
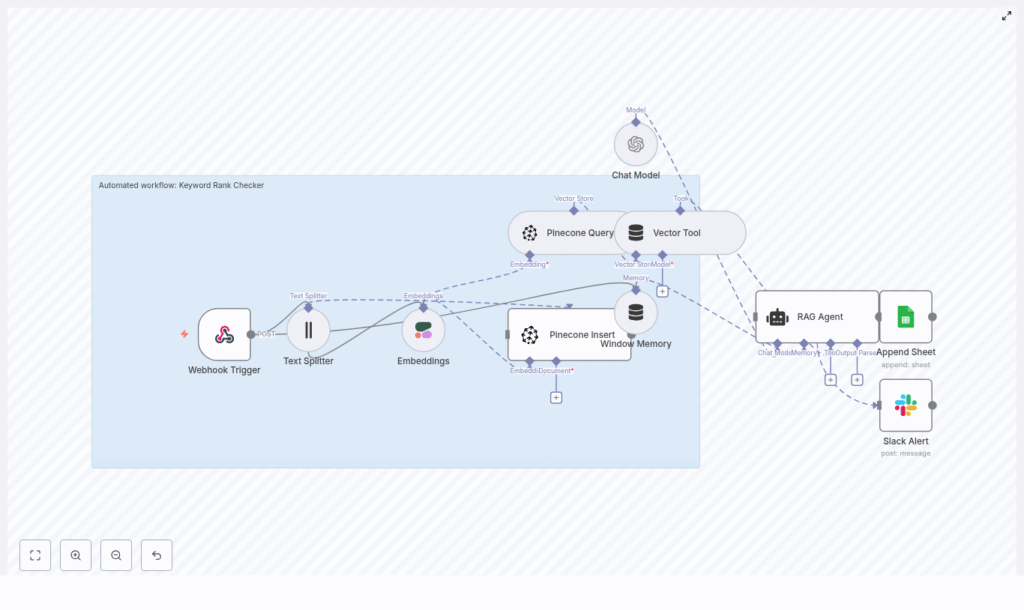
Automated Keyword Rank Checker with n8n
Tracking keyword rankings at scale does not have to be a manual, copy-and-paste task. In this guide you will learn, step by step, how to use an n8n workflow template to build an automated Keyword Rank Checker.
This workflow combines text splitting, Cohere embeddings, Pinecone as a vector database, a retrieval-augmented generation (RAG) agent, and Google Sheets logging. It is designed for SEO teams, product managers, and developers who want a repeatable, auditable automation for keyword context, ranking signals, and historical records.
Learning goals
By the end of this tutorial, you will understand how to:
- Use an n8n Webhook Trigger to receive keyword and SERP data
- Split page content into chunks and generate Cohere embeddings
- Store and query vectors in Pinecone for RAG-based analysis
- Configure a RAG Agent with an OpenAI chat model in n8n
- Log results in Google Sheets and send Slack alerts on errors
- Use and extend the workflow for ongoing keyword rank tracking
Why automate keyword rank checking with n8n?
n8n is a low-code automation platform that integrates naturally with modern AI services. Using n8n as the backbone of your keyword rank checker gives you:
- Automated ingestion via webhooks, schedulers, or scrapers
- Context-aware ranking insights using vector embeddings and RAG
- Scalable storage and retrieval through Pinecone
- Human-readable summaries powered by an OpenAI chat model
- Audit trails and alerts using Google Sheets and Slack
Instead of just logging a rank number, this setup helps you understand why rankings change and what to do next.
Concept overview: how the workflow works
The template implements a full pipeline from incoming SERP data to actionable recommendations. At a high level, the workflow:
- Receives a POST request at a webhook endpoint with keyword and SERP data
- Splits the target page HTML into smaller text chunks
- Generates embeddings for each chunk using Cohere
- Stores embeddings in a Pinecone index and queries them for context
- Feeds the retrieved context and payload into a RAG Agent with an OpenAI chat model
- Writes the resulting status or recommendation to a Google Sheet
- Sends a Slack alert if something fails
Below we unpack each part in more detail, then walk through the configuration step by step.
