
Automate Your AI Newsletter with n8n (Step-by-Step)
What you will learn
In this guide, you will learn how to use an n8n workflow template to automate an AI-focused newsletter from raw content to a ready-to-publish markdown file. By the end, you should understand:
- Why automating your AI newsletter is useful for teams and solo creators
- The core building blocks of the n8n workflow (nodes, integrations, and stages)
- How the workflow ingests markdown and tweets, filters them, and selects top stories with LLMs
- How each newsletter section is written, assembled, and reviewed before publication
- How to adapt the template, keep it robust, and extend it with your own tools
Why automate an AI newsletter?
Producing a consistent, high-quality AI newsletter takes time. You need to collect links, read articles, write summaries, and format everything. An automated n8n workflow can handle much of this repetitive work so you can focus on editorial judgment and tone.
Key benefits of newsletter automation include:
- Faster turnaround – daily or weekly editions can be drafted in minutes instead of hours.
- Consistent structure – sections like the intro, deep dive, and shortlist follow the same pattern every time.
- Better signal extraction – LLM-assisted curation helps surface the most relevant AI stories from a larger content pool.
The workflow template described here uses n8n, LLMs via LangChain-style nodes, and S3/R2 cloud storage to build a production-ready pipeline with human review steps.
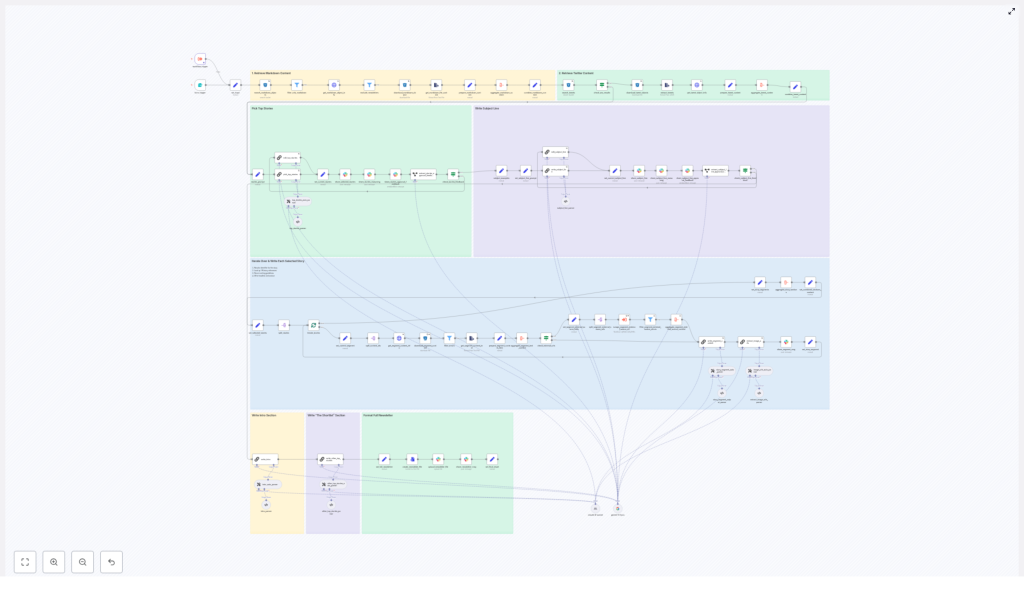
How the n8n newsletter workflow is structured
At a high level, the workflow moves through five major stages:
- Data ingestion – collect markdown and tweet content from cloud storage.
- Pre-filtering – keep only relevant and recent content for the current edition.
- Curation with LLMs – select the top stories and propose subject lines.
- Content assembly – write each section of the newsletter using LLMs and collected sources.
- Review and publishing – send drafts and subject lines to Slack for approval and then output the final markdown file.
The rest of this guide walks through each stage in a teaching-friendly, step-by-step way so you can understand how the template works and how to adapt it.
