customer data pipelines.
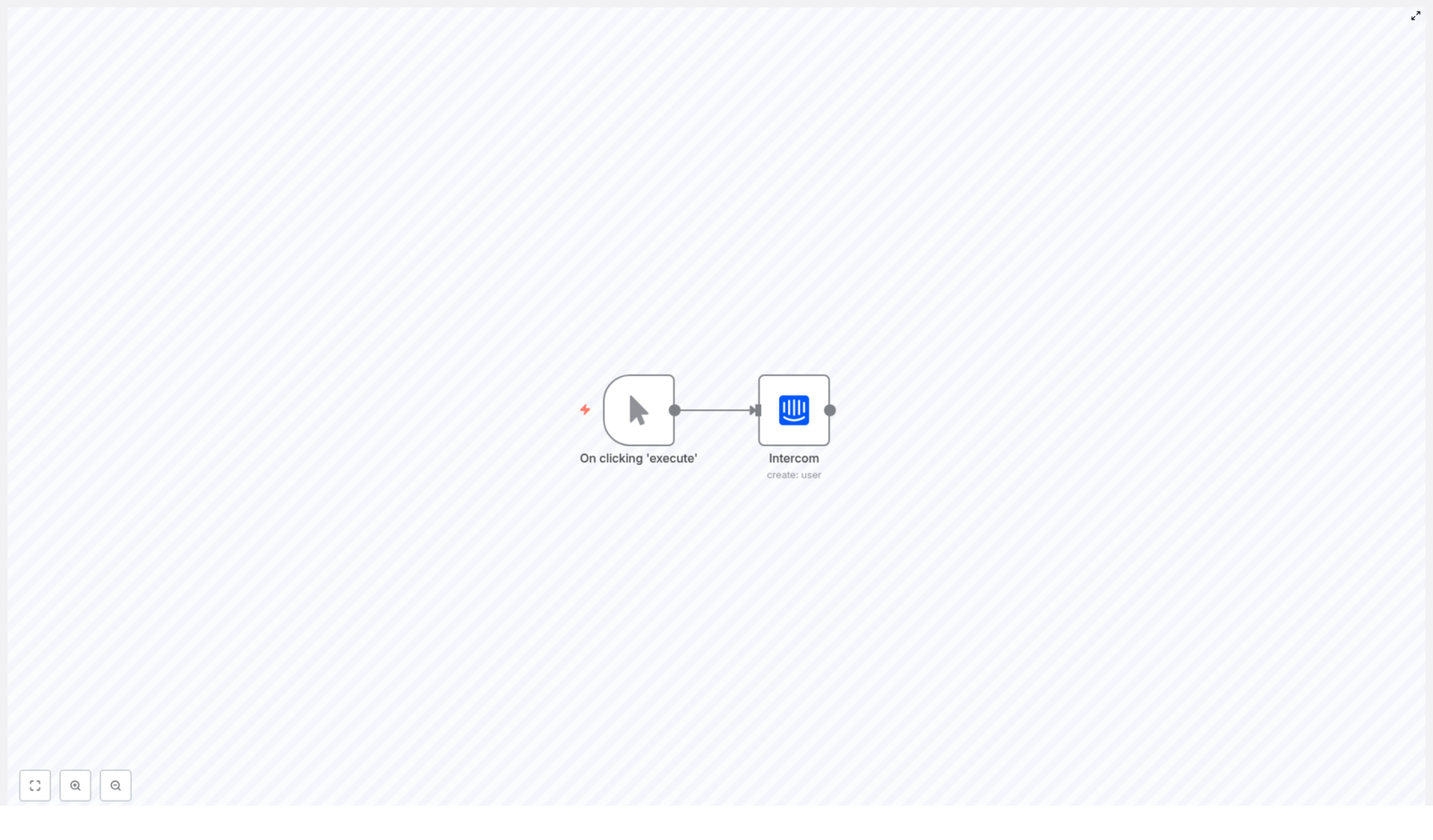
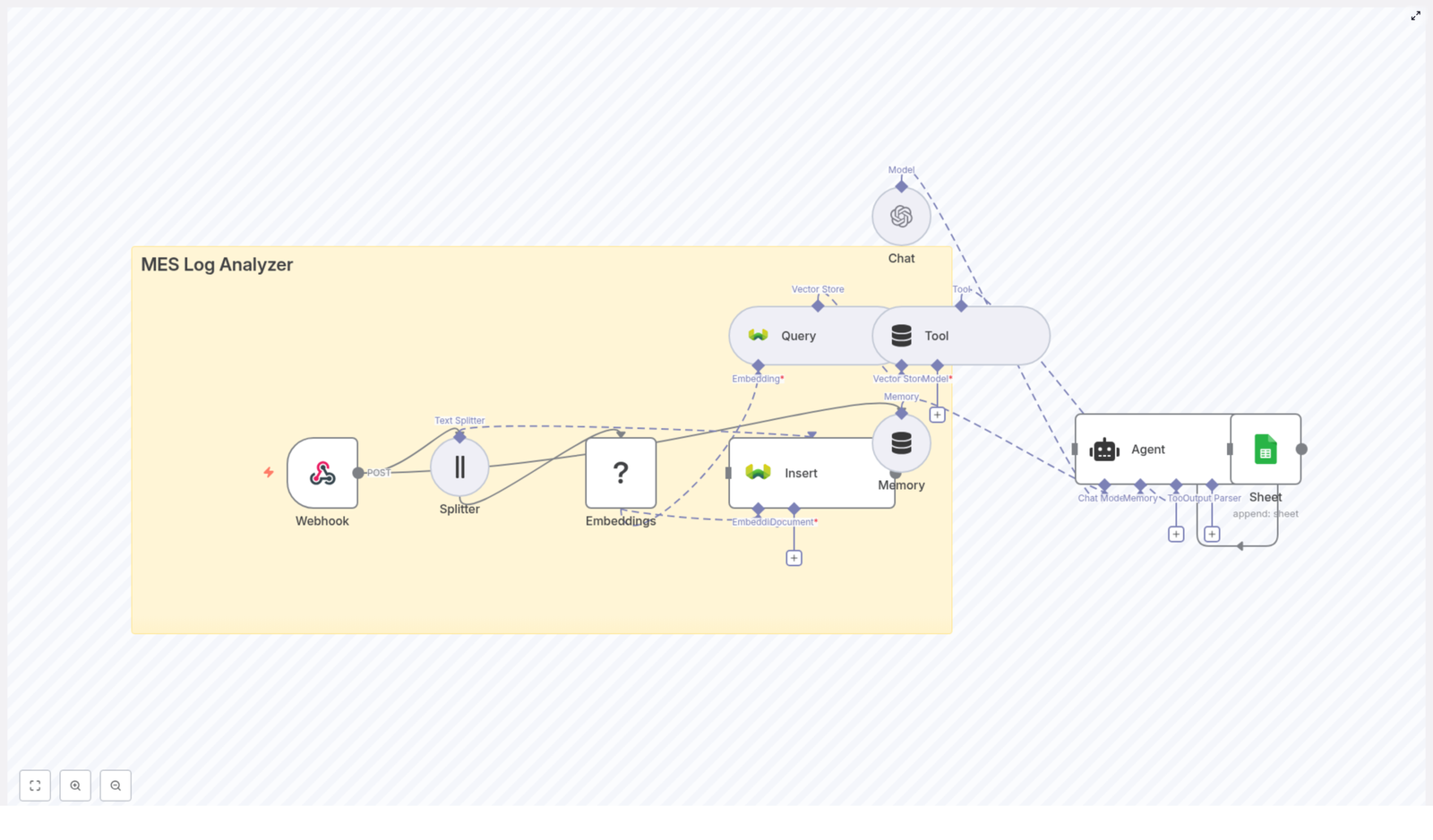
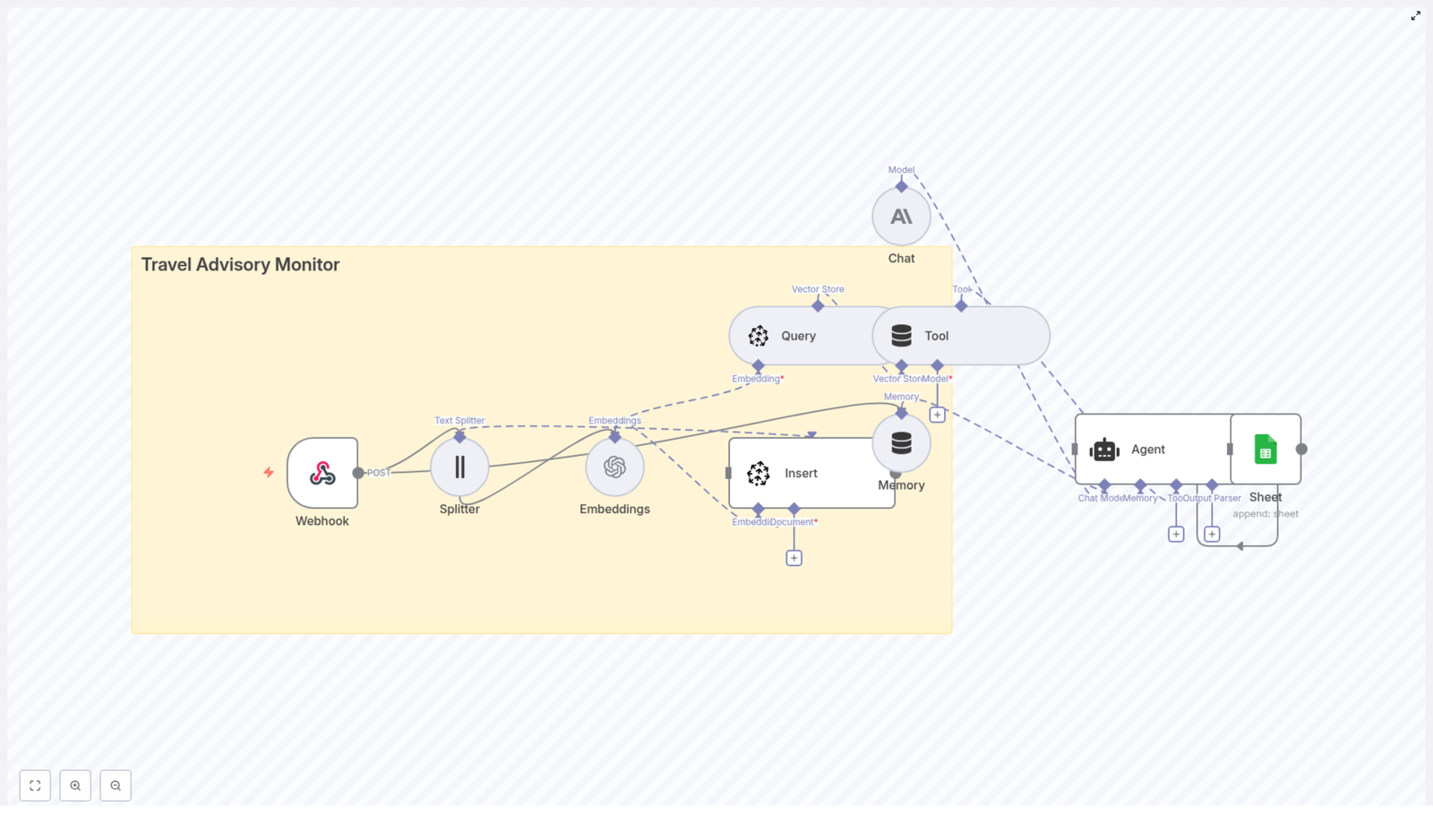
Architecture of the example n8n workflow
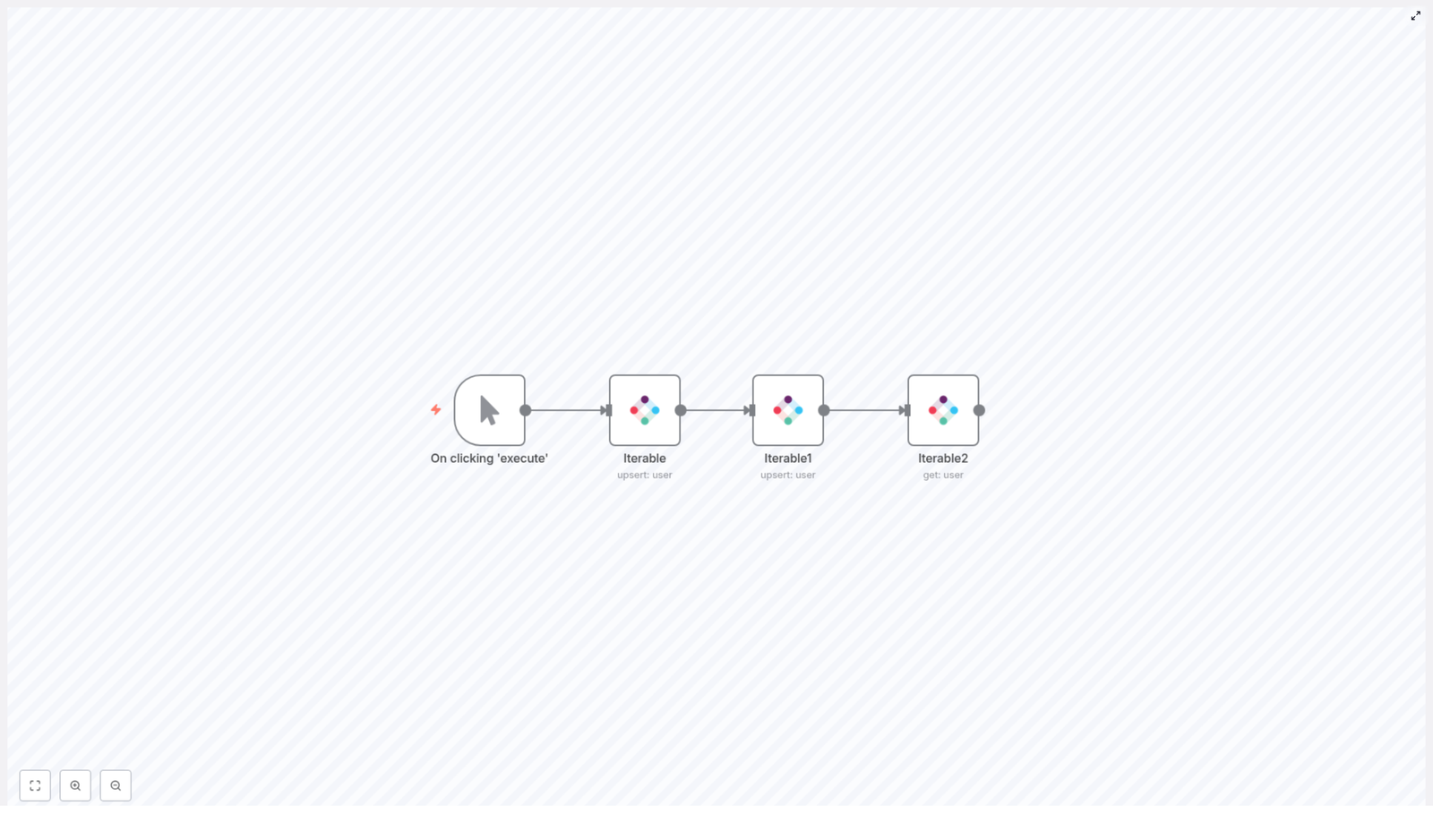
The reference workflow is intentionally linear to simplify testing and validation. It consists of:
- Manual Trigger node for interactive execution during development
- Iterable node to upsert a user using an email identifier
- Iterable1 node to perform a second upsert that enriches the profile with data fields such as Name
- Iterable2 node to retrieve the user and verify the final state
This pattern is ideal for proving your user sync logic before replacing the Manual Trigger with a production trigger such as a Webhook, Schedule Trigger, or event-based input.
Preparing n8n and Iterable for integration
Configuring Iterable credentials in n8n
