Backup n8n Workflows to Gitea (So You Never Lose a Flow Again)
Imagine this: you finally perfect that beautiful n8n workflow that glues half your tech stack together. It runs like a dream, you feel like an automation wizard… and then an accidental delete, a broken instance, or a bad edit turns it into a distant memory. Rebuilding from scratch is not just annoying, it is the kind of repetitive task that automation was supposed to save you from.
This is where backing up your n8n workflows to Gitea comes in. With a simple n8n workflow template, you can automatically export all your workflows into a Gitea Git repository on a schedule. It checks what is already there, only updates files when something really changed, and keeps everything in neat JSON files that you can version, review, and restore whenever needed.
In other words: set it up once, let it quietly back up your automation brain, and stop worrying about “oops” moments.
Why back up n8n workflows to Gitea instead of “hoping for the best”?
Storing n8n workflows in a Gitea Git repository gives you all the good stuff developers enjoy, without you having to manually export anything every week.
- Version history for changes and rollbacks – See what changed, when, and by whom, and roll back if a “quick tweak” goes badly.
- Secure, centralized storage – Gitea is self-hosted, which means your workflow JSON lives in your own infrastructure, not on someone else’s laptop.
- Automated, scheduled snapshots – No more “I will export this later” promises that never happen. The workflow runs for you at a set interval.
- Easy collaboration and review – Use Git features like diffs, pull requests, and code review to track and discuss workflow changes.
So instead of manually exporting JSON files like it is 2009, you let n8n and Gitea do the boring work on repeat.
What this n8n backup workflow actually does
The template is a fully automated backup pipeline for your n8n instance. At a high level, it:
- Runs on a schedule (for example, every 45 minutes).
- Fetches all workflows from your n8n instance through the n8n API.
- Loops through each workflow one by one.
- Checks in Gitea if a JSON file already exists for that workflow.
- If the file exists, it compares contents and only updates the file if something actually changed.
- If the file does not exist, it creates a brand new JSON file in the repository.
The end result is a clean, versioned collection of .json files in Gitea that mirror your n8n workflows, updated on a schedule without you lifting a finger.
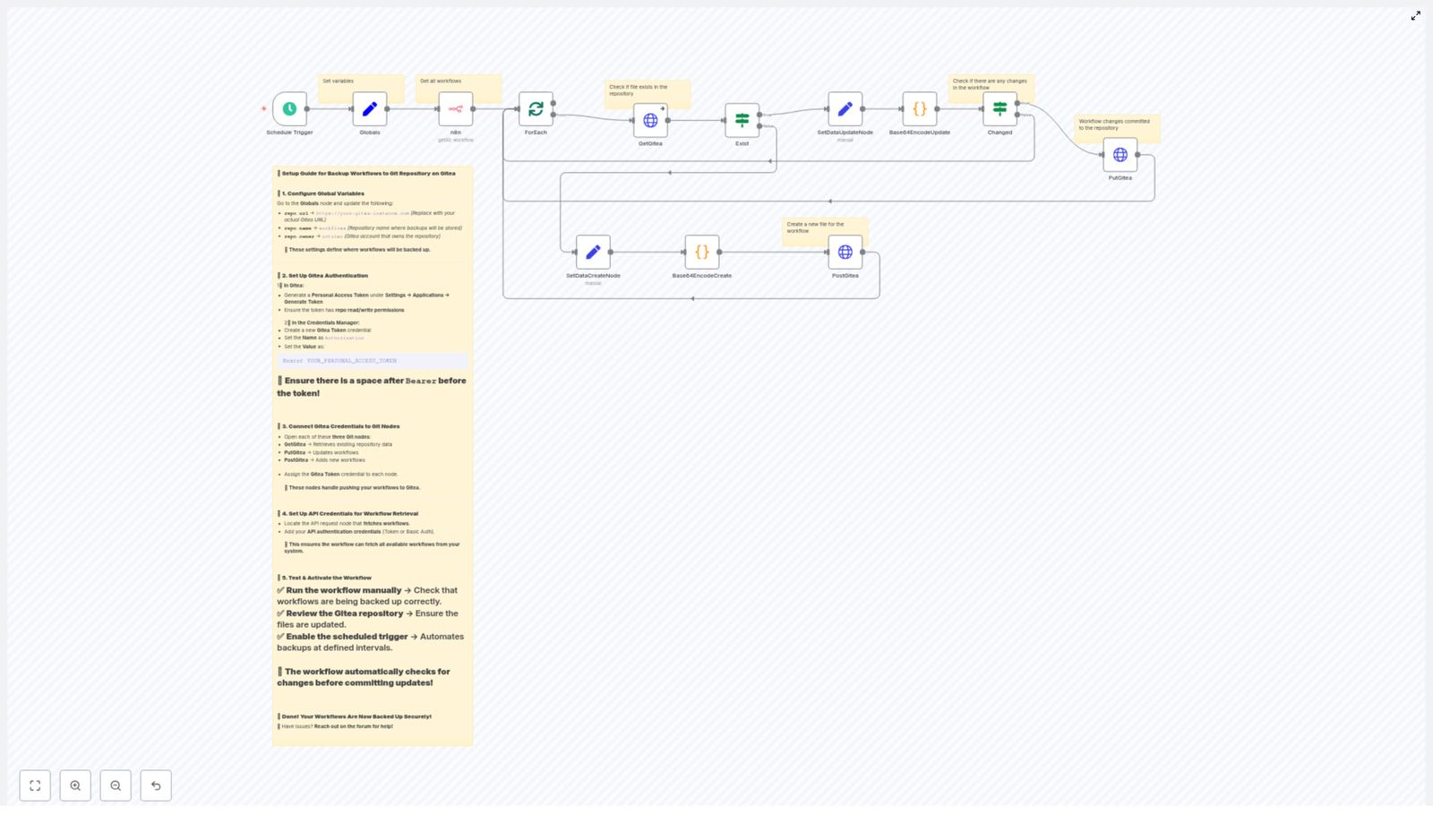
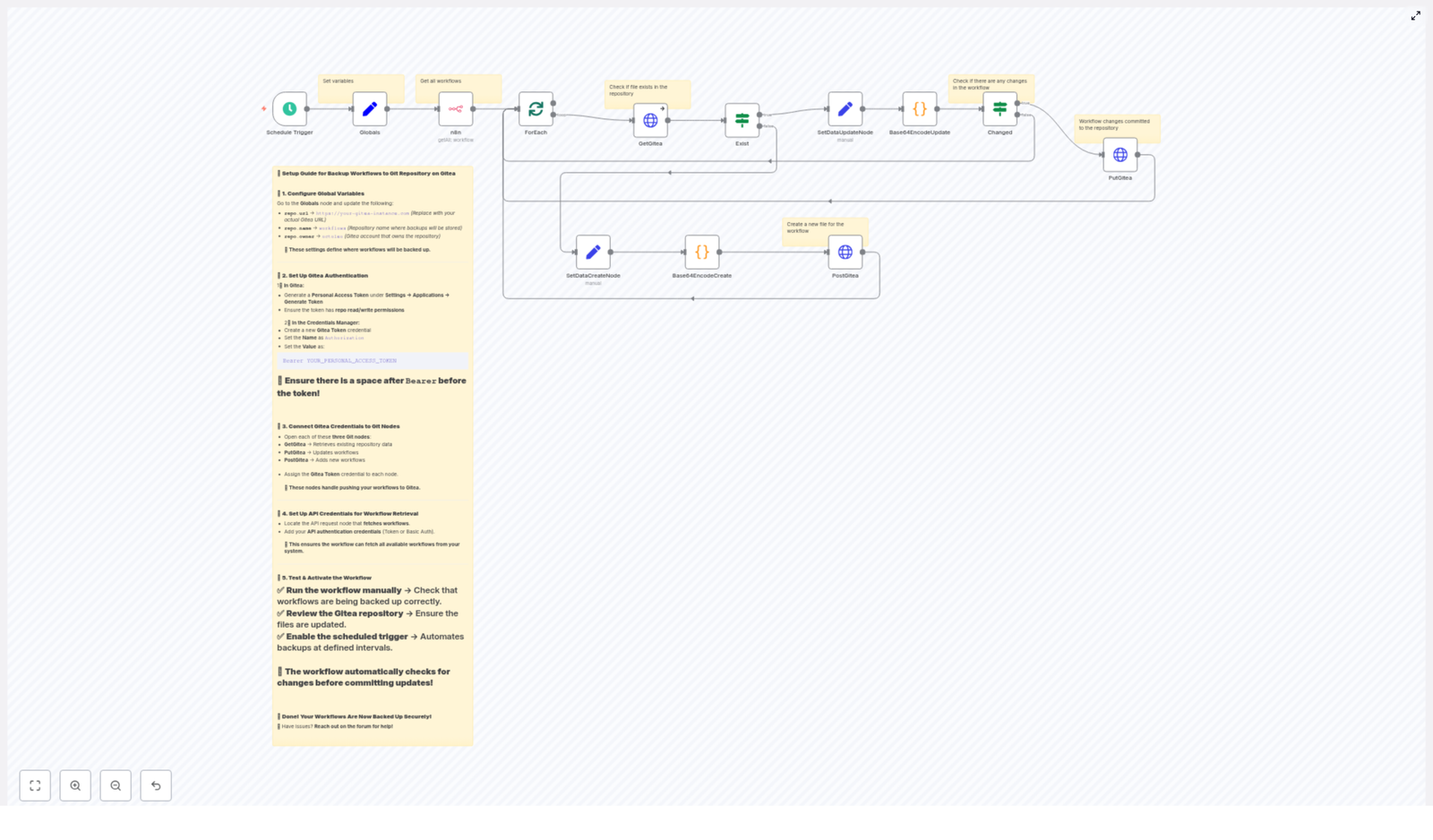
How the backup flow is structured (high-level logic)
Here is the general flow from start to finish:
- Schedule Trigger wakes up the workflow at your chosen interval.
