Automate Pinterest Analysis & AI-Powered Content Suggestions
Imagine waking up on Monday, opening your inbox, and finding a clear list of Pinterest content ideas already tailored to what performs best on your account. No spreadsheets, no manual pin review, no guesswork. That is exactly what this n8n workflow template helps you do.
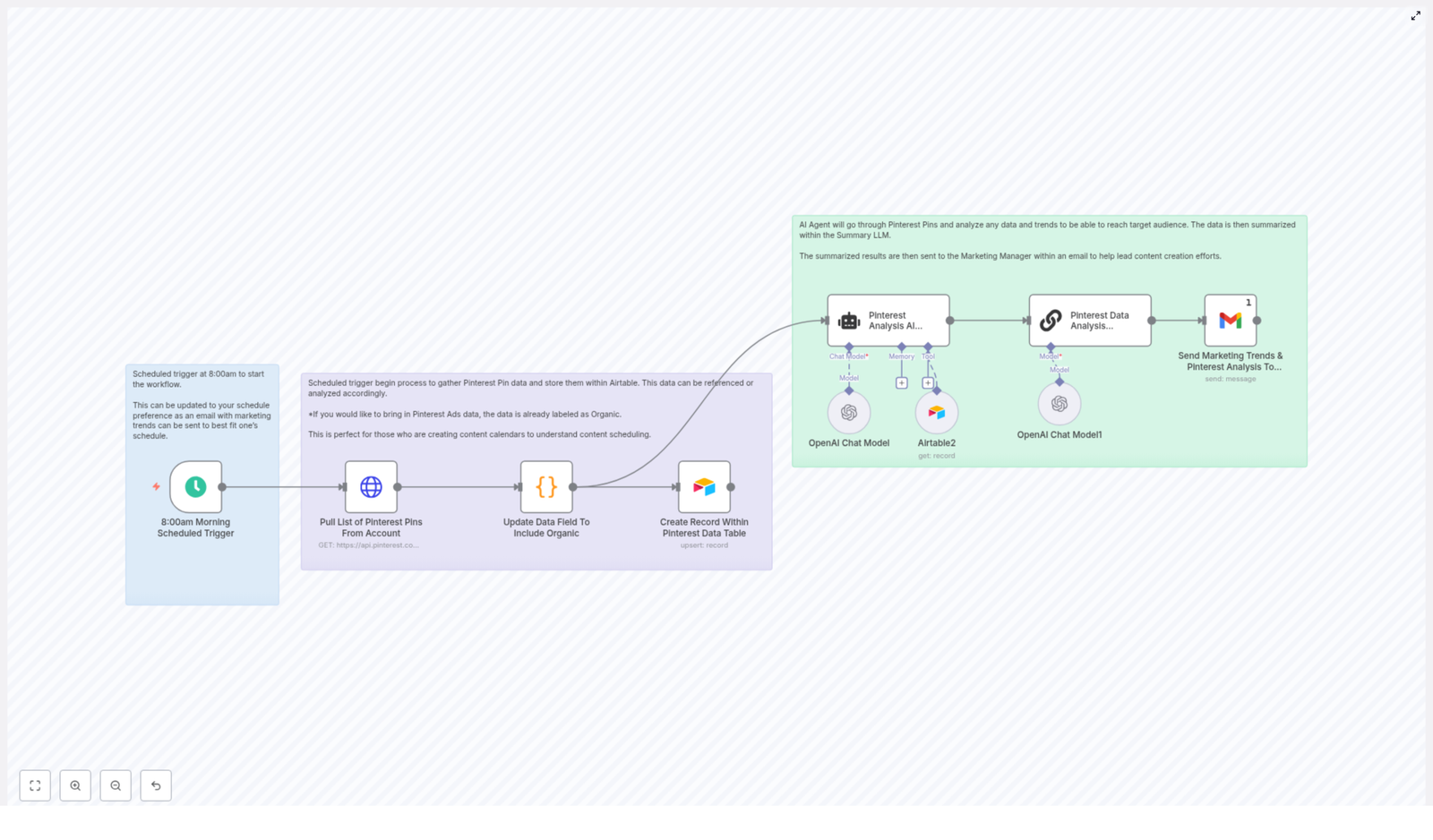
In this guide, we will walk through how to build an end-to-end automation that pulls Pinterest pin data, stores and normalizes it in Airtable, runs AI analysis on top, and then sends your marketing team simple, ready-to-use content suggestions.