Before building the workflow, configure secure access to Iterable:
- Navigate to Credentials in n8n
- Create new credentials for Iterable using your Iterable API key
- Store the key only in the credentials manager so it is not exposed in node parameters or expressions
Centralizing credentials in n8n allows multiple workflows and nodes to reuse them securely and simplifies rotation and management.
Using the Manual Trigger during development
Start with a Manual Trigger node as the entry point. This lets you execute the workflow on demand while iterating on node configuration and data mappings. Once the logic is stable, you can swap this trigger for a Webhook, Schedule Trigger, or another event source suitable for your production scenario.
Implementing the Iterable user lifecycle workflow
1. First Iterable node – core user upsert
The first Iterable node is responsible for creating or updating the user based on a primary identifier:
- Operation:
upsert(orcreatedepending on your node options and preference) - Identifier:
email - Value: the email address of the user to create or update
The value parameter can be set to a static email for testing or, in a real integration, to an expression that reads from upstream data such as a webhook payload or a database query result.
2. Second Iterable node – enriching data fields
The second Iterable node extends the profile with additional attributes. It is configured similarly to the first node but uses the additionalFields.dataFieldsUi structure to populate custom fields:
- Reuse the same email identifier and value
- Under additionalFields, configure dataFieldsUi with key-value pairs
In the provided template, this node sets a Name field under dataFields. You can expand this pattern to include properties such as plan, location, lifecycle stage, or product usage metrics.
3. Third Iterable node – retrieving the user for verification
The final Iterable node uses the get operation to retrieve the user by email. This serves multiple purposes:
- Validate that the upsert completed successfully
- Inspect the resulting profile fields and dataFields
- Expose user data to downstream nodes for logging, notifications, or further processing
By retrieving the user at the end of the workflow, you can assert expected behavior and quickly diagnose configuration issues during development.
Using n8n expressions to link Iterable nodes
n8n expressions are central to building dynamic, maintainable workflows. In this template, the second and third Iterable nodes reuse the email address configured in the first Iterable node by referencing its parameter via an expression.
