Build a Discord Guild Welcome Bot with n8n & Weaviate
Automating welcome messages for new Discord guild members is a powerful way to create a friendly first impression and standardize onboarding. In this guide you will learn, step by step, how to build a smart Discord welcome bot using:
- n8n for workflow automation
- OpenAI embeddings for semantic search
- Weaviate as a vector database
- Hugging Face chat models for natural language
- Google Sheets for logging and analytics
The workflow you will build listens to Discord events, processes and stores onboarding content as vectors, retrieves relevant context for each new member, generates a personalized welcome message, and logs the interaction for later review.
Learning Goals
By the end of this tutorial you should be able to:
- Explain how embeddings and a vector store help create context-aware Discord welcome messages
- Configure an n8n webhook to receive Discord guild member join events
- Split long onboarding documents into chunks suitable for embedding
- Store and query embeddings in Weaviate with guild-specific metadata
- Use an agent pattern in n8n to combine tools, memory, and a Hugging Face chat model
- Log each welcome event to Google Sheets for monitoring and analytics
Concepts You Need To Know
n8n Workflow Basics
n8n is a workflow automation tool that lets you connect APIs and services using nodes. Each node performs a specific task, such as receiving a webhook, calling an API, or writing to a Google Sheet. In this tutorial, you will chain nodes together to create a complete Discord welcome workflow.
Embeddings and Vector Stores
Embeddings are numerical representations of text that capture semantic meaning. Similar pieces of text have similar vectors. You will use OpenAI embeddings to convert guild rules, onboarding guides, and welcome templates into vectors.
