Battery Health Monitor with n8n & LangChain: Turn Raw Telemetry into Action
Imagine never having to manually sift through battery logs again, and instead having a smart, automated system that watches your fleet, learns from history, and surfaces the right insights at the right time. That is exactly what this n8n workflow template helps you build.
In this guide you will walk through a practical journey: starting from the challenge of messy battery telemetry, shifting into what is possible with automation, then implementing a concrete n8n workflow that uses LangChain components, Hugging Face embeddings, a Redis vector store, and Google Sheets logging. By the end, you will have a reusable Battery Health Monitor that not only saves time, but becomes a building block for a more automated, focused way of working.
The problem: Telemetry without insight
Battery-powered devices constantly generate data: voltage, temperature, cycles, warnings, and long diagnostic notes. On its own, this telemetry is noisy and difficult to interpret. You might:
- Scroll through endless logs looking for patterns.
- Miss early warning signs of degradation or overheating.
- Spend hours manually correlating current issues with past incidents.
This manual approach does not scale. It slows you down, eats into time you could spend improving your product, and makes it harder to respond quickly when something goes wrong.
The mindset shift: From manual checks to automated intelligence
Instead of reacting to issues one by one, you can design a system that observes, remembers, and recommends. With n8n and modern AI tooling, you can:
- Turn incoming battery telemetry into structured, searchable knowledge.
- Automatically compare new events against historical patterns.
- Use an AI agent to suggest actions and log decisions for future audits.