The key expression is:
= {{$node["Iterable"].parameter["value"]}}This expression reads the value parameter from the node named Iterable and injects it into subsequent nodes. This approach ensures that changes to the email source only need to be made in one place and reduces the risk of configuration drift.
You can apply the same pattern for other dynamic values such as user IDs, timestamps, or payload attributes. Referencing upstream nodes through expressions is a core best practice when designing n8n workflows at scale.
Managing custom profile attributes with dataFields
Iterable stores custom user attributes under the dataFields object. In n8n, these can be configured directly in the Iterable node through the dataFieldsUi interface under additionalFields.
Key considerations when working with dataFields:
- Field keys must align exactly with the configuration in your Iterable project
- Keys are case-sensitive, so
Nameandnameare treated as different fields - Values can be static or built with expressions from previous nodes
Example configuration for a Name field:
- Key:
Name - Value:
{{$json["firstName"]}} {{$json["lastName"]}}
In this example, the Name field is composed from firstName and lastName attributes provided by an upstream node such as a webhook or database query.
Error handling, validation, and resilience
Any integration with an external API such as Iterable must be designed with failure modes in mind. To increase reliability and observability, consider integrating the following patterns into your n8n workflows:
- Input validation Validate email addresses before calling Iterable, for example with a Function node or a regular expression check.
- Conditional branching Use an IF node to verify that required fields such as email are present. If data is incomplete, skip API calls or route to a remediation path.
- Error workflows Use n8n’s error workflow capability or an Execute Workflow node in a try or catch pattern to centralize error handling.
- Logging and monitoring Persist API responses and errors to a database, logging service, or monitoring channel so failed operations can be inspected and replayed.
- Rate limit management Respect Iterable’s rate limits by introducing small delays, queues, or batch processing when handling high-volume syncs.
Building these practices into your initial design significantly reduces operational overhead once the workflow is promoted to production.
Alternative implementation using the HTTP Request node
While the native Iterable node covers common operations, some teams prefer direct control over the HTTP layer. In such cases, you can use the HTTP Request node to call Iterable’s REST API endpoints directly.
Relevant endpoints include:
- Upsert user:
POST https://api.iterable.com/api/users/update - Get user by email:
POST https://api.iterable.com/api/users/getByEmail
When using the HTTP Request node, ensure that:
- The x-api-key header is set to your Iterable API key
- The request body conforms to Iterable’s API specification
Example JSON body for an update request:
{ "email": "user@example.com", "dataFields": { "Name": "Jane Doe" }
}This approach is useful if you require access to newer API capabilities, advanced options not yet exposed in the native node, or highly customized request behavior.
Best practices for Iterable user workflows in n8n
- Prefer upsert for idempotency Use the upsert operation to ensure that repeated calls with the same identifier are safe and deterministic.
- Centralize and protect credentials Store API keys in n8n credentials, not directly in node parameters or expressions.
- Normalize and sanitize inputs Trim whitespace, normalize email case, and standardize formats before sending data to Iterable.
- Use descriptive node names and annotations Name nodes meaningfully and add notes where logic is non-obvious to simplify future maintenance.
- Develop with Manual Trigger, then move to production triggers Iterate quickly using the Manual Trigger, then replace it with a Webhook, Schedule Trigger, or other event source once the workflow is stable.
Troubleshooting common Iterable integration issues
If the workflow does not behave as expected, use the following checklist to narrow down the root cause:
- 401 / 403 responses Confirm that the API key is valid, correctly configured in n8n credentials, and has the necessary permissions in Iterable.
- 400 responses Inspect the request payload structure and required fields. Ensure that types and field names match Iterable’s API specification.
- Empty response from get operation Verify that the email used in the get call exactly matches the email stored in Iterable, including case and any whitespace.
- Rate limit or throttling errors Introduce retries with backoff, delays between requests, or batch processing strategies to reduce API pressure.
Working with the provided n8n template
The shared JSON template is structured around three Iterable nodes that operate on a common email identifier. To adapt it to your environment:
- Set the value parameter of the first
Iterablenode to the target email address, either statically or via expression from upstream data. - Allow the second
Iterable1node to copy the email using the expression= {{$node["Iterable"].parameter["value"]}}and configure the Name data field or any other attributes you need. - Use the
Iterable2node, which relies on the same expression, to fetch the user by email and confirm that the profile reflects the intended updates.
Once you are satisfied with the behavior in a test environment, replace the Manual Trigger with your production trigger, such as a Webhook that listens to user events or a schedule that processes batch updates. From there, you can connect additional downstream steps such as sending Slack notifications, writing audit records to a database, or triggering follow-up workflows.