What this Pinterest + n8n workflow actually does
At a high level, this workflow connects a few tools you might already be using and turns them into a repeatable content engine. Here is what it handles for you:
- Pulls fresh Pinterest pin data from the Pinterest API on a schedule you choose
- Normalizes that data and tags each pin (for example Organic vs Paid)
- Stores and updates pin history in Airtable for long-term tracking
- Uses an AI agent (like OpenAI) to analyze trends and performance
- Generates specific, trend-based Pinterest content ideas
- Sends a short, actionable summary to your team via email or Slack
So instead of wondering what to pin next, you get a steady stream of data-backed ideas delivered automatically.
Why automate Pinterest analysis at all?
If you have ever tried to manually scroll through your boards and figure out what is working, you know how time consuming and inconsistent it can be. One week you are on top of it, the next week it slips.
Automating Pinterest analysis with n8n and an AI agent helps you:
- Get consistent, data-driven content suggestions on a regular schedule
- Scale your analysis across hundreds of pins and multiple boards without extra effort
- Feed insights directly into content calendars and team workflows via email or Slack
In short, you stop guessing and start using your Pinterest data in a systematic way.
Tools that power the workflow
This template leans on a few familiar tools, stitched together with n8n:
- n8n (or a similar automation platform) to orchestrate the entire flow
- Pinterest API v5 to pull pin metadata and performance details
- Airtable as the central database for pin history and metrics
- OpenAI or another LLM to act as your AI marketing analyst
- Email or Slack so results reach stakeholders where they already work
Once connected, these tools create a loop that keeps learning from your pins and feeding you better ideas.
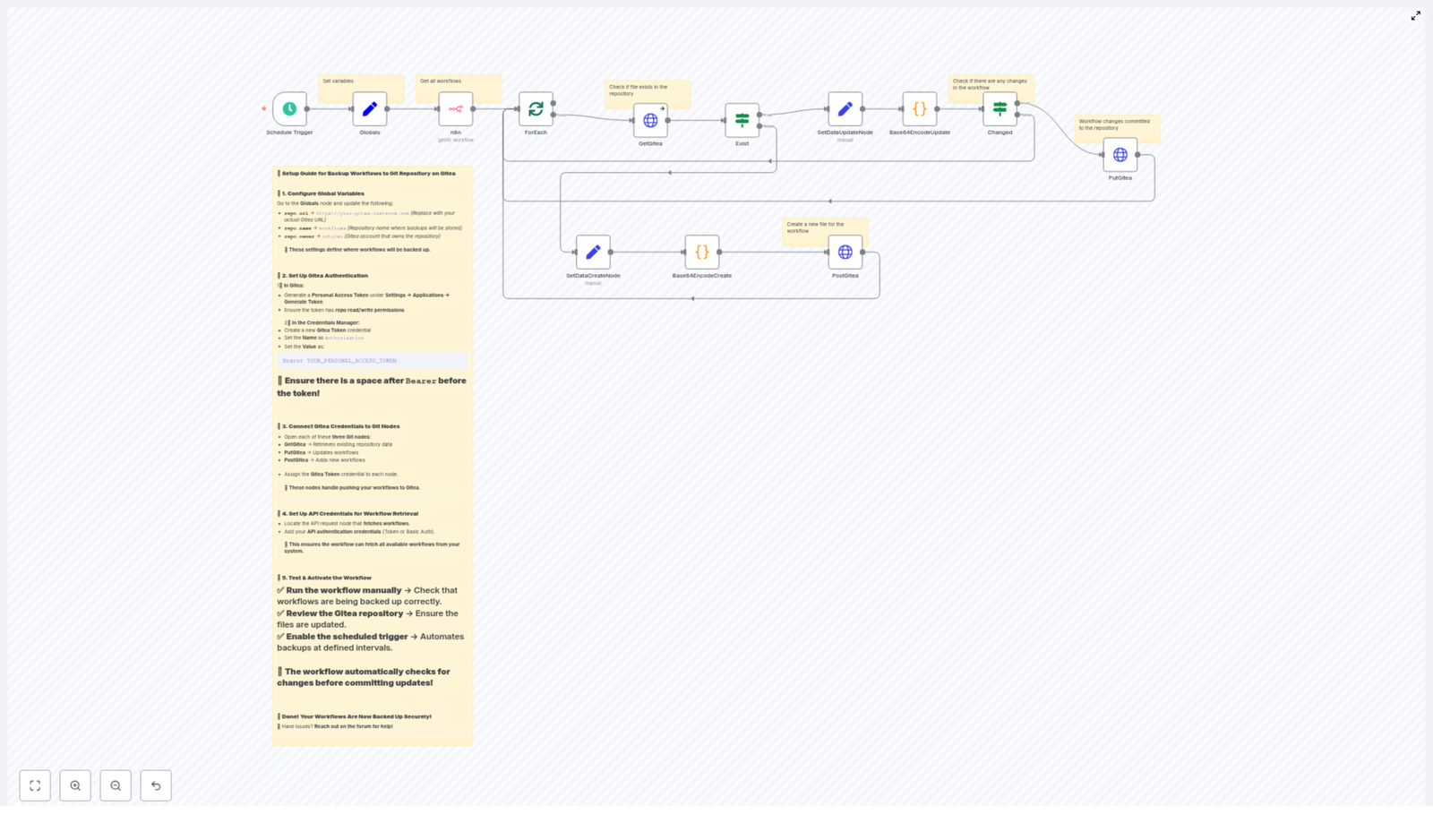
How the workflow fits together
Before we dive into the detailed steps in n8n, here is the overall pattern this template follows:
- Trigger the automation on a schedule (for example weekly at 8:00 AM)
- Call the Pinterest API to fetch pins (
/v5/pins) - Clean and tag the data so it is easy to analyze
- Upsert that data into Airtable for historical tracking