Weaviate is a vector database that stores these embeddings and lets you run similarity searches. When a new member joins, the bot will query Weaviate to find the most relevant chunks of content for that guild.
Agent Pattern in n8n
The workflow uses an agent to orchestrate several components:
- A tool for querying Weaviate
- A memory buffer for short-term context
- A chat model from Hugging Face to generate the final welcome text
This agent can decide when to call the vector store, how to use past context, and when to log events.
Why This Architecture Works Well
This setup lets your bot:
- Reference current server information such as rules, channels, and roles
- Handle multiple guilds with different onboarding content
- Keep a short history of interactions to avoid repetitive messages
- Log each welcome event to Google Sheets for transparency and analysis
Using embeddings and Weaviate gives you semantic recall of your latest docs, while the agent pattern provides flexibility in how the bot uses tools and context.
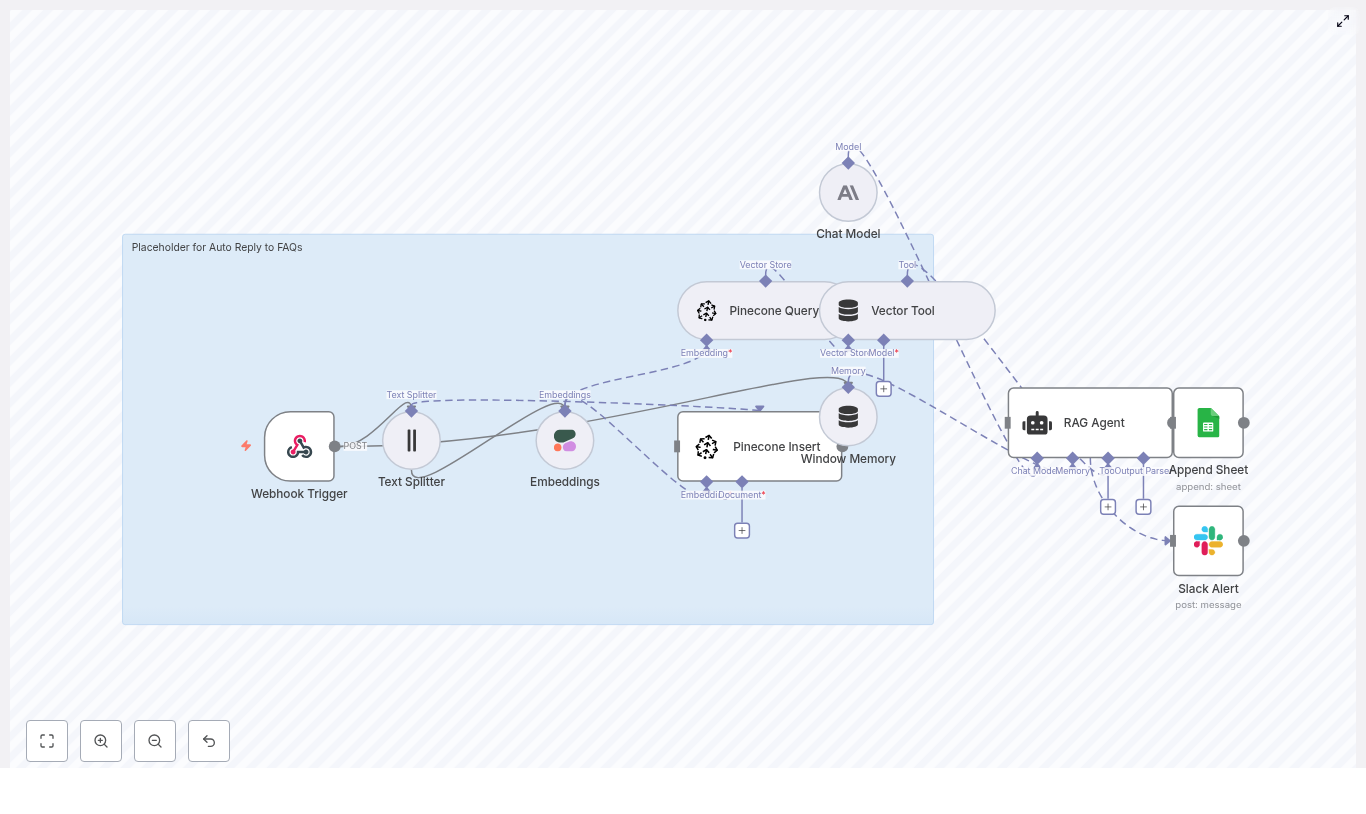
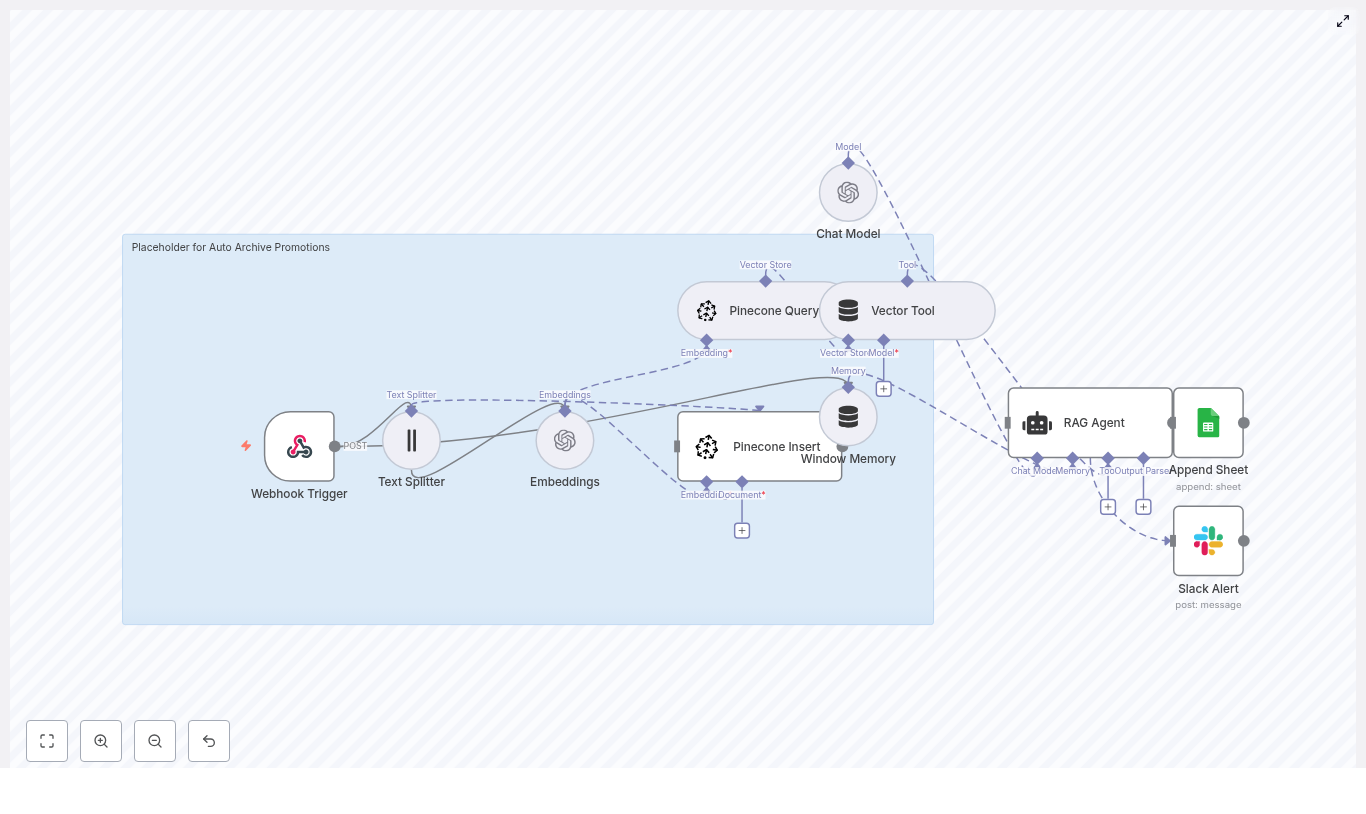
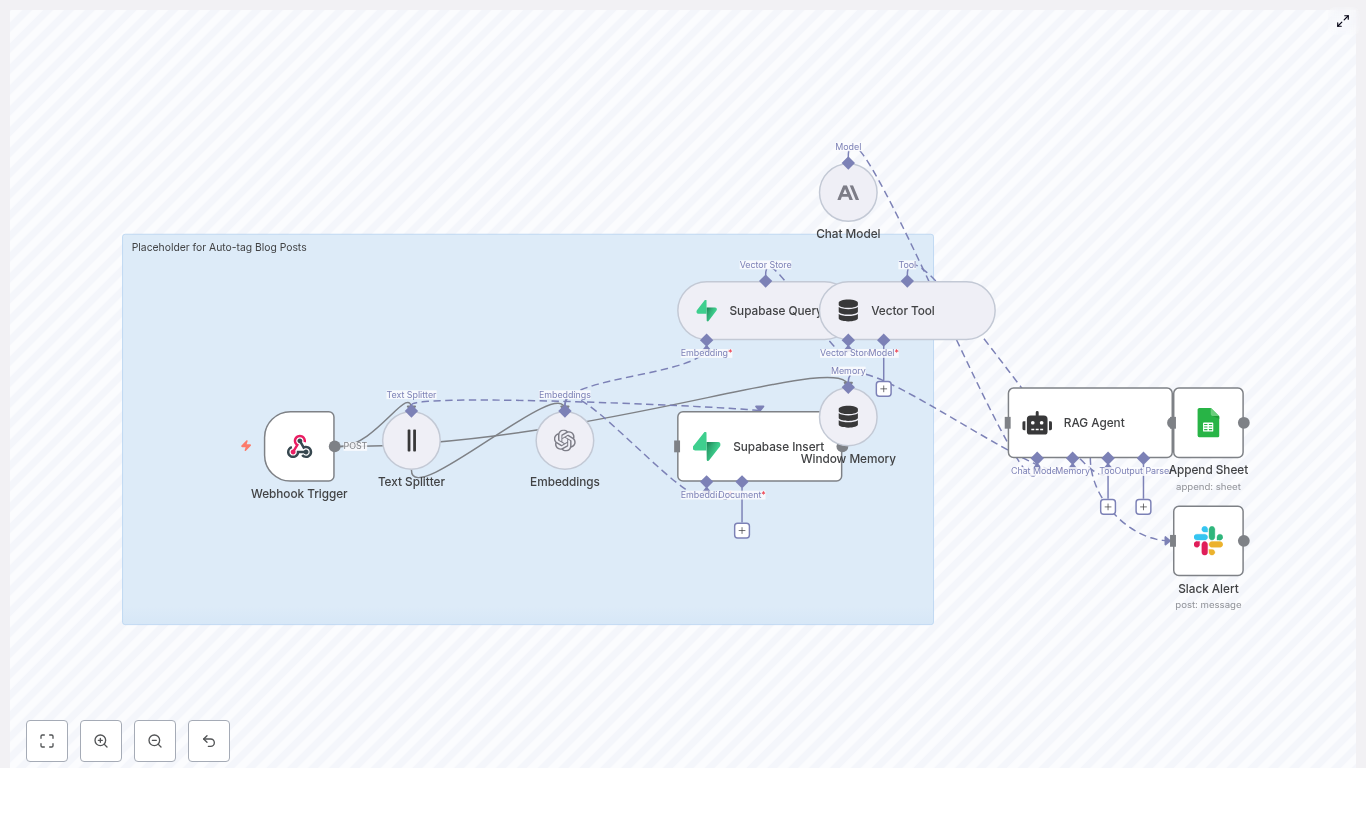
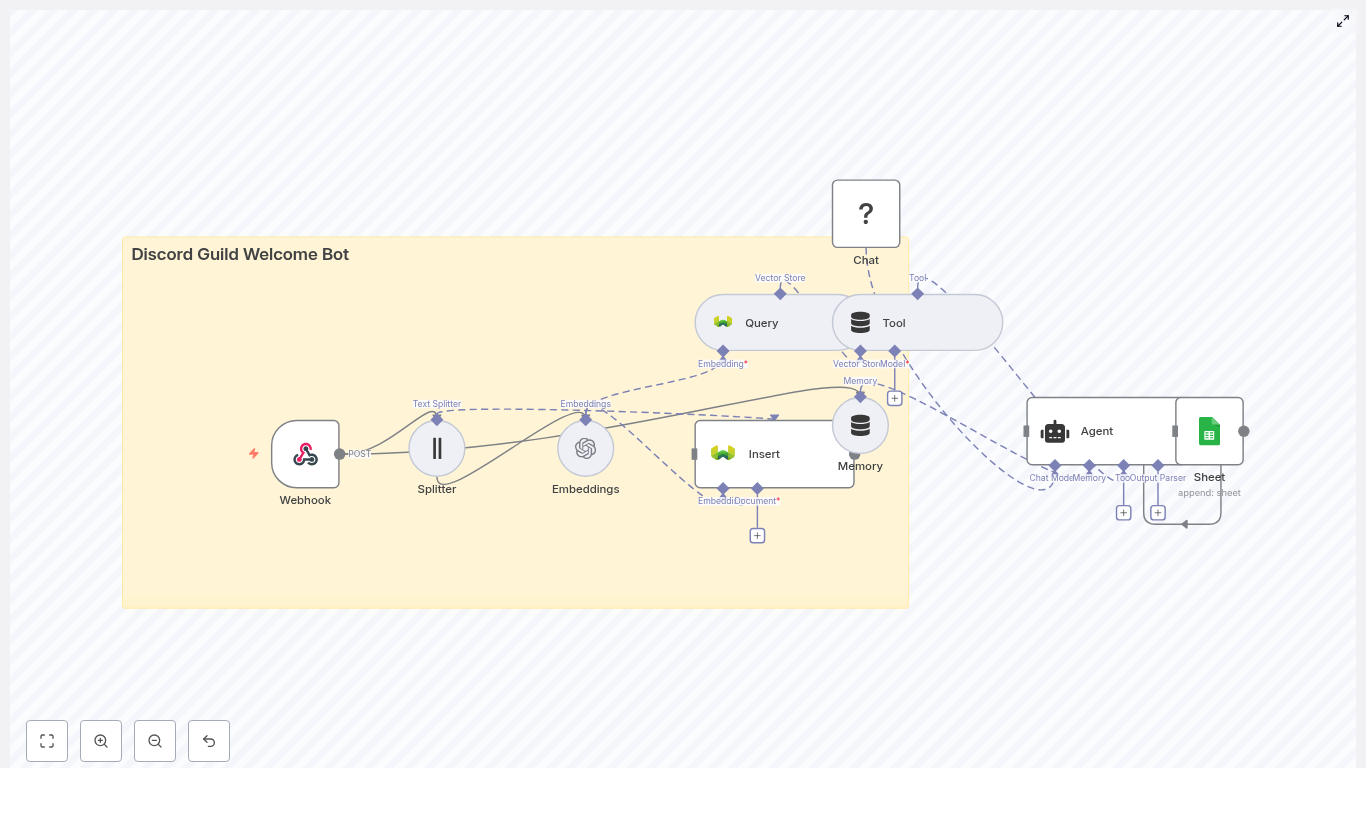
High-Level Architecture
Before you build the workflow, it helps to see how the pieces connect. The core components are:
- Webhook (n8n) – receives Discord gateway events or events from an intermediary service
- Text Splitter – breaks long onboarding texts into manageable chunks
- Embeddings (OpenAI) – converts chunks into vectors
- Weaviate Vector Store – stores embeddings and supports similarity search
- Query Tool – exposes Weaviate queries as a tool the agent can call
- Memory Buffer – stores short-term context for the agent
- Chat Model (Hugging Face) – generates the welcome message
- Agent – coordinates tools, memory, and the chat model
- Google Sheets – logs each welcome event
Next, you will walk through each part in a teaching-friendly, step-by-step order.