This is not about replacing your expertise. It is about multiplying it. When you let automation handle repetitive analysis, you free yourself to focus on strategy, product quality, and scaling your operations.
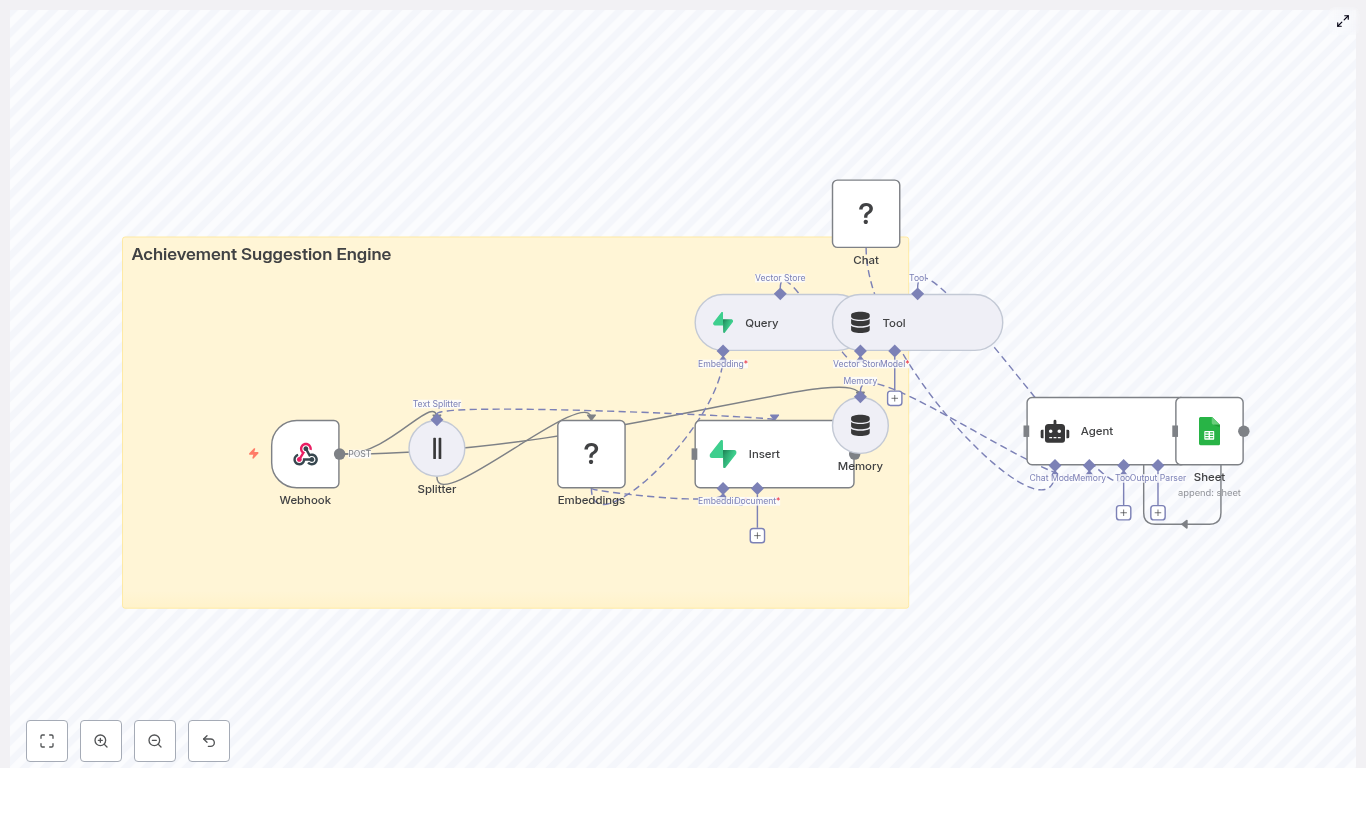
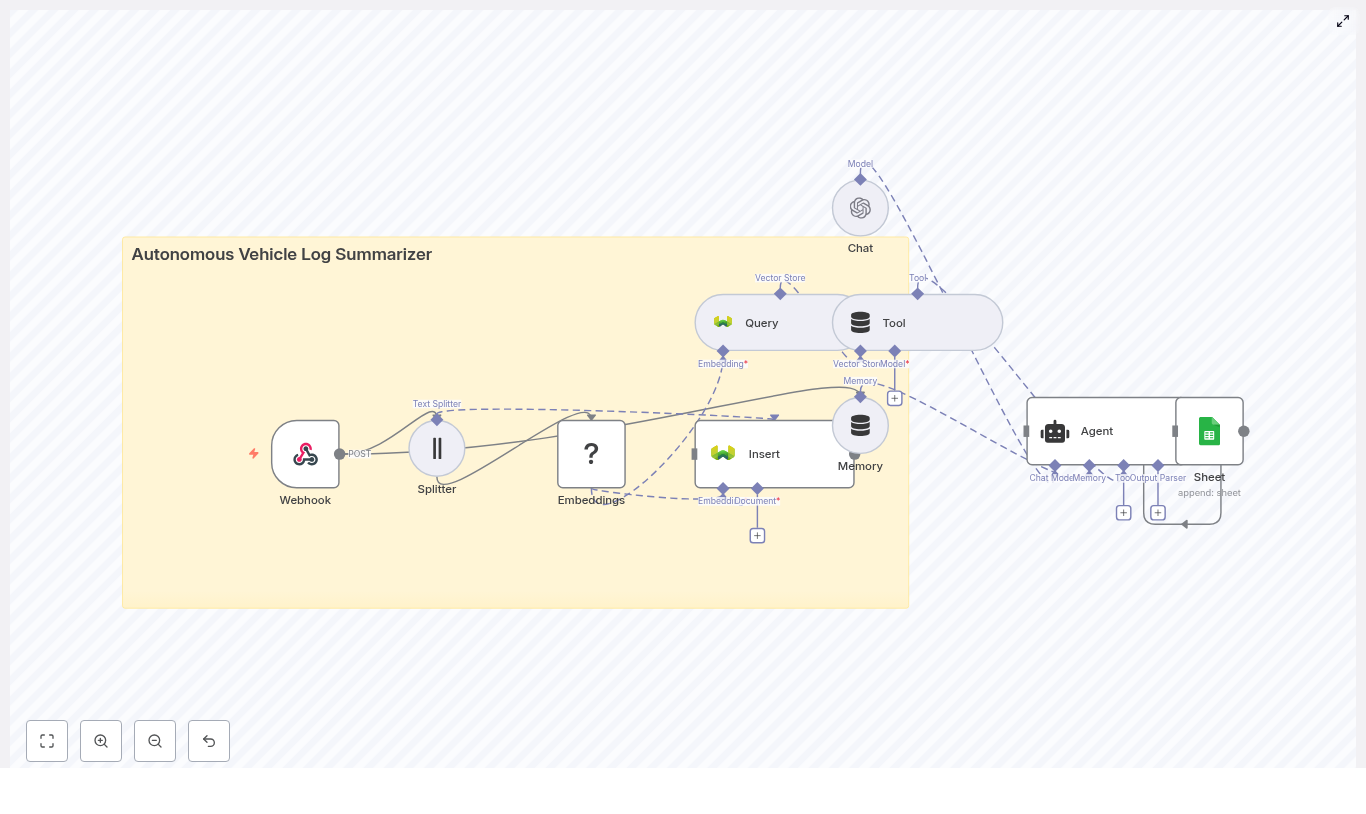
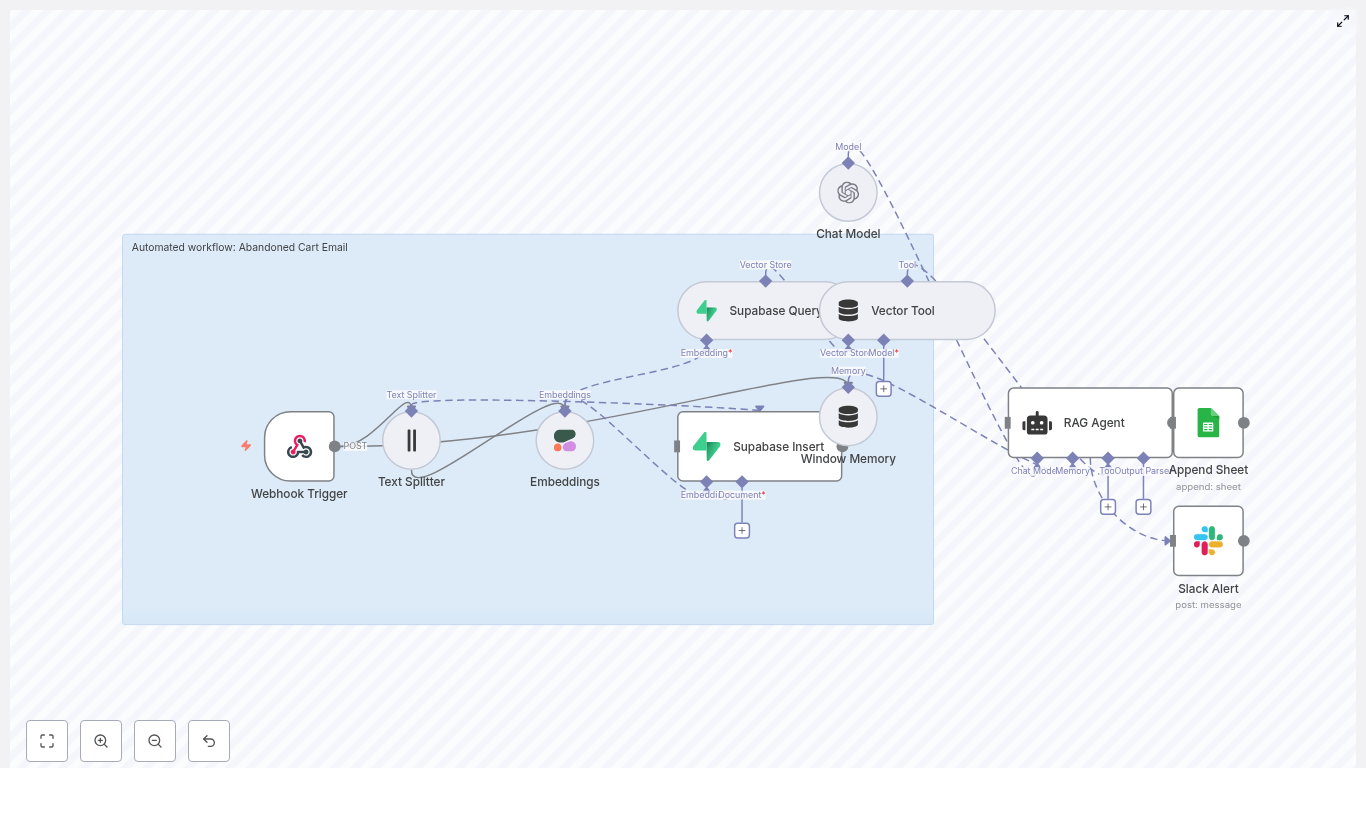
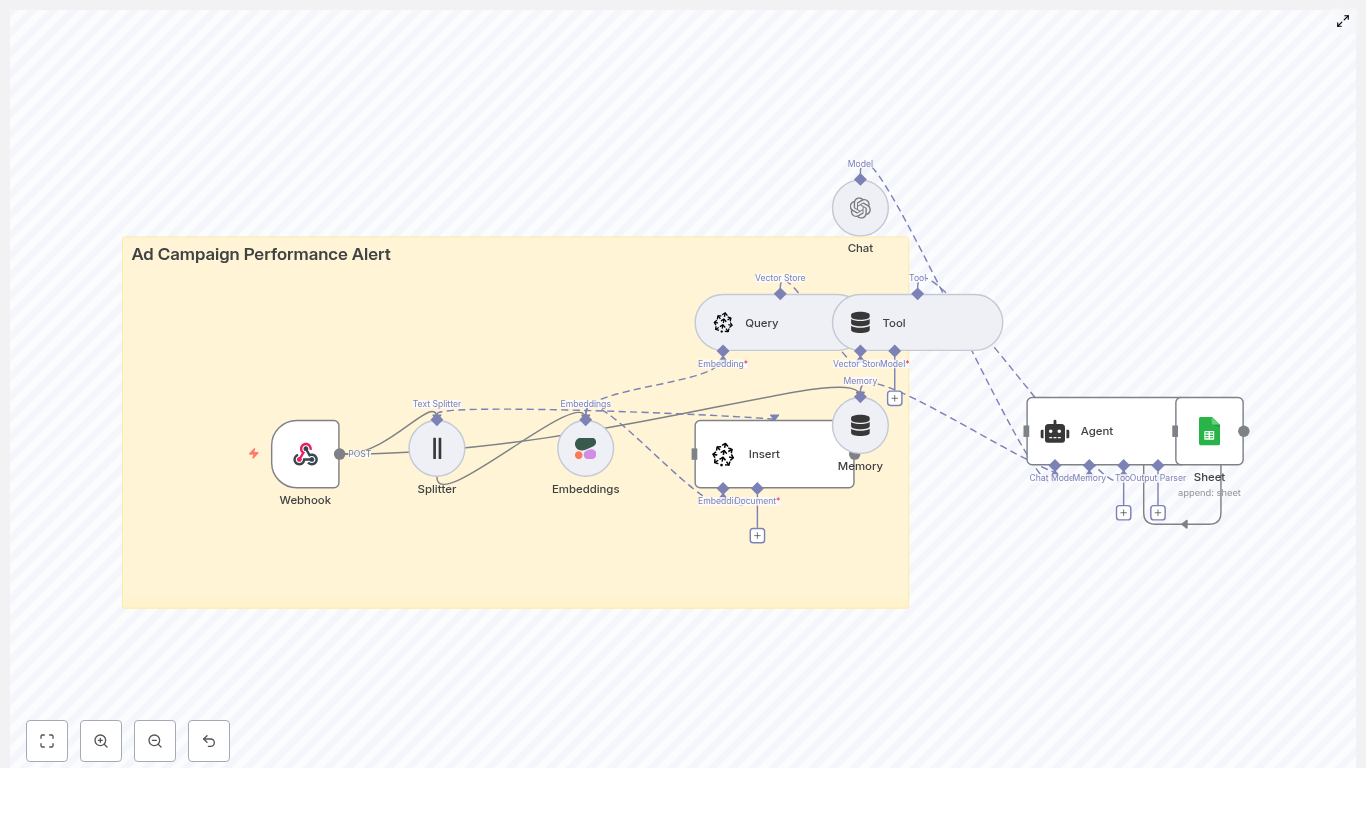
The architecture: Building blocks for a smarter battery monitor
The Battery Health Monitor workflow combines a set of powerful components that work together as a cohesive system:
- n8n for low-code orchestration, routing, and Webhook endpoints.
- Text splitter & embeddings to convert long diagnostic notes into compact vector embeddings.