Step-by-step: building the n8n Keyword Rank Checker
Step 1 – Webhook Trigger: accept keyword data
The entry point of the workflow is a Webhook Trigger node.
- Method: POST
- Path:
/keyword-rank-checker
Configure the Webhook Trigger so external tools can send a JSON payload containing:
query– the search keyword (for example, “best running shoes”)target_url– the URL you are trackingrank– the current position in the SERPtimestamp– when the rank was recordedpage_html– the HTML of the target pageserp_snapshot– an array of top result objects for context- Optional: previous rank, CPC, impressions, clicks, or other SEO metrics
You can send this data from a crawler, a scheduled SERP scraper, or a custom script.
Step 2 – Text Splitter: prepare content for embeddings
Embedding entire HTML pages at once is inefficient and can lose context. Instead, the workflow uses a Text Splitter node to break the page content into smaller chunks.
Configuration used in the template:
- Splitter type: Character-based
- Chunk size: 400 characters
- Chunk overlap: 40 characters
This chunking strategy:
- Preserves enough surrounding context for each chunk
- Prevents the embeddings from becoming too large or expensive
- Improves retrieval quality when you later query the vector store
Step 3 – Embeddings (Cohere): turn text into vectors
After splitting the content, the workflow uses a Cohere Embeddings node to transform each chunk into a numerical vector.
Key details:
- Model:
embed-english-v3.0
Cohere embeddings are well suited for semantic similarity tasks, such as:
- Comparing your page content to competitor pages in the SERP
- Tracking how your content changes over time at the vector level
- Feeding meaningful context into a RAG Agent for analysis
Step 4 – Pinecone: insert and query vectors
The next step is to store and query the embeddings in a Pinecone index.
The template uses:
- Index name:
keyword_rank_checker
Two operations are involved:
- Insert – All generated embeddings for the current page snapshot are stored in the index. This builds up a historical vector record of your page content and related signals.
- Query – When you need context (for example, to explain a rank drop), the workflow queries the same index for similar vectors. Pinecone returns the most relevant chunks that can be passed to the RAG Agent.
Pinecone is optimized for fast similarity search and can scale horizontally, which is useful if you are tracking many keywords or large sites.
Step 5 – Vector Tool and Window Memory: provide context to the agent
To make the Pinecone results usable by the RAG Agent, the workflow uses two important n8n components:
- Vector Tool – Wraps Pinecone queries as a tool that the RAG Agent can call to retrieve relevant context.
- Window Memory – Stores short-term interaction state so the agent can reference previous steps or signals during a single run.
Together, these let the RAG Agent work with both:
- Fresh data from the current webhook payload
- Historical or related content stored in Pinecone
Step 6 – Chat Model and RAG Agent: generate insights
The reasoning and explanation part of the workflow is handled by a Chat Model node and a RAG Agent node.
- Chat Model: Connects to OpenAI and provides natural language generation.
- RAG Agent: Orchestrates retrieval (via the Vector Tool) and generation.
Key configuration details:
- System message:
You are an assistant for Keyword Rank Checker - Prompt: Instructs the agent to process the incoming JSON payload, use retrieved vector context, and output a concise status or recommendation for the keyword.
Example type of output you might generate:
Rank dropped from 5 to 12, content similarity to top results is low, recommend updating on-page SEO and aligning headings with high intent queries.
This is where the workflow converts raw SERP and content data into actionable guidance.
Step 7 – Append Sheet: log results in Google Sheets
To keep an auditable history, the workflow writes each result to a Google Sheets document using an Append Sheet node.
Configuration details:
- Sheet ID:
SHEET_ID(replace with your actual document ID) - Sheet name:
Log - Column example: store the agent output in a
Statuscolumn
Over time this gives you a time series of:
- Keyword
- Rank and date
- Key metrics (CPC, impressions, clicks, etc.)
- Agent recommendations or status messages
You can then use this sheet for reporting, dashboards, or export to BI tools.
Step 8 – Slack Alert: handle errors quickly
Reliability is important when you automate monitoring. The template includes a Slack Alert node that is triggered by the RAG Agent’s onError connection.