- Globals stores handy variables like Gitea URL, repo owner, and repo name so you do not repeat them everywhere.
- n8n API node fetches all workflows from your n8n instance.
- splitInBatches / ForEach processes each workflow as an individual item.
- GetGitea checks if the corresponding JSON file already exists in Gitea.
- Exist (If node) branches into “file exists” or “file does not exist.”
- Base64EncodeCreate / Base64EncodeUpdate encode the workflow JSON into base64, ready for the Gitea API.
- Changed (If node) compares the new base64 content with what is already in the repo.
- PostGitea creates new files, and PutGitea updates existing ones when there are actual changes.
It is basically a polite robot that checks “Do I need to change anything?” before touching your Git history.
Key n8n nodes in this template (and what they do)
Schedule Trigger: the “set and forget” starter
The Schedule Trigger node is what kicks off the backup at regular intervals. In the example template, it is configured to run every 45 minutes, but you can tweak that based on how often your workflows change and how much history you want.
You might choose:
- Every few minutes for very active environments.
- Once or twice a day for more stable setups.
Pick a schedule that matches your recovery needs and storage comfort level.
Globals: one place for all your Gitea settings
The Globals node keeps your repository details in one tidy location so you do not repeat them across nodes or risk typos.
It typically stores values like:
repo.url– for example,https://git.example.comrepo.owner– your Gitea user or organizationrepo.name– the repository where workflow backups are stored, such asworkflows
These variables are then referenced by the HTTP request nodes that interact with Gitea.
n8n API node: collecting all your workflows
The n8n (API node) queries the n8n API to list all workflows in your instance. You will need to configure authentication, using either an API key or Basic Auth, so the node has permission to access workflow data.
This step is what turns “whatever is in n8n right now” into a list of items the rest of the workflow can process.
splitInBatches / ForEach: processing workflows one at a time
The splitInBatches and ForEach nodes take the list of workflows and handle them individually. This is useful for:
- Avoiding API rate limits.
- Handling errors gracefully without breaking the whole backup run.
- Keeping everything predictable and per-workflow.
Each workflow goes through the same “do you exist in Gitea yet?” check.
GetGitea: checking if a workflow file already exists
The GetGitea node calls the Gitea API to see if there is already a JSON file for the workflow.
GET /api/v1/repos/{owner}/{repo}/contents/{workflowName}.jsonThis node is configured to continue on error. That is important because a 404 from Gitea simply means “this file does not exist yet,” which is a perfectly normal situation for new workflows. Instead of failing, the workflow treats 404 as a signal to go down the “create file” path.
Exist (If node): deciding between create vs update
The Exist If node inspects the result from GetGitea. It checks whether the file is present or whether Gitea responded with an error like 404.
Based on that, it branches into:
- File exists – go to the “update” logic.
- File does not exist – go to the “create” logic.
That way, the workflow uses the same pattern for every workflow, but chooses the right Git action automatically.
Base64EncodeCreate and Base64EncodeUpdate: preparing JSON for Gitea
The Base64EncodeCreate and Base64EncodeUpdate nodes are Code nodes (using Python) that take the workflow object, format it nicely, and convert it to base64.
Gitea’s contents API expects file content to be base64-encoded, so this step is essential. The code follows a pattern like this:
# simplified steps used in the code nodes
json_string = json.dumps(workflow_object, indent=4)
json_bytes = json_string.encode('utf-8')
base64_string = base64.b64encode(json_bytes).decode('utf-8')
The result is a clean, human-readable JSON structure, encoded in a way Gitea understands.
Changed (If node): avoiding noisy commits
The Changed If node compares the newly encoded base64 content with the base64 content that is already stored in Gitea.
