Sync HubSpot Contacts to Mailchimp with n8n (So You Never Export a CSV Again)
Picture this: it is 6:55 AM, you are on your second coffee, and your day starts with the classic routine – export contacts from HubSpot, clean the CSV, import into Mailchimp, fix a random column mismatch, and hope no one unsubscribed in the meantime. Glamorous? Not exactly.
Now imagine this instead: at 07:00 every morning, your contacts quietly sync from HubSpot to Mailchimp while you do literally anything else. That is what this n8n workflow template gives you – a simple, no-code automation that grabs new HubSpot contacts every day and drops them straight into your Mailchimp audience with first and last names neatly mapped.
In this guide, you will see what the workflow does, how it works under the hood, and how to set it up in n8n without writing custom code. We will also look at a few improvements, like handling duplicates, errors, and rate limits, so your automation behaves like a pro and not like a rushed copy-paste job.
What This n8n Workflow Actually Does
This workflow is all about keeping HubSpot and Mailchimp in sync so your marketing list is always fresh without you lifting a finger. Once configured, it will:
- Run every day at 07:00 (server time) using a Cron trigger.
- Search HubSpot for contacts created in the last 24 hours using the
createdateproperty. - Send each new contact to Mailchimp as a subscriber in your chosen audience (list).
- Map the contact’s email, first name, and last name into Mailchimp merge fields.
The result: your HubSpot CRM and Mailchimp email marketing stay aligned, your onboarding flows hit the right people, and you never have to touch that cursed “Export CSV” button again.
Why Automate HubSpot To Mailchimp Syncs?
If your team uses HubSpot as the CRM and Mailchimp for newsletters or campaigns, you probably already know the pain of manual syncing. It is not just boring, it is risky:
- Time sink – exporting and importing contacts every day or week adds up fast.
- Error magnet – wrong columns, outdated lists, and missing fields sneak in easily.
- Stale data – new leads might miss campaigns or onboarding sequences altogether.
Automating the sync with n8n fixes all of that. You get up-to-date contacts in Mailchimp, fewer mistakes, and more time for things that do not involve spreadsheets.
What You Will Have by the End
By the time you finish this setup, you will have a working n8n workflow that:
- Triggers daily at 07:00 using a Cron node.
- Uses a HubSpot (Search Contacts) node to pull contacts created in the last 24 hours.
- Uses a Mailchimp (Create Member) node to add each contact to your Mailchimp audience with proper merge field mapping.
It is a small, three-node workflow that quietly does the job of a very patient assistant who never forgets and never complains.
What You Need Before You Start
Before you jump into n8n and start dragging nodes around, make sure you have:
- An n8n instance (self-hosted or n8n.cloud).
- A HubSpot account with OAuth2 credentials already connected to n8n.
- A Mailchimp account with OAuth2 credentials and the ID of the target audience (list) where you want to add subscribers.
- Basic familiarity with n8n nodes, expressions, and how to edit node parameters.
Once those are in place, you are ready to build the workflow.
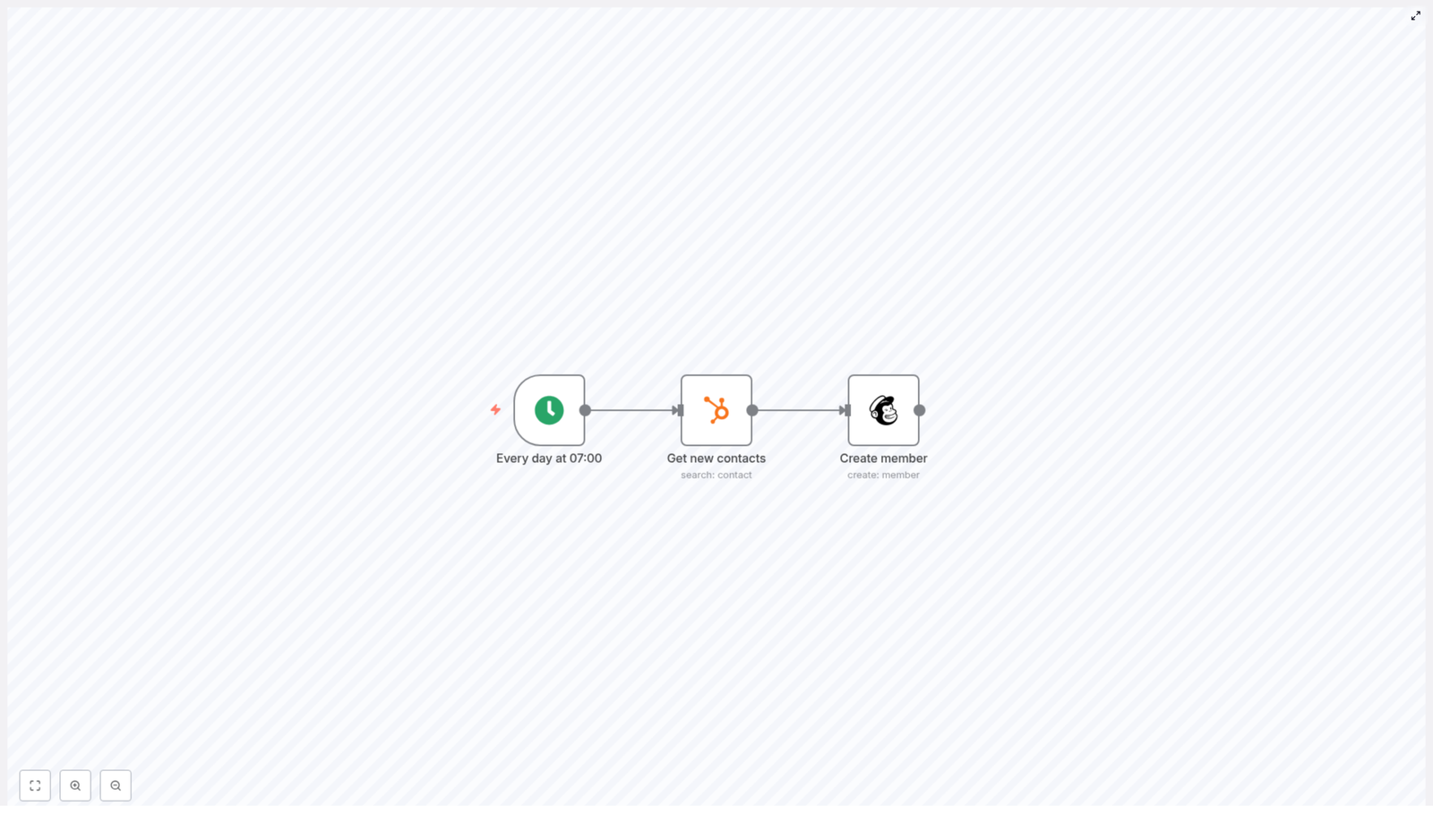
High-Level Workflow Overview
The workflow is intentionally minimal so it is easy to understand and extend later. It uses just three nodes:
- Cron – Triggers the workflow every day at 07:00.
- HubSpot (Search Contacts) – Searches for contacts whose
createdateis between “yesterday at this time” and “now”. - Mailchimp (Create Member) – Adds each contact as a member in your Mailchimp audience and maps first name and last name to merge fields.
That is it. No loops, no complicated logic, just a clean daily sync between HubSpot and Mailchimp.
Step-by-Step: Building the Workflow in n8n
1. Create the Daily Cron Trigger
First, you want the workflow to run on its own without your supervision, like a responsible adult process.
- Drag a Cron node onto the canvas in n8n.
- Set it to run every day at 07:00 (based on your n8n server timezone).
This Cron node is the alarm clock for your sync. Once a day at 07:00, it will wake up the rest of the workflow.
2. Configure the HubSpot Search Contacts Node
Next, you will tell HubSpot, “Show me everyone who joined in the last 24 hours.”
- Add a HubSpot node and connect it after the Cron node.
- Set Resource to
contact. - Set Operation to
search. - Configure filters so you only get contacts whose
createdateis within the past 24 hours.
You can use n8n expressions to define this time window. For example:
// In the HubSpot node filters
filters: [ { propertyName: 'createdate', operator: 'GTE', value: '={{$today.minus({day:1}).toMillis()}}' }, { propertyName: 'createdate', operator: 'LT', value: '={{$today.toMillis()}}' }
]
These expressions evaluate to millisecond timestamps for “24 hours ago” and “now”. If you ever want to get fancy and sync more often, you can adjust that window for hourly syncs or a different schedule.
3. Add the Mailchimp Create Member Node
Now that you have a list of new contacts from HubSpot, it is time to send them to Mailchimp.
- Add a Mailchimp node after the HubSpot node.
- Set the operation to create member.
- Map the email and name fields from the HubSpot contact into Mailchimp.
A typical configuration looks like this:
email: ={{ $json["properties"].email }}
merge fields: FNAME: ={{ $json["properties"].firstname }} LNAME: ={{ $json["properties"].lastname }}
list: YOUR_MAILCHIMP_LIST_ID
Replace YOUR_MAILCHIMP_LIST_ID with your actual Mailchimp audience ID. In the example template, you will see 8965eba136 used as a placeholder.
Once this is set, each HubSpot contact flows into Mailchimp with their email, first name, and last name mapped to the right merge fields.
