
Automating Job Application Parsing with n8n & Pinecone
Manually skimming resumes is fun for about 3 minutes, right up until you are reading your 47th cover letter that starts with “To whom it may concern.” If your hiring process involves copy-pasting data into spreadsheets, searching for skills with Ctrl+F, and trying to remember which “John S.” was the distributed systems expert, it is probably time to let automation take over the boring parts.
This guide walks you through an n8n workflow template that does exactly that. It takes incoming job applications, breaks them into chunks, generates OpenAI embeddings, stores everything in Pinecone for semantic search, runs a lightweight RAG agent to make sense of it all, logs results into Google Sheets, and pings Slack if something explodes. In other words, it turns resume chaos into something your team can actually work with.
What this n8n job application parser actually does
At a high level, the workflow handles the full journey of a job application:
- Receives applications via a secure webhook in n8n
- Splits long resume text into smaller chunks for better embeddings
- Uses OpenAI embeddings (
text-embedding-3-small) to create semantic vectors - Stores those vectors in a Pinecone index for fast vector search
- Queries Pinecone when context is needed and feeds it into a RAG agent
- Uses a chat model with windowed memory to generate summaries and insights
- Logs structured results into a Google Sheet for tracking and review
- Sends Slack alerts if an error occurs so you do not find out three days later
The end result is a workflow that helps your hiring team search and understand applications semantically instead of relying on brittle keyword matching. A candidate might say “highly available distributed backend” instead of your exact term “distributed systems,” and you will still find them. Your future self will thank you.
Why bother with a job application parser in the first place?
Hiring teams are often drowning in resumes, cover letters, and portfolio links. Traditional approaches lean heavily on keyword filters, which are about as subtle as a sledgehammer. If the candidate does not use your exact phrasing, they can slip through the cracks, even if they are perfect for the role.
By using embeddings and vector search, this workflow lets you:
- Search applications by meaning, not just exact words
- Quickly surface relevant candidates for a given role or skillset
- Automate the first-pass parsing and triage of applicants
- Generate summaries and matched skills without reading every line manually
In short, it upgrades your hiring process from “scroll and pray” to “structured, searchable, and semi-intelligent.”
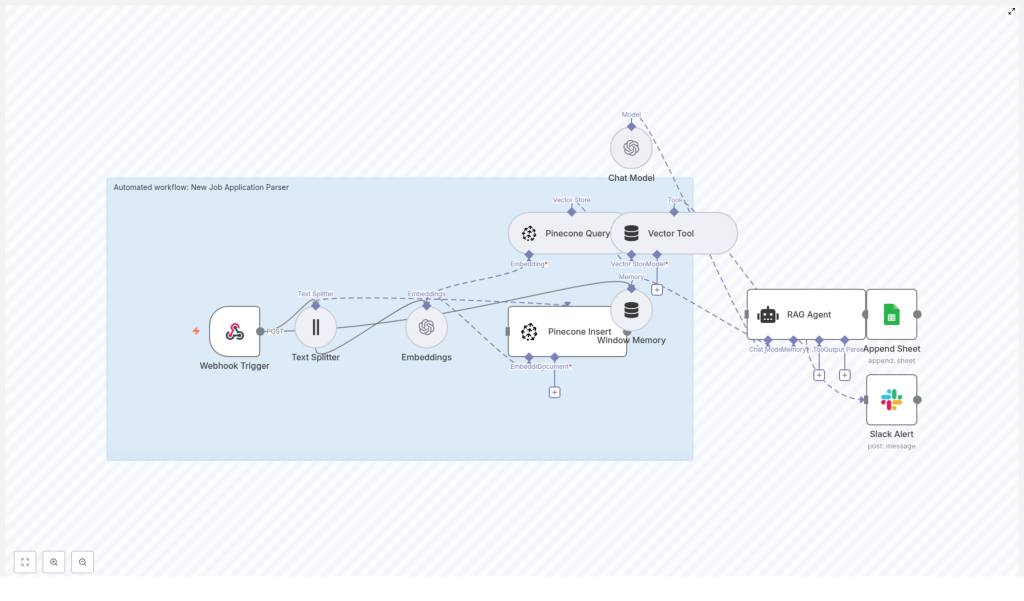
How the architecture fits together
The template is built as an n8n workflow that strings several nodes together into a mini application parsing pipeline. Here is the cast of characters you will be working with:
- Webhook Trigger – Receives new job applications via POST at
/new-job-application-parser - Text Splitter – Breaks large documents into chunks (
chunkSize: 400,chunkOverlap: 40) - OpenAI Embeddings – Uses
text-embedding-3-smallto turn text chunks into vectors - Pinecone Insert – Stores vectors in a Pinecone index called
new_job_application_parser - Pinecone Query + Vector Tool – Retrieves relevant chunks via semantic similarity
- Window Memory + Chat Model + RAG Agent – Synthesizes context into summaries and structured outputs
- Append to Google Sheets – Logs final results to a sheet named
Log - Slack Alert (error path) – Notifies a Slack channel when something goes wrong
Together, these nodes form a retrieval-augmented generation workflow tailored for job applications, with Pinecone acting as your vector database and OpenAI providing the embeddings and chat model.