If the two match, nothing has changed in the workflow, so there is no reason to create a new commit. If they differ, the workflow proceeds to update the file using the PutGitea node.
This keeps your commit history from turning into a wall of “no-op” updates and makes it easier to see real changes.
PutGitea and PostGitea: writing files into Gitea
Finally, the PutGitea and PostGitea nodes talk to the Gitea API to create or update files.
- Create – use
POST /api/v1/repos/{owner}/{repo}/contents/{name}to create a new file. - Update – use
PUTon the same endpoint, including the current file’sshato tell Gitea which version you are updating.
Between these two, every workflow ends up with a matching JSON file in your repo, updated only when needed.
Authentication and security: making Gitea and n8n trust each other
To let n8n talk to Gitea securely, you will use a Personal Access Token (PAT) with repository read/write permissions.
Steps:
- Create a Personal Access Token in Gitea with the necessary repo scopes.
- Store this token as a credential in n8n, typically as an HTTP header credential.
- Use that credential in your GetGitea, PostGitea, and PutGitea nodes.
In the HTTP header, use the following format:
Authorization: Bearer YOUR_PERSONAL_ACCESS_TOKENPay attention to the space after Bearer. Forgetting that tiny space is a surprisingly common source of “why is this not working” frustration.
Configuration checklist (before you hit “activate”)
To get this n8n backup workflow template running smoothly, walk through this quick list:
- Set the Globals node values:
- Gitea URL (for example,
https://git.example.com) - Repository owner
- Repository name (for example,
workflows)
- Gitea URL (for example,
- Create a Gitea Personal Access Token with repository read/write permissions.
- Add that token to n8n credentials as an HTTP header credential.
- Make sure the n8n API node has permission to list workflows in your n8n instance.
- Assign the Gitea credential to:
- GetGitea
- PostGitea
- PutGitea
- Run the workflow manually at least once before enabling the schedule.
Once everything checks out, you can hand the job off to the scheduler and focus on more interesting problems than “did I remember to export that workflow.”
Testing the backup workflow (before you trust it with your future)
- Run it manually from within n8n and watch the execution logs to confirm each node behaves as expected.
- Open your Gitea repository and verify that JSON files have been created for each workflow.
- Edit one of your n8n workflows slightly, then run the backup workflow again to confirm that the update path triggers and the corresponding file is updated via PutGitea.
- Once you are happy with the behavior, enable the Schedule Trigger to automate everything.
Troubleshooting and practical tips
404 on GetGitea
Seeing a 404 from the GetGitea node is not always a problem. In this context, it usually means:
- The JSON file for that workflow does not exist yet.
The workflow is intentionally built to treat 404 as “file not found, please create it” and then continue down the create path. As long as the node is set to continue on error, this is expected behavior.
Authorization errors that make no sense
If you are getting authorization errors from Gitea:
- Double check the Authorization header format:
- It must be
Bearer YOUR_PERSONAL_ACCESS_TOKENwith a space afterBearer.
- It must be
- Confirm that the token has the correct repository scopes.
- Verify that you pasted the token into the right credential field in n8n.
Most auth issues come down to a small formatting mistake or missing permission.
Large workflow files and repo limits
If your workflows are huge (lots of nodes, heavy data), keep in mind that Gitea can have file size limits depending on how your server is configured.
In those cases, you might consider:
- Compressing older snapshots.
- Storing bulk archives as release artifacts instead of individual content files.
For normal sized workflows, the template should work just fine out of the box.
Keeping Git history clean
The workflow’s comparison step using base64 content is there to avoid unnecessary commits. If nothing changed in a workflow, the file stays untouched and your commit history stays readable instead of “backed up again, nothing changed” on repeat.
File naming strategy for workflow backups
By default, a simple and predictable naming scheme keeps things organized. A common approach is:
{workflowName}.jsonIf you have workflows with the same name across multiple environments, you can prevent collisions by including extra details, for example:
prod_ping_check_12345.json
Using environment names or workflow IDs in the file name makes it easier to tell them apart at a glance.
Next steps: turn on the automation and relax
Once this backup workflow is in place, your n8n setup becomes much safer and easier to manage. You get:
- Versioned, auditable backups in your self-hosted Gitea server.
- A repeatable pattern: fetch workflows, check repo state, encode, compare, and create or update only when needed.
- Less manual exporting, more time for building new automations.
To recap your action plan:
- Import or open the template in n8n.
- Configure your Gitea URL, repo owner, and repo name in the Globals node.
- Set up and secure your Personal Access Token.
- Test the workflow manually and verify JSON files in Gitea.
- Enable the schedule so backups run automatically.
If you want a downloadable workflow JSON