Testing the Workflow Before You Trust It
Before you let this workflow run unattended, it is worth doing a quick test so you do not accidentally spam the wrong list or mis-map fields.
- Temporarily change the Cron node to trigger a few minutes in the future, or run the workflow manually.
- Make sure you have at least one recent HubSpot contact that matches the filter.
- Run the workflow and inspect the data coming out of the HubSpot node.
- Check Mailchimp to confirm:
- The new subscriber appears in the correct audience.
- Email, first name, and last name are correctly populated in the merge fields.
Once everything looks good, set the Cron node back to the daily 07:00 schedule and activate the workflow.
Example Workflow JSON Template
If you prefer to start from a ready-made configuration instead of building from scratch, here is a minimal example of the workflow used in this guide. You can import it into n8n, then update credentials and list IDs as needed.
{ "nodes": [ { "name": "Every day at 07:00", "type": "cron", "parameters": {"triggerTimes": {"item": [{"hour": 7}] } } }, { "name": "Get new contacts", "type": "hubspot", "parameters": { "resource": "contact", "operation": "search", "filterGroupsUi": { "filterGroupsValues": [{ "filtersUi": { "filterValues": [ { "value": "={{$today.minus({day:1}).toMillis()}}", "operator": "GTE", "propertyName": "createdate" }, { "value": "={{$today.toMillis()}}", "operator": "LT", "propertyName": "createdate" } ] } }] } } }, { "name": "Create member", "type": "mailchimp", "parameters": { "list": "8965eba136", "email": "={{ $json[\"properties\"].email }}", "status": "subscribed", "mergeFieldsUi": { "mergeFieldsValues": [ { "name": "FNAME", "value": "={{ $json[\"properties\"].firstname }}" }, { "name": "LNAME", "value": "={{ $json[\"properties\"].lastname }}" } ] } } } ]
}
Remember to replace the placeholder Mailchimp list ID and connect your own HubSpot and Mailchimp credentials before activating it.
Leveling Up: Tips To Make Your Sync More Robust
Preventing Duplicate Subscribers
Mailchimp identifies subscribers by email, which is great until you accidentally try to add the same address twice and get a faceful of 400 or 409 errors.
To avoid that, you can:
- Add a preliminary Mailchimp get member call to check if the email already exists. If it does, decide whether to update or skip.
- Ensure the status field in the Mailchimp node is set correctly, for example
subscribedorpending, depending on your flow. - Handle Mailchimp errors gracefully so a single duplicate does not break the whole run.
Handling Errors and Retries
APIs sometimes fail, networks occasionally wobble, and rate limits can surprise you. Instead of letting your workflow silently fail, you can:
- Enable the workflow’s Error Trigger in n8n to catch failures.
- Send alerts to Slack, email, or logging tools when something goes wrong.
- Use the Mailchimp node’s response handling to log failed requests.
- Implement an exponential backoff retry strategy if you expect rate limits or intermittent errors.
Dealing With Rate Limits and Large Volumes
If you only get a handful of new contacts each day, you are probably fine. If you are dealing with hundreds or thousands, both HubSpot and Mailchimp rate limits start to matter.
To keep things smooth:
- Use n8n’s SplitInBatches node to process contacts in chunks.
- Add a small delay between batches to stay comfortably under API quotas.
- Monitor your daily volumes so you know when it is time to tweak batching or scheduling.
Timezone and Server Clock Gotchas
The Cron node uses the timezone of your n8n server. If your workflow runs at a weird time, it might not be your imagination, it might be your container.
- If you are running n8n in a container, make sure the container timezone matches the schedule you want.
- On n8n.cloud, you can use Cron expressions with timezone awareness for more control.
Security and Best Practices
Even though this workflow is simple, it still touches personal data and API credentials, so a bit of hygiene goes a long way.
- Store OAuth2 credentials in n8n’s credentials manager, not in plain text or node parameters.
- Use least-privilege API access and rotate credentials regularly based on your security policy.
- Log actions and errors for debugging, but avoid dumping full PII into unsecured logs.
Wrapping Up: Let the Robots Handle the Repetitive Stuff
With a simple Cron → HubSpot search → Mailchimp create flow, you can keep your email lists in sync automatically, without daily exports or messy imports. n8n handles the boring part so you can focus on campaigns, content, and strategy instead of CSV gymnastics.
Once this workflow is running, you can extend it with better error handling, batching for higher volumes, or additional logic like segmenting contacts based on properties.
Next Steps
Ready to retire that manual sync ritual?
- Deploy this workflow in your n8n instance.
- Update credentials and your Mailchimp list ID.
- Run a test, confirm everything looks good, then activate it.
If you need a more customized setup or want help scaling this workflow, reach out to your team, automation partner, or subscribe to more n8n tutorials and resources to keep leveling up your automations.