Step 1 – Ingest content into the workflow
Storage and retrieval in n8n
The workflow starts by gathering all candidate items for the next newsletter edition. It uses storage and HTTP nodes to pull in content:
- S3/R2 nodes
- Search for markdown and tweet objects using a date-based prefix (for example, today’s date).
- Download files that match the pattern so they can be processed further.
- HTTP Request nodes
- Fetch extra metadata about files when needed.
- Call external APIs to retrieve information about sources or linked content.
By the end of this step, the workflow has a collection of markdown documents and tweet data representing potential stories for your AI newsletter.
Step 2 – Filter and prepare the raw content
Parsing and aggregation
Once the files are downloaded, they need to be converted into a format that LLMs and downstream nodes can understand. This is handled through parsing and aggregation nodes:
- extractFromFile nodes
- Convert stored files into plain text.
- Make it possible to parse the content without worrying about file formats.
- aggregate and split nodes
- Bundle related pieces of content together, such as multiple tweets or multiple markdown notes on the same topic.
- Later split these bundles to iterate over individual story identifiers or URLs.
Filtering out noise
Not all content in storage should go into today’s newsletter. This is where workflow control nodes come in:
- Filter and If nodes
- Exclude irrelevant file types.
- Skip newsletters from older dates and keep only content that matches the current edition (for example, today or a small recency window).
- Gate branches based on conditions like missing fields or invalid formats.
- SplitInBatches / SplitOut
- Process large numbers of candidate stories in smaller batches.
- Prevent memory issues when handling many items at once.
After this step, you have a clean set of potential stories, ready for LLM-based curation.
Step 3 – Curate top stories with LLMs
How the curation stage works
The curation stage is the heart of the workflow. It uses LLM prompts to decide which stories are most important and how they should appear in the newsletter.
The workflow:
- Aggregates all candidate items
- Combines web markdown files and tweet content into a single pool for the current edition.
- Runs a story-selection prompt
- Uses a LangChain-style node (often called
chainLlm) to send a carefully written prompt to the LLM. - Asks the model to rank and select the top four stories, with the first one designated as the lead story.
- Uses a LangChain-style node (often called
- Generates structured JSON output
- The LLM returns a JSON object that contains titles, summaries, identifiers, and external source links for the chosen stories.
- Structured output parsers validate that each field is present and correctly formatted.
- Sends selections to Slack for approval
- The workflow posts the chosen stories to a Slack channel.
- Editors can review the picks, provide feedback, or request changes before the writing stage proceeds.
LLM and model configuration
The template supports multiple LLM providers so you can balance cost and quality:
- LangChain-style nodes (chainLlm)
- Run prompts for story selection, rewriting, and subject line creation.
- Multiple model support
- Nodes are available for models like Gemini, Claude, or other Anthropic models.
- You can swap models depending on your budget and the level of detail you want.
- Structured output parsers
- Force the LLM to return a predictable JSON schema, for example:
titlesummaryidentifiersource_url
- Downstream nodes can then rely on these fields without fragile text parsing.
- Force the LLM to return a predictable JSON schema, for example:
Step 4 – Write each newsletter section
Resolving content for each selected story
Once the top four stories are approved in Slack, the workflow moves into a loop that processes each story one by one. For every selected story, n8n does the following:
- Resolve identifiers to content
- Use identifiers returned by the LLM to locate the original markdown or tweet content in S3/R2.
- Download the associated text from storage.
- Fetch external sources
- When a story includes an external URL, the workflow may use HTTP nodes or scraping logic to fetch that page’s text.
- Aggregate references and media
- Combine all relevant snippets and references for a story.
- Extract images if they are available and needed for the newsletter format.
Generating the story segments with LLMs
After all references are collected for a single story, the workflow calls the LLM again with a tightly scoped prompt. This prompt is responsible for producing a complete newsletter segment, often structured into parts, such as:
- The Recap – a concise summary of the story.
- Unpacked bullets – key insights, implications, or technical details in bullet form.
- Bottom line – a short editorial takeaway or why this story matters.
The LLM returns the segment in markdown format. The workflow then:
- Saves the markdown for each story as its own section.
