
How One Legal Team Stopped Drowning in NDAs With an n8n Risk Detector
The Night the NDAs Took Over
By 9:30 p.m., Maya was still at her desk.
As the lead counsel at a fast-growing SaaS company, she had a problem that never seemed to shrink: NDAs. Sales kept closing more deals, partnerships were spinning up every week, and every single agreement needed a legal eye. Her inbox was a wall of attached PDFs with subject lines like “Quick NDA review – should only take 5 minutes.”
It never took 5 minutes.
Maya knew the risks. Buried in those documents could be clauses about indefinite confidentiality, lopsided indemnity, or sneaky IP assignment that could haunt the company years later. But manual review was slow and tiring, and humans miss things when they are exhausted.
She did not want to become the bottleneck for the entire company, yet she also could not afford to miss a risky clause. She needed a way to surface risky NDA language automatically, prioritize what to review, and keep a clear record of decisions.
That was the night she discovered an n8n NDA Risk Detector template that used vector search, embeddings, and an LLM agent. It promised exactly what she needed: automated clause detection, similarity search, and a Google Sheets log, all wrapped in a workflow she could control.
From Chaos to a Plan: What Maya Wanted to Fix
Before she even opened n8n, Maya wrote down what was breaking her process:
- She spent too much time scanning for red flags like assignment, broad indemnity, unilateral termination, and indefinite confidentiality.
- Important NDAs often got stuck in her inbox, with no easy way to prioritize which ones looked riskiest.
- There was no consistent, auditable trail of why she flagged or approved a contract.
What she needed sounded simple, but technically demanding:
- A way to accept NDAs automatically from existing tools.
- A system to analyze clauses using embeddings and similarity search instead of brute-force reading.
- An LLM-based agent that could turn all this into a clear risk score and explanation.
- A Google Sheets log that would give her an audit trail for every NDA reviewed.
That is where the n8n template came in. It already combined n8n, LangChain-style components, Redis vector storage, and an LLM agent into a single workflow. All she had to do was adapt it to her stack.
The Architecture Behind Her New NDA Copilot
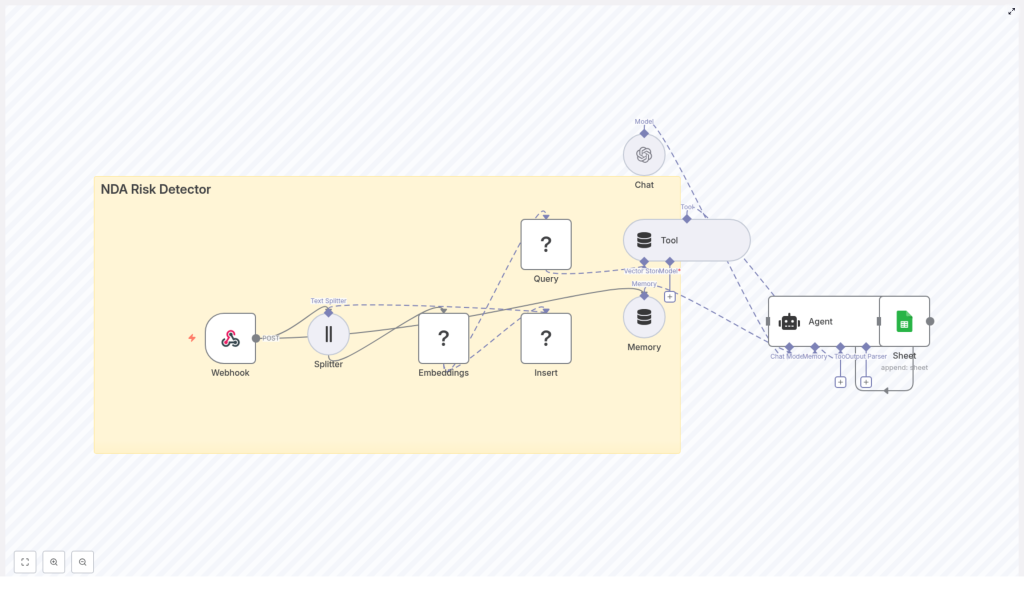
Maya opened the template and saw an architecture that felt like a blueprint for her new process. Instead of starting from scratch, she could trace the story of each document through a series of nodes:
- Webhook to receive NDA text or file links from her existing systems.
- Text Splitter to break long contracts into manageable chunks.
- Embeddings to convert each chunk into a numerical vector.
- Redis Vector Store to store and search those vectors.
- Query + Tool to pull back relevant clauses for analysis.
- Memory, Chat, and Agent to evaluate risk and generate structured output.