If any node in the workflow throws an error, the Slack node posts a message to:
- Channel:
#alerts - Content: includes the error message and basic details
This helps you detect failures early and debug issues before they affect your reporting.
How to use this workflow for keyword rank tracking
Once the template is configured, you can plug it into your SEO process.
Recommended usage pattern
- Set up a SERP scraper that runs on a schedule and:
- Fetches SERP results for your target keywords
- Captures the HTML of your target page
- Optionally collects metrics like previous rank, CPC, impressions, and clicks
- POST the data to the n8n webhook at
/keyword-rank-checkerwith a JSON payload that includes:query,target_url,rank,timestamppage_htmlandserp_snapshot- Any additional SEO metrics you want to log
- Let the workflow run:
- Content is embedded and stored in Pinecone
- Relevant context is retrieved with the Vector Tool
- The RAG Agent generates a human-readable status or recommendation
- The result is appended to your Google Sheet
- Review outputs in Google Sheets and:
- Identify rank drops or improvements
- Act on the suggested SEO changes
- Monitor alerts in Slack when something breaks
Over time, this gives you both quantitative rank data and qualitative explanations in a single place.
Example webhook payload
Here is a sample JSON payload you might send to the webhook:
{ "query": "best running shoes", "target_url": "https://example.com/article", "rank": 8, "timestamp": "2025-08-31T12:00:00Z", "page_html": "<html>...article content...</html>", "serp_snapshot": [ /* array of top result objects */ ]
}
You can extend this payload with additional fields like previous rank, impressions, or click-through rate, then adapt the RAG Agent prompt so it uses these signals.
Extensions and best practices
1. Add scheduled checks
Use n8n’s Cron or scheduling features to trigger regular SERP scrapes and POST requests to the webhook. This builds a consistent time series of ranks and embeddings that you can analyze for trends.
2. Store raw SERP snapshots
In addition to embeddings, consider storing:
- Raw SERP HTML or JSON
- Screenshots or links to screenshots (for example, S3 URLs)
These can be referenced later for deep-dive investigations or richer context in your RAG prompts.
3. Improve prompt engineering
Fine tune the RAG Agent’s system message and prompt to focus on the signals that matter most to you, such as:
- Click-through rate (CTR)
- Backlink profile or authority
- Keyword usage in titles, headers, and body content
Include examples of desired output and a clear structure. For example, ask the agent to always return:
- A short summary
- Key reasons for the rank change
- Specific recommended actions
4. Monitor costs and scale
Embedding and LLM calls have associated costs. To keep them under control:
- Batch operations where possible
- Keep chunk sizes sensible (like the 400 / 40 configuration)
- Consider lower cost embedding models for very large-scale indexing
- Track usage across Cohere, Pinecone, and OpenAI and adjust frequency or volume
5. Security and data privacy
Be careful with the data you send to third-party services. If your payload includes any user or customer information:
- Filter out personally identifiable information (PII) before embedding
- Consider self-hosted models or private deployments if required by compliance
- Review the data retention policies of Cohere, Pinecone, and OpenAI
Troubleshooting guide
- Pinecone inserts fail:
- Check that your Pinecone API key is correct
- Verify the index name is exactly
keyword_rank_checker
- Embedding errors with Cohere:
- Confirm your Cohere API key and permissions
- Ensure the model
embed-english-v3.0is available on your account
- RAG Agent output is poor or off-topic:
- Add more detail to the system prompt and instructions
- Increase the number of retrieved vectors from Pinecone
- Include more structured fields in the payload (for example previous rank, CTR)
- Workflow fails silently:
- Use the Slack Alert node to capture runtime exceptions
- Check n8n execution logs for error messages and stack traces
Recap: what this n8n template gives you
This Keyword Rank Checker template turns n8n into an automated SEO monitoring system that:
- Ingests keyword, SERP, and page data via a webhook
- Uses Cohere embeddings and Pinecone to build a vector-based history of your content
- Applies a RAG Agent with OpenAI to explain ranking changes and recommend actions
- Logs every result in Google Sheets for analysis and reporting
- Alerts you in Slack when something goes wrong
Instead of manually checking rankings and guessing at