- Ask an AI agent to look for trends and suggest new pin ideas
- Summarize those ideas into a short, readable brief
- Deliver that brief to your marketing manager or team
Once you set this up, it quietly runs in the background and keeps your Pinterest strategy moving.
Step-by-step: building the n8n Pinterest workflow
1. Schedule the workflow
Start with a Schedule Trigger node in n8n. This is what controls how often your analysis runs.
Common choices:
- Weekly at 8:00 AM for content planning
- Bi-weekly if your volume is lower
In the example template, the trigger is set to run once a week at 8:00 AM, which fits neatly with most marketing planning cycles.
2. Fetch pin data from the Pinterest API
Next, add an HTTP Request node to call the Pinterest API. You will use a GET request to /v5/pins and authenticate with your Pinterest access token.
Basic configuration example:
GET https://api.pinterest.com/v5/pins
Header: Authorization: Bearer <YOUR_PINTEREST_ACCESS_TOKEN>Make sure you are requesting the fields that matter for analysis, such as:
idcreated_attitledescriptionlink- Any engagement metrics you can access (views, saves, clicks)
Those fields become the foundation for your Airtable records and AI insights.
3. Normalize and tag your pin data
Raw API responses are rarely analysis ready. This is where a small Code node comes in handy.
Use it to:
- Map Pinterest fields into a consistent, row-based structure for Airtable
- Tag each pin as Organic or Paid (or any other type labels you use)
- Ensure the schema is predictable so you can analyze it later without headaches
The goal is simple: every pin should fit into a clean, repeatable format.
4. Upsert pins into Airtable
Once your data is normalized, connect an Airtable node to store it. You will want to upsert rows, which means:
- Create new records for new pins
- Update existing records if the pin already exists
At minimum, track these fields in your Airtable base:
- pin_id (unique identifier)
- created_at
- title
- description
- link
- type (Organic / Paid)
- engagement metrics (views, saves, clicks) – when available
Over time, this turns Airtable into a living history of your Pinterest performance.
5. Let the AI agent analyze trends
Now for the fun part. With your Airtable records in place, you can point an AI agent at that dataset and ask it to behave like a marketing analyst.