- Redis vector store as a fast, persistent similarity search index.
- Memory + Agent for contextual reasoning over current and past telemetry.
- Google Sheets for a simple, auditable log of alerts and recommendations.
Each piece is modular and replaceable, so you can start simple and evolve the workflow as your fleet grows or your needs change.
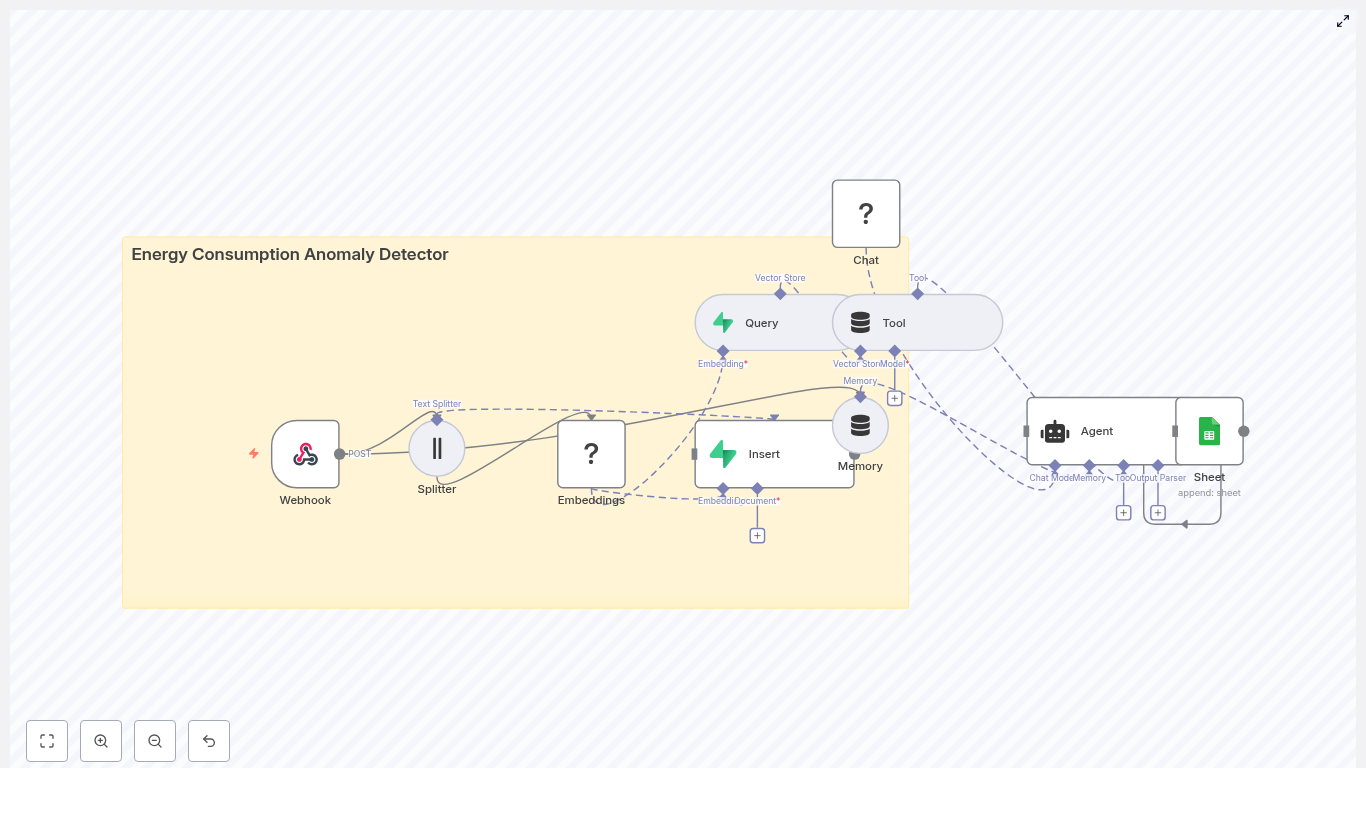
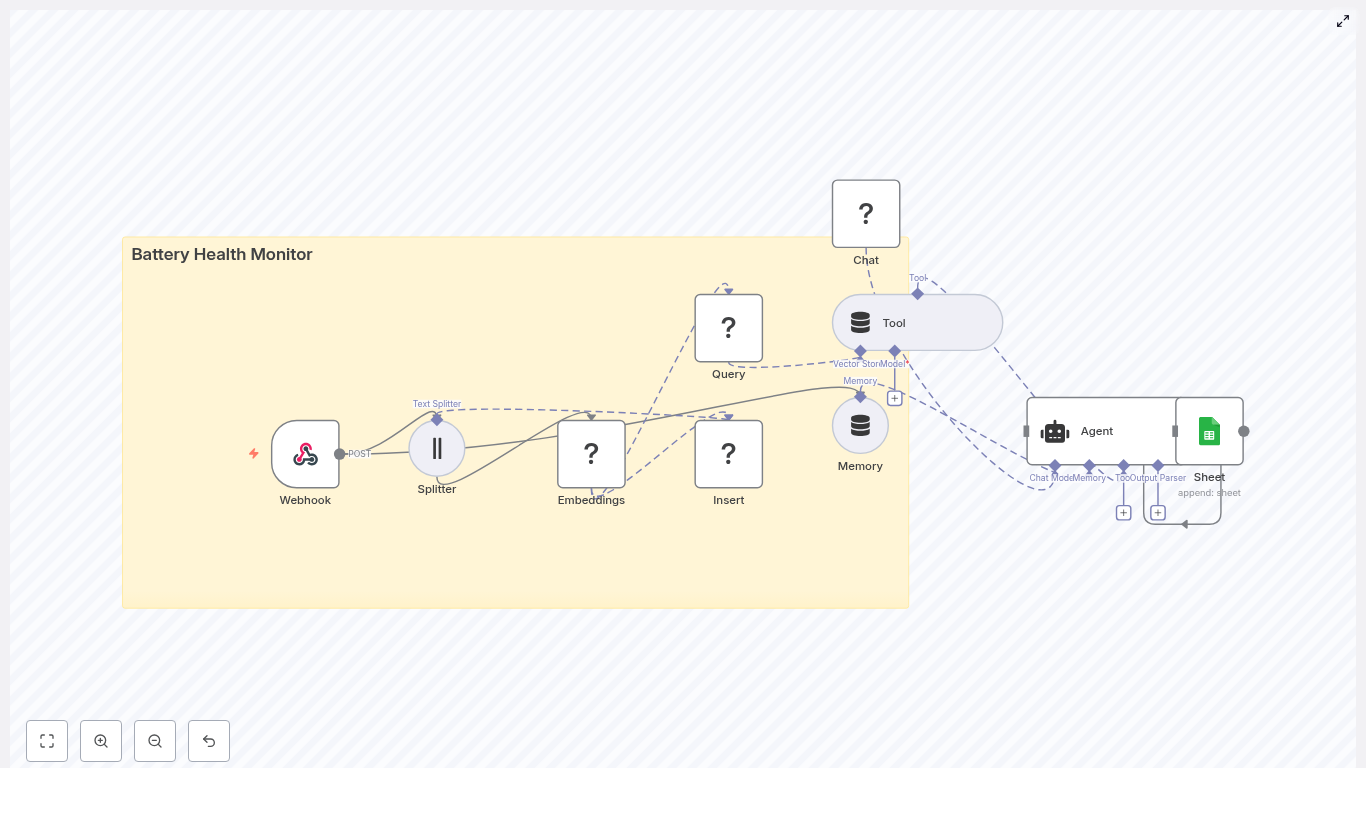
How the n8n workflow works end-to-end
At a high level, the workflow follows this flow inside n8n:
- A Webhook receives POST telemetry from your devices.
- A Text Splitter breaks long notes or logs into overlapping chunks.
- An Embeddings node (Hugging Face) converts each chunk into a numeric vector.
- An Insert node stores those vectors in a Redis index named
battery_health_monitor. - A Query node searches Redis for similar historical events.
- A Tool node exposes this vector search as a tool to the Agent.
- A Memory node keeps recent context for the Agent.
- A Chat (LM) node and Agent use memory and tools to produce recommendations.
- A Google Sheets node appends all key details into a sheet for tracking and auditing.