Quick setup walkthrough: from webhook to Slack alerts
Let us walk through the workflow in the order n8n actually runs it, with just enough detail to get you from “template imported” to “wow, that is in my Google Sheet already.”
1. Accepting applications with the Webhook Trigger
The entry point is a POST webhook configured at the path new-job-application-parser. This is where your job application intake system sends data. You can POST:
- Raw resume text
- Text extracted from a PDF
- Form submissions
- A JSON payload containing structured candidate fields
Since this endpoint is valuable, you should keep it protected. Use an API key, secret token, n8n credentials, or some other authentication in front of the webhook so random internet strangers are not spamming your index.
2. Chopping resumes into chunks with the Text Splitter
Long documents do not play nicely if you try to embed them as a single block. The Text Splitter node solves this by splitting incoming text into smaller segments.
The template uses:
chunkSize = 400chunkOverlap = 40
That overlap keeps some context between chunks so the embeddings still “remember” what came before. You can tweak these values if your resumes are very short or very long, but this configuration is a good starting point for most use cases.
3. Generating embeddings with OpenAI
Once the text is split, each chunk is fed into the OpenAI Embeddings node. The template uses the text-embedding-3-small model, which provides solid performance at a reasonable cost.
Each chunk comes out as a vector that represents the semantic meaning of that piece of text. These vectors are what Pinecone uses later for semantic search. If you have strict accuracy or budget requirements, you can swap in a different embedding model, but keep an eye on both quality and cost.
4. Storing vectors in Pinecone
Next up, the workflow inserts each embedding into a Pinecone index named new_job_application_parser. The node uses the insert mode in the template.
For better filtering and traceability, you can store metadata alongside each vector, such as:
- Candidate ID
- Email address
- Source (e.g. job board, referral)
- File name or upload ID
- Timestamp
That metadata makes it easier to connect search results back to specific candidates and to filter by things like role or source later on.
5. Retrieving context with Pinecone Query and Vector Tool
Once your vectors live in Pinecone, you can start asking questions. The workflow includes a Pinecone Query node and a Vector Tool that exposes the vector store as a retrieval tool to the RAG Agent.
When a hiring manager or downstream system asks something like “Who has strong distributed systems experience?” the workflow:
- Uses semantic similarity search in Pinecone to find the most relevant chunks
- Passes those retrieved chunks into the RAG Agent as context
This step is what lets you search by meaning instead of exact phrases, which is where the real power of embeddings shows up.
6. Making sense of it all with Window Memory, Chat Model, and RAG Agent
Now that you have relevant chunks, the RAG Agent steps in to turn raw text into something readable and useful. It uses:
- Windowed memory to keep recent context manageable
- A chat model from OpenAI to generate responses
- The vector tool to pull in context from Pinecone as needed
The agent node in the template is configured with a system message:
You are an assistant for New Job Application Parser
It receives the parsed data via {{ $json }} and can produce outputs such as:
- Short candidate summaries
- Lists of matched skills
- Suggested screening questions
This is the point where you stop reading every resume line by line and let the agent give you a condensed view instead.
7. Logging results in Google Sheets
To keep an audit trail and an easy place for your team to review results, the workflow appends the final outputs from the RAG Agent into a Google Sheet.
In the template, it uses:
- Document ID:
SHEET_ID - Sheet name:
Log
The example maps the agent response into a column called Status, but you can extend this to include other fields like candidate name, role, or a link to the original application. For production setups, you can also export from Sheets into your ATS via API.
8. Getting notified when things break with Slack alerts
No workflow is perfect, and that is why the template includes a Slack Alert node on the error path. If something fails, it sends a message to a channel such as #alerts so your team can investigate quickly.
This beats discovering silently failed runs a week later when someone asks “Hey, why did we get zero applicants for that role?”