A sample prompt you can use:
You are a marketing data analyst. Review the following pin records and identify 5 trend-based pin concepts that will reach our target audience. Consider top performers by saves and clicks, recurring keywords, post format, and posting time. For each suggested pin, include: idea title, one-sentence rationale, suggested keywords, and an ideal board or category.A helpful pattern is to use a two-stage AI flow:
- First, have the AI agent generate a structured list of suggested pins based on the Airtable data
- Then, feed that list into a second LLM that focuses on summarization and formatting for email or Slack
This keeps the output both smart and easy to read.
6. Deliver the results to your team
Finally, use an Email or Slack node to send the summarized recommendations to your marketing manager or content team.
Keep the message:
- Concise and scannable
- Actionable, with clear next steps
- Focused on a realistic number of ideas to execute
The end result is a small, high value brief instead of a wall of text.
What metrics should you track and why?
AI is only as good as the data you feed it. To get meaningful Pinterest recommendations, you will want to capture performance metrics over time. Useful metrics include:
- Impressions or views – tells you how often your pins are being discovered
- Saves – a strong intent signal on Pinterest and a key indicator of relevance
- Clicks / CTR – shows how well pins drive traffic or deeper engagement
- Audience or comment sentiment – gives qualitative feedback that can shape creative direction
Feeding these metrics into your Airtable base and AI analysis ensures that your content suggestions are tied to real performance, not just vague creative ideas.
Prompting tips for better AI content suggestions
Want your AI agent to feel less generic and more like a sharp strategist on your team? A few prompt tweaks go a long way.
- Define success clearly For example, tell the AI you want to increase saves by 20 percent or improve CTR, not just “perform better.”
- Ask for specific outputs Request a headline, short description, 3 keywords, suggested image style, and a posting schedule for each idea.
- Limit the number of ideas 5 to 7 pin ideas per run is usually enough to keep your team focused instead of overwhelmed.
- Include examples Share a few high performing pins as reference so the AI can mirror style, tone, and format.
Think of your prompt as the creative brief you would give a human strategist. The clearer it is, the better the output.
Best practices when scaling this workflow
As your Pinterest account grows, your automation should grow with it. Here are some practical tips:
- Store raw API responses alongside the normalized Airtable fields so you can reprocess data if Pinterest changes its schema.
- Version your AI prompts and keep a small changelog. That way you can track which prompt versions lead to better ideas or higher performance.
- Respect API limits by paginating results and keeping an eye on rate usage, especially for large accounts.
- Add a confidence or priority tag to AI suggestions so designers and marketers know which ideas to tackle first.
These small habits make the workflow more resilient and easier to maintain long term.
Sample n8n node mapping (conceptual)
If you are more visual, here is a quick conceptual map of the node sequence used in the template:
- Schedule Trigger (weekly)
- HTTP Request GET
https://api.pinterest.com/v5/pins - Code node to map, normalize, and tag results
- Airtable upsert node to store pin metadata and metrics
- AI Agent node for analysis and content suggestions
- Summarization LLM node to create an email-ready brief
- Email (or Slack) node to send the final summary
You can adapt or extend this sequence based on your stack, but this gives you a solid starting structure.
Security and privacy tips
Since this workflow touches APIs and potentially user-generated content, it is worth treating security carefully:
- Store your Pinterest and AI credentials securely in n8n, not in plain text inside nodes.
- Scope tokens to only the endpoints and permissions you actually need.
- Rotate tokens on a regular schedule as part of your security hygiene.
- When sending summaries via email or Slack, avoid including any personally identifiable information (PII) from comments or user profiles.
This keeps your automation both useful and compliant with privacy best practices.
What the marketing manager actually receives
So what does the output look like in real life? Here is a simple example of the kind of brief your manager might get:
Top trends: short how-to graphics and list-style pins get the most saves. Suggested pins: “10-Minute Meal Prep” (idea + image direction + 3 keywords), “Quick Workouts for Busy Parents” (idea + board), “Before & After DIY” (idea + rationale). Schedule: post Tue/Thu mornings. Priority: 3 new short-form pins this week.
In a few lines, they can see what is working, what to create next, and when to publish it.