- Google Sheets logging to record risk scores, explanations, and references.
This was not just a workflow, it was a narrative for each NDA:
- The NDA arrives.
- It is broken into chunks and embedded.
- Vectors are stored in Redis for fast similarity search.
- An agent reviews risky patterns, scores them, and writes a report.
- The result lands in a central log, ready for human review.
Now she just needed to walk through each part and make it her own.
Act I: The Webhook That Replaced Her Inbox
First, Maya set up the entry point. Instead of NDAs living in email threads, they would now flow into n8n through a Webhook node.
She configured a POST webhook that accepted NDA text or links to files. Her sales team could send data in a simple JSON format like:
{ "document_id": "12345", "text": "Full NDA text...", "source": "email"
}
To avoid turning this into a security hole, she added a few safeguards:
- Required an API key header on all incoming requests.
- Validated the origin so only trusted systems could send NDAs.
Now, instead of Maya manually forwarding attachments, NDAs streamed directly into the workflow. That alone felt like a small victory.
Act II: Splitting Contracts Into Searchable Pieces
Once an NDA reached n8n, the next challenge was its size. Some contracts were only a page or two, others ran to dozens of pages. Feeding the whole thing to an embedding model at once would not work.
The template solved this with a Text Splitter node, and Maya decided to keep its defaults:
- chunkSize: 400 characters
- chunkOverlap: 40 characters
Those numbers struck a balance. Each chunk was small enough for the embedding model to handle efficiently, yet overlap preserved context so clauses that spanned boundaries still made sense.
She knew she could later tune these values for longer or shorter documents, but for now, 400 and 40 gave her a reliable starting point.
Act III: Teaching the System What Her Clauses Look Like
Next came the part that made the workflow feel intelligent: embeddings.
For each chunk of text, the Embeddings node converted language into numerical vectors. These vectors captured the semantic meaning of clauses, which meant the system could later find “similar” risky language even if the wording changed.
In the template, embeddings were powered by a Hugging Face model, using a configured credential like HF_API. That suited Maya well, but she appreciated that she could:
- Swap in OpenAI embeddings if her team preferred that provider.
- Use an on-prem embedding model for stricter privacy requirements.
Regardless of the provider, the idea stayed the same. Every chunk became a vector representation, ready to be stored and searched.
Act IV: Redis Becomes Her Memory for Risky Clauses
Once the NDA snippets were embedded, the workflow needed a place to remember them. That is where the Redis Vector Store came in.
The template used a Redis index called nda_risk_detector. For each chunk, the workflow stored:
- Its vector embedding.
- Metadata like
document_idandchunk_index.
The insert mode was set to “insert”, which made it straightforward to add new documents as they came in. Later, when Maya or a teammate wanted to analyze a specific NDA or clause, the workflow could query this same index and instantly retrieve the most similar chunks.
Redis was no longer just a cache; it became the searchable memory of everything the company had seen in NDAs.
Turning Point: Letting an Agent Score the Risk
The real turning point for Maya was when she saw how the template combined vector search with an LLM-powered agent.
When it was time to review a clause or run a heuristic check on a document, the workflow used a Query node to perform a vector search against the nda_risk_detector index. The closest matches were then passed into a VectorStore Tool node.
This tool was one of the agent’s “eyes.” It allowed the LLM agent to pull in the most relevant context snippets from Redis for whatever question it was trying to answer, such as:
- “Does this NDA contain an indefinite confidentiality clause?”
- “Is there a broad indemnity provision that might be risky?”
- “How does this termination clause compare to our usual standard?”
Behind the scenes, the agent orchestration did three important things:
- Memory (buffer window) kept track of recent interactions and follow-up questions.
- Chat (OpenAI or another LLM) evaluated the retrieved snippets for known risk patterns.
- Agent logic controlled how prompts were structured and how signals were combined into a final answer.
To keep the system reliable, Maya used a structured prompt schema. It told the model exactly what to return and how to format its response.
The Prompt That Made It All Click
The template suggested a prompt like this, which Maya adapted slightly for her policies:
Analyze the following NDA snippets for risky clauses (assignment, broad indemnity, indefinite confidentiality, unilateral termination, IP assignment). Return:
- risk_score: low|medium|high
- reasons: short bullet points
- references: top 3 snippet IDs
Snippets:
1) "..."
2) "..."
This prompt gave her:
- A risk_score she could sort and filter on (low, medium, high).
- Short, human-readable reasons for the score.
- References to the exact snippet IDs in Redis, which helped her trace back to the original contract text.