Step 1 – Capture Discord Events with an n8n Webhook
1.1 Configure the Webhook Node
First, set up a Webhook node in n8n. This will be the entry point for your workflow whenever a new member joins a Discord guild.
You can either:
- Send Discord gateway events directly to the n8n webhook, or
- Use a lightweight intermediary such as a Cloudflare Worker or a minimal server that receives the Discord event, simplifies the payload, and forwards it to n8n
1.2 Example Payload
A simplified JSON body that your webhook might receive could look like this:
{ "guild_id": "123456789", "user": { "id": "987654321", "username": "newcomer" }, "joined_at": "2025-08-01T12:34:56Z"
}
Make sure your webhook is configured to parse this payload so the rest of the workflow can access guild_id, user.id, user.username, and joined_at.
Step 2 – Prepare Onboarding Content with a Text Splitter
2.1 Why Split Text?
Guild rules, welcome guides, or onboarding documents are usually longer than what an embedding model can handle at once. Splitting these documents into chunks makes them easier to embed and improves search quality.
2.2 Recommended Split Settings
Use a Text Splitter node in n8n to break your content into overlapping chunks. A good starting configuration is:
- Chunk size: about 400 characters
- Chunk overlap: about 40 characters
The overlap helps preserve context between chunks so that important sentences are not cut in a way that loses meaning. This leads to better semantic search results later when you query Weaviate.
Step 3 – Create Embeddings with OpenAI
3.1 Configure the Embeddings Node
Next, connect the Text Splitter output to an OpenAI Embeddings node.
- Store your OpenAI API key in n8n credentials for security
- Select a robust embedding model such as
text-embedding-3-smallor the latest recommended model in your account - Map each text chunk from the splitter node into the embeddings node input
The node will output vector representations for each chunk. These vectors are what you will store in Weaviate.
Step 4 – Store Embeddings in Weaviate
4.1 Designing the Weaviate Schema
Set up a Weaviate collection to store your guild onboarding content. For example, you might use an index name such as:
discord_guild_welcome_bot
Each document stored in Weaviate should include:
guild_id– to identify which guild the content belongs tosource– for example “rules”, “welcome_guide”, or “faq”chunk_index– an integer to track the position of the chunk in the original document- The actual text content and its embedding vector
4.2 Inserting Data
Use an n8n node that connects to Weaviate and inserts each chunk plus its embedding into the discord_guild_welcome_bot index. Make sure your Weaviate credentials and endpoint are correctly configured in n8n.
Once this step is complete, your guild rules and onboarding docs are stored as searchable vectors.
Step 5 – Query Weaviate as a Tool for the Agent
5.1 When to Query
When a new member joins, the workflow needs to retrieve the most relevant content for that guild. You will configure a query node that runs a similarity search in Weaviate based on the guild ID.
5.2 Filtering by Guild
In your Weaviate query, use a metadata filter on guild_id to ensure that only content for the current guild is returned. This is crucial if you plan to support multiple guilds in the same Weaviate instance.
5.3 Expose the Query as a Tool
Wrap the Weaviate query in a tool that your agent can call. For example, the tool might be described as:
- “Retrieve the top N relevant onboarding chunks for a given guild.”
The agent can then ask something like, “What should I mention in the welcome message for this guild?” and use the tool to get domain-specific context when needed.
Step 6 – Add a Memory Buffer for Context
6.1 Why Use Memory?
Short-term memory helps your bot avoid repetitive responses and maintain continuity in multi-step interactions, such as when a moderator follows up with the bot after the initial welcome.
6.2 What to Store
Configure a Memory Buffer in your agent setup to keep recent conversation snippets, such as:
- The last welcome message sent
- The new member’s primary role or tags
Keep the memory window small so it remains efficient but still useful for context.
Step 7 – Connect a Hugging Face Chat Model
7.1 Choosing a Model
Use a Hugging Face conversational model or any chat-capable model supported by n8n. The model will generate the final welcome message, using the retrieved context from Weaviate and the information from the webhook.