- Collects all sections into a single structure that will later form the full newsletter.
Step 5 – Intro, subject line, and metadata
Creating the intro and subject lines
With the main story sections drafted, the workflow generates the surrounding editorial elements:
- Newsletter intro
- A specialized prompt summarizes the overall theme of the edition.
- The LLM may reference the selected stories to create a cohesive opening paragraph.
- Subject line candidates
- Another prompt focuses only on subject line generation.
- The LLM must follow strict constraints, such as:
- Specific word counts
- Target tone (e.g., informative, slightly playful, or serious)
- The model can also return its reasoning so editors understand why each subject line might perform well.
Human review in Slack
These generated elements are then sent to Slack, where editors can:
- Approve or reject subject line options.
- Request revisions if the intro or tone does not match the brand.
- Use Slack’s send-and-wait style flows so the workflow pauses until a decision is made.
This keeps humans in control of key editorial decisions while still benefiting from automation.
Step 6 – Final review and publishing
Assembling the final markdown newsletter
Once all sections are approved, the workflow moves into the finalization stage:
- Aggregate everything
- Combine the intro, all story sections, and any closing notes into a single markdown document.
- Create a file from markdown
- Convert the markdown content into a file object that n8n can upload or pass to other systems.
Publishing and notifications
The final step is to make the newsletter accessible to your team and tools:
- Upload to Slack
- Send the markdown file directly to a Slack channel.
- Include a completion message and a permalink so the team can easily find and distribute it.
- Optional uploads
- Instead of or in addition to Slack, you can upload the file to a CMS or a storage bucket like S3/R2.
Best practices for a robust n8n newsletter workflow
1) Keep prompts strict and structured
For any LLM call that feeds into downstream automation, require a JSON schema. This allows you to:
- Parse outputs reliably using structured output parsers.
- Validate that required fields are present before moving forward.
- Avoid brittle text parsing based on headings or bullet patterns.
2) Validate external links and source rules
If your editorial guidelines require exact source URLs, build checks into your workflow to:
- Copy URLs verbatim from source material.
- Flag items where links are missing or incomplete.
- Prevent accidental modification of link parameters that matter for tracking or attribution.
3) Rate limit and handle LLM errors
LLM calls and web scraping can be resource intensive. To keep the workflow stable:
- Use retriable nodes or custom error handling for transient failures.
- Enable continue-on-error behavior where a single failed story should not break the entire newsletter.
- Process heavy tasks, like scraping many external pages, in separate, batched steps with SplitInBatches.
4) Keep humans in the loop
Automation should accelerate, not replace, editorial decision making. Maintain:
- Slack-based approval steps for story selections.
- Review gates for subject lines and intros.
- Clear messaging in Slack so editors know what they are approving and how to give feedback.
5) Avoid duplicates and stale content
To keep your newsletter fresh:
- Filter out stories that appeared in previous editions.
- Limit selection to content within a tight recency window, such as the same date or plus/minus one day.
- Use identifiers or hashes to detect duplicate items even if titles change slightly.
Extending the workflow template
Once you have the basic pipeline running, you can evolve it to match your distribution strategy and analytics stack. Some common extensions include:
- A/B test subject lines
- Automatically send different subject lines to small audience segments.
- Pick the best performer based on opens or clicks for the main send.
- Publish directly to email providers
- Use API nodes to send the final markdown to platforms like SendGrid or Mailgun.
- Convert or map markdown to the email provider’s template format.
- Add analytics hooks
- Log story-level data for opens, clicks, and downstream engagement.
- Feed this performance data back into your selection prompts over time.
Security and compliance considerations
Because this workflow may interact with user data, storage, and external APIs, treat it as part of your production system:
- Protect credentials in n8n
- Store API keys and secrets in n8n’s credentials manager, not in plain text fields.
- Secure S3/R2 access
- Limit which buckets and prefixes the workflow can access.
- Use appropriate IAM roles or access policies.
- Avoid leaking sensitive data to LLMs
- Do not include unnecessary PII in prompts.
- If you use personalization