What you get is a loop that continuously learns from your data, references the past, and records its own decisions. It is a small but powerful step toward an automated observability layer for your batteries.
Step-by-step: Build your Battery Health Monitor in n8n
Now let us turn this architecture into a working n8n workflow. Follow the steps below, then iterate and improve once you have it running.
1. Create the Webhook endpoint
Start by creating the entry point for your telemetry.
- Add a Webhook node in n8n.
- Set the HTTP method to POST.
- Set the path to
/battery_health_monitor.
This Webhook will receive JSON payloads containing battery metrics such as voltage, temperature, cycle count, and health flags. It becomes the front door for all your battery data.
2. Split long notes with a Text Splitter
Diagnostic notes and logs can be long and unstructured. Before embedding them, you want to break them into manageable pieces while preserving context.
- Attach a Text Splitter node to the Webhook.
- Use character-based splitting.
- Configure:
chunkSize: 400chunkOverlap: 40
This configuration helps the embedding model handle longer messages while still keeping enough overlap so that important context is not lost between chunks.
3. Generate embeddings with Hugging Face
Next, you convert each text chunk into a vector so you can perform similarity search later.
- Add an Embeddings node in n8n.
- Select the Hugging Face provider and enter your API credentials.
- Choose an embedding model compatible with your account and set the
modelparameter accordingly.
The node transforms each chunk into a numeric vector representation that captures semantic meaning. These vectors are the foundation for finding similar historical events.
4. Store vectors in a Redis vector index
Now you need a fast, persistent place to store and query your embeddings.
- Add a Redis vector store node.
- Configure your Redis connection (host, port, authentication).
- Set the mode to insert.
- Use an index name such as
battery_health_monitor.
Once configured, each new telemetry event will contribute its embeddings to the Redis index, gradually building a searchable knowledge base of your battery history.
5. Query the vector store for similar patterns
To make your agent context aware, you need to retrieve relevant historical chunks when new telemetry arrives.
- Add a Query node connected to the Redis vector store.
- Configure it to perform similarity searches against the
battery_health_monitorindex.
During workflow execution, this node returns the most relevant chunks for the current telemetry, such as similar failures, temperature spikes, or lifetime patterns. These results become evidence the Agent can reference when making recommendations.
6. Combine Agent, Memory, Tool, and Chat
This is where your workflow becomes more than a data pipeline. It becomes an intelligent assistant for your battery fleet.
- Tool node – Wrap the Redis similarity query as a tool that the Agent can call when it needs historical context.
- Memory node – Add a memory buffer to store recent interactions and outputs. Configure the memory window so the Agent can recall the latest context without being overwhelmed.
- Chat (LM) node – Use a Hugging Face-hosted language model to generate human readable insights and recommendations.
- Agent node – Connect the model, memory, and tool. The Agent orchestrates when to query Redis, how to interpret the results, and what to output, such as alerts, root cause hints, or structured data for logging.
With clear prompts and the right tools, the Agent can say things like: “This looks similar to previous voltage sag incidents on devices with high cycle counts. Recommended action: schedule preventive maintenance.”
7. Log everything in Google Sheets
To make your system auditable and easy to review, you can log each decision in a simple spreadsheet.
- Add a Google Sheets node.
- Configure it to append rows to a sheet named
Log. - Map fields from the Agent output, including:
- Device ID
- Timestamp
- Health score or state of health
- Recommended action or alert level
- Context links or references to similar historical events
Over time this sheet becomes a structured history of your fleet health, decisions, and outcomes, which is invaluable for audits, tuning, and continuous improvement.
Example telemetry payload
Here is a sample JSON payload you can use to test your Webhook and workflow:
{ "device_id": "BAT-1001", "timestamp": "2025-08-31T12:34:56Z", "voltage": 3.7, "temperature": 42.1, "cycle_count": 450, "state_of_health": 78, "notes": "Voltage sag observed during peak draw. Temperature spikes when charging."
}
Send a payload like this to your /battery_health_monitor endpoint and watch how the workflow ingests, stores, analyzes, and logs the event.
Best practices to get real value from this template
Once your Battery Health Monitor is running, the next step is tuning. Small adjustments can significantly improve the quality of your insights and the reliability of your automation.