7.2 Prompting Strategy
Keep your prompts clear and instructive. You can use a system prompt pattern like this:
System: You are an assistant that writes warm, concise Discord welcome messages.
Keep messages under 120 words and include the server's top 2 rules
and a link to the #start-here channel when available.
User: New user data + retrieved context chunks
Assistant: [Polished welcome message]
Pass the context chunks, guild metadata (name, rules, onboarding links), and the new user information into the model. Your agent can also instruct the model to produce a source list or reference the chunks used, which is helpful if moderators review the message later.
Step 8 – Orchestrate with an Agent and Log to Google Sheets
8.1 Agent Flow in n8n
The agent node is responsible for coordinating the entire process. Its typical flow looks like this:
- Receive the webhook payload with
guild_id,user.id, anduser.username - Call the Weaviate query tool if additional context is needed
- Consult the memory buffer for recent interactions
- Send all relevant data to the Hugging Face chat model to generate the welcome message
- Return the final message to be posted to Discord or passed to another system
8.2 Logging with Google Sheets
To keep an audit trail and enable analytics, add a Google Sheets node at the end of the workflow. Configure it to append a new row for each welcome event with fields such as:
- Timestamp
guild_iduser_idmessage_preview(for example, the first 80-100 characters of the welcome message)
This log will help you track bot activity, monitor message quality, and analyze onboarding trends over time.
Configuration Tips and Best Practices
- Security: Never expose API keys in plain text. Use n8n credential stores and protect your webhook with a secret token or short-lived signature.
- Rate limits: Respect Discord and external API rate limits. Batch operations where possible and implement retry or backoff strategies in n8n.
- Guild filtering: Always filter Weaviate queries by
guild_idso that content stays relevant and separated between servers. - Chunking strategy: Adjust chunk size and overlap for different content types. For example, rule-heavy or code-heavy docs may benefit from slightly different chunk settings than FAQ-style text.
- Explainability: Store source chunk IDs or short excerpts alongside generated messages. This helps moderators understand why certain information was included.
Testing and Monitoring Your Workflow
Testing Steps
Before using the bot in a production guild, test it thoroughly:
- Use a sandbox or test guild and send sample webhook events to n8n
- Verify that the Text Splitter creates reasonable chunks
- Confirm that embeddings are being created and inserted into Weaviate correctly
- Check that Weaviate queries return relevant chunks for the test guild
- Run the agent end to end and inspect the generated welcome message
- Ensure that each event is logged correctly in Google Sheets
Ongoing Monitoring
Monitor your workflow logs for:
- Failed API calls or timeouts
- Embedding quality issues (for example, irrelevant chunks being returned)
- Changes in guild rules or docs that require re-indexing or refreshing embeddings
Scaling and Advanced Extensions
- Multi-guild support: Use separate Weaviate collections or metadata-scoped indices for each guild to keep queries fast and isolated.
- Personalized welcomes: Incorporate roles, interests, or onboarding survey results to tailor messages to each new member.
- Follow-up automation: Trigger delayed messages, such as a 24-hour check-in, using the same agent and memory setup.
- Analytics: Use the Google Sheets log or export data to BigQuery to analyze acceptance rates, message edits, and moderator overrides.
Quick FAQ and Recap
What does this n8n workflow actually do?
It receives a Discord join event, retrieves relevant onboarding content from Weaviate using embeddings, generates a personalized welcome message with a Hugging Face chat model, and logs the interaction to Google Sheets.
Why use embeddings and Weaviate instead of static messages?
Embeddings and a vector store let the bot dynamically reference up-to-date rules, channels, and guild-specific documents, which makes welcome messages more accurate and context-aware.
Can this setup handle multiple Discord guilds?
Yes. By tagging content with guild_id and filtering queries accordingly, the same workflow can serve multiple guilds with different onboarding content.
How do I keep the bot’s knowledge current?
Whenever you update rules or onboarding docs, re-run the splitting and embedding steps for that guild and re-insert or update the vectors in Weaviate.
Where are events logged?
Each welcome event is appended to a Google Sheets spreadsheet with key fields like timestamp, guild ID, user ID, and a message preview.
Conclusion and Next Steps
By combining n8n with OpenAI embeddings, Weaviate, a Hugging Face chat model, and Google Sheets, you can build a smart, context-aware Discord welcome bot that scales across multiple guilds and remains easy to manage.
This architecture provides:
- Semantic recall of your latest server documentation