By keeping the schema clear and deterministic, she reduced randomness in the model’s answers and made it much easier to evaluate and tune the system.
Resolution: A Google Sheet That Told the Whole Story
Once the agent finished its analysis, Maya did not want the result to vanish into logs. She needed a place where legal, product, and leadership could see the big picture.
The final part of the template used a Google Sheets node to append each result as a new row. For every NDA, the sheet stored fields like:
- timestamp
- document_id
- risk_score
- explanation (reasons)
- references (snippet IDs)
Over time, this became her auditable trail of NDA reviews. When an executive asked why a contract had been flagged, Maya could point to a specific row with clear reasons and references back to the underlying text.
For the highest risk cases, she layered in optional notifications. Using n8n, she configured alerts so that “high” risk NDAs triggered Slack or email notifications, ensuring nothing urgent slipped through.
Keeping It Safe: Security, Privacy, and Compliance
Because NDAs often include sensitive information, Maya treated security as a first-class requirement. The template’s guidance matched her instincts, and she followed it closely:
- Encrypt data at rest in Redis and Google Sheets whenever possible.
- Minimize PII sent to external APIs, redacting or anonymizing names and identifiers when policy required it.
- Use private or on-prem embedding models where the strictest privacy guarantees were needed.
- Lock down the webhook with API keys and IP allowlists so only trusted systems could submit documents.
The result was an automated NDA risk detector that did not compromise on privacy or compliance.
How She Tuned It: Testing and Continuous Improvement
Once the basic workflow was live, Maya treated it like any other legal tool: it needed testing, tuning, and a feedback loop.
She started with a labeled dataset of past NDAs and sample clauses that her team had already reviewed. Then she:
- Measured precision and recall for risky clause detection.
- Set up a human review loop for all high-risk results to confirm accuracy.
- Monitored false positives and adjusted prompts or similarity thresholds accordingly.
As she iterated, the system became more aligned with her company’s specific risk tolerance and legal standards.
Where She Took It Next: Extensions and Ideas
Once the core NDA Risk Detector was running smoothly, Maya started to imagine what else she could automate using the same foundation.
- Automated PDF ingestion: She added an OCR step for scanned contracts so even image-based NDAs could be analyzed.
- Clause classification: By training a classifier on embeddings, she began automatically labeling clause types, like termination, confidentiality, and IP assignment.
- Domain-specific tuning: She experimented with fine-tuning embeddings or prompts on legal corpora to get even more accurate risk detection.
- Web UI for non-technical users: Her team planned a simple interface where business stakeholders could upload NDAs and see flagged clauses without ever touching n8n.
Operational Lessons From the First Month
Running the workflow in production taught Maya a few operational best practices:
- Retention policy: She set rules to delete vectors for expired or no-longer-relevant documents.
- Index management: After model updates, she scheduled periodic re-indexing to keep vector quality consistent.
- Rate limits: To avoid API throttling on embedding providers, she batched embedding calls for bulk NDA imports.
These adjustments kept the system fast, cost-effective, and reliable as volume grew.
What Changed for Maya and Her Team
A month after switching to the n8n NDA Risk Detector, Maya realized something subtle but important: she was no longer drowning in NDAs.
Instead of reading every line of every agreement, she:
- Let the workflow surface the riskiest clauses first.
- Relied on similarity search to compare new language to known risky patterns.
- Used the Google Sheets log to report on trends and justify decisions.
The core message of her new process was simple: automation handled the heavy lifting, while humans made the final calls.
The NDA Risk Detector template had given her a practical, scalable approach to spotting risky NDA language using n8n, embeddings, Redis, and an LLM-based agent. Manual review time dropped, and the quality and consistency of her risk assessments improved.
Your Turn: Put an NDA Risk Detector to Work
If you are a legal lead, founder, or operations manager facing the same NDA overload that Maya did, you do not have to start from scratch.
You can:
- Import the NDA Risk Detector template into n8n.
- Connect your Hugging Face or OpenAI credentials for embeddings and LLM analysis.
- Configure your Redis vector store with an index like
nda_risk_detector. - Set up the webhook to receive NDA text or file links from your document ingestion source.
- Run a batch of sample NDAs and share the results with your legal team for validation.
If you need a tailored, privacy-first deployment or want help adapting the template to your specific contract types, you can bring in consulting or integration support to accelerate the rollout.
Call to action: Import the template, run a few real NDAs through it, and compare the results to your current manual process. Use the Google Sheets log to discuss findings with your legal team and decide how to tune the workflow. If you want a hands-on workshop or deployment support, reach out and turn your NDA backlog into a manageable, data-driven process