Choosing the right embedding model
Select an embedding model that balances cost and quality. For technical telemetry and diagnostic text, models trained on technical or domain specific language often yield better similarity results. Experiment with a couple of options and compare how well they cluster similar incidents.
Optimizing chunk size and overlap
The Text Splitter configuration has a direct impact on embedding quality.
- If chunks are too small, you lose context and the model may miss important relationships.
- If chunks are too large, you might hit model limits or reduce similarity precision.
Use the default chunkSize: 400 and chunkOverlap: 40 as a starting point, then adjust based on your average log length and the richness of your notes.
Configuring Redis for accurate search
Redis is the engine behind your similarity search, so it needs to be aligned with your embeddings.
- Ensure the index dimension matches the embedding vector size.
- Choose an appropriate distance metric (for example cosine) based on the embedding model.
- Store metadata such as
device_idandtimestampso you can filter queries by device, time range, or other attributes.
With good indexing, your Agent will retrieve more relevant context and make more confident recommendations.
Designing safe and effective Agent prompts
The Agent is powerful, but it needs clear boundaries.
- Use system level instructions that define the Agent’s role, such as “act as a battery health analyst.”
- Ask it to only make strong recommendations when the retrieved evidence is sufficient.
- Require it to reference similar historical cases from the vector store whenever possible.
This reduces hallucinations and keeps your outputs grounded in actual data.
Security and scalability as you grow
As your workflow becomes more central to operations, it is important to treat it like production infrastructure.
- Protect your Webhook with API keys or signature verification.
- Use HTTPS for secure transport and, where possible, request signing.
- Run Redis in a managed, private network with encryption in transit.
- Limit access to language models and monitor usage for cost control.
- Scale out n8n workers and add rate limiting as your device fleet grows.
These steps help ensure your automated battery monitoring remains reliable and secure as you lean on it more heavily.
Turn insights into action with alerts and monitoring
Once your workflow is making recommendations, the next step is to act on them automatically when needed.
- Trigger emails or push notifications via n8n’s email, Slack, or push nodes when the Agent flags critical conditions, such as thermal runaway risk or sudden health drops.
- Append high priority events to a dedicated Google Sheet or database table for escalation.
- Send metrics to Prometheus or Datadog to track trends and performance over time.
This transforms your Battery Health Monitor from a passive reporting tool into an active guardian for your fleet.
Where this template fits: Real-world use cases
This n8n workflow template is flexible enough to support many scenarios, including:
- Monitoring battery health for EVs, scooters, or drone fleets.
- Tracking industrial UPS and backup power systems for early warning signals.
- Managing consumer device fleets for warranty analysis and predictive maintenance.
Use it as a starting point, then adapt it to the specific metrics, thresholds, and business rules that matter to you.
Troubleshooting and continuous improvement
As with any automation, you will learn the most by running it in the real world and iterating. Here are common issues and how to address them:
- Empty or poor search results: Check that your embedding model is compatible with the Redis index configuration and that the index dimensions match the vector size.
- Vague or unhelpful Agent responses: Tighten the Agent prompt, provide clearer instructions, improve memory configuration, and ensure the Tool node returns enough evidence.
- Redis insertion errors: Verify credentials, network connectivity, and that the index exists or is created with the correct settings.
Each fix moves you toward a more reliable and powerful monitoring system.
Your next step: Use this template as a launchpad
This Battery Health Monitor pattern gives you a practical, scalable way to add context aware analysis and automated decision logging using n8n, LangChain primitives, Redis, and Hugging Face embeddings. It is fast to deploy, easy to audit via Google Sheets, and designed to be extended with more tools, alerts, and integrations as your needs grow.
Most importantly, it is a stepping stone. Once you see how this workflow transforms raw telemetry into useful action, you will start to notice other processes you can automate and improve with n8n.
Take action now:
- Deploy the n8n workflow template.
- Plug in your Hugging Face, Redis, and Google Sheets credentials.
- Send a sample payload to
/battery_health_monitorwithin the next 30 minutes.
Use that first run as a learning moment. Tweak the text splitter, try a different embedding model, or refine the Agent prompt. Each small improvement moves you closer to a robust, AI powered monitoring system that works for you around the clock.