Build an SEO Data Analyst with n8n & LangChain
The day Mia realized her SEO strategy could not keep up
Mia stared at the Search Console dashboard for the third time that morning. As the lead SEO strategist for a fast-growing SaaS company, she had more data than ever before. Impressions were rising, new queries were appearing daily, and the content team kept shipping new pages.
Yet traffic growth had stalled.
Every month she ran the same routine: export Search Console data, push it into Google BigQuery, manually compare keywords to page content, then write long recommendation docs for writers. It worked, but it was slow, repetitive, and impossible to scale across hundreds of URLs.
She knew there were high-impression keywords buried in the data that her content did not properly target. She knew some pages were ranking despite being under-optimized. She also knew she did not have the hours to keep auditing everything by hand.
That was the moment she decided she needed something more than spreadsheets and manual audits. She needed an automated SEO Data Analyst.
Discovering a different way to do SEO audits