Configuration and credential checklist
Before you hit “Activate” in n8n, make sure you have all the required credentials wired up:
- OpenAI API key configured in n8n for the Embeddings and Chat Model nodes
- Pinecone API key and environment set up, with an index named
new_job_application_parser - Google Sheets OAuth credentials with edit access to the target spreadsheet
- Slack API token with permission to post to your alert channel
- Secure access to the webhook, for example token checks, firewall rules, or a private tunnel
Once these are in place, your workflow can run end to end without constant babysitting.
Tuning the workflow for better results
Out of the box, the template works well, but a few tweaks can make it even more effective for your specific hiring process.
Chunking and embeddings
- Chunk size – Increase it for dense paragraphs, decrease it for bullet-heavy resumes. Too large, and embeddings become vague. Too small, and you lose important context.
- Embedding model – If you need very nuanced skill matching and your budget allows, try a higher quality embedding model. Just monitor the cost impact.
Metadata and retrieval
- Metadata – Store fields like
candidate_id, email, and role in Pinecone metadata. This helps with deterministic filtering, traceability, and compliance. - Retrieval parameters – Adjust top-k and similarity thresholds in the Pinecone Query node to control how many chunks are retrieved for the RAG Agent. Too many chunks can overwhelm the model, too few can leave out important context.
Performance and rate limits
- Keep an eye on OpenAI and Pinecone usage so you do not run into throttling at the worst possible time.
- Consider adding retries and exponential backoff in your workflow for more robust handling of transient errors.
Security and privacy for candidate data
Resumes are packed with personally identifiable information, so treating this data carefully is not optional.
- Use HTTPS for all traffic and enable encryption at rest where supported in Pinecone and Google Sheets.
- Minimize retention and delete vectors and raw application data when it is no longer needed or when candidates request deletion.
- Restrict access to the webhook and Google Sheet using IAM, service accounts, or token-based controls.
- Review your privacy policy and ensure compliance with relevant data protection laws such as GDPR or CCPA.
Testing the workflow before going live
Before you trust this workflow with real candidates, run through a quick test checklist:
- POST a sample application payload to the webhook and confirm all nodes execute without errors in n8n.
- Verify that embeddings are created and vectors appear in the
new_job_application_parserindex in Pinecone. - Run semantic queries against the index and check that relevant chunks are returned.
- Review RAG Agent outputs, such as summaries and matched skills, to ensure they are accurate and not hallucinating details.
- Confirm that new rows are appended to the Google Sheet with the expected fields.
- Intentionally trigger an error to verify that Slack alerts and onError routing work as expected.
Scaling and preparing for production use
Once the workflow is working well on a handful of applications, you can harden it for higher traffic and real-world usage.
- Use batching and asynchronous inserts to Pinecone for bulk uploads to improve throughput.
- Consider sharding your index or using namespaces for multi-tenant or multi-role setups.
- Monitor embedding and query costs and cache frequent queries where it makes sense.
- Integrate with a logging and observability stack such as Datadog or Prometheus to track failures, latency, and performance over time.
Common pitfalls to avoid
To save you from a few classic “why is this not working” moments, keep an eye on these:
- Misconfigured Pinecone index – If the index name is wrong or the index does not exist, the Pinecone Insert node can fail silently. Double check the name
new_job_application_parser. - Oversized chunks – Very large chunks lead to less reliable embeddings. Tune
chunkSizeandchunkOverlapinstead of just throwing more text at the model. - RAG agent hallucinations – Design prompts so the agent cites retrieved chunks and indicate when information is not available. You can also include confidence scores or links to sources.
- PII exposure in Sheets – Avoid putting sensitive identifiers in any sheet that might be shared broadly. Keep access tightly controlled.
Example RAG Agent prompt you can start with
A clear system message goes a long way in keeping the agent grounded in the retrieved context. Here is a sample prompt pattern:
System: You are an assistant for New Job Application Parser. Only use provided context. If information is not present, say "Not available." User: Process the following candidate data and produce a 3-sentence summary plus a list of matched skills.
You can extend this prompt to include your own requirements, such as preferred tone, screening criteria, or formatting instructions.
Next steps: deploy, test, and iterate
To get this workflow running with minimal fuss:
- Import the provided n8n template into your n8n instance
- Connect your OpenAI and Pinecone credentials
- Set up Google Sheets and Slack credentials
- Point the webhook at your job application intake URL
From there, you can refine prompts, adjust chunking and retrieval parameters, and gradually integrate the results into your ATS or internal tools.
Ready to try it? Import the template into n8n, send a test POST to /new-job-application-parser, and watch as structured entries appear in your Google Sheet instead of in your inbox. If you want to go further, you can generate additional prompt templates or example JSON payloads to standardize how applications are sent into the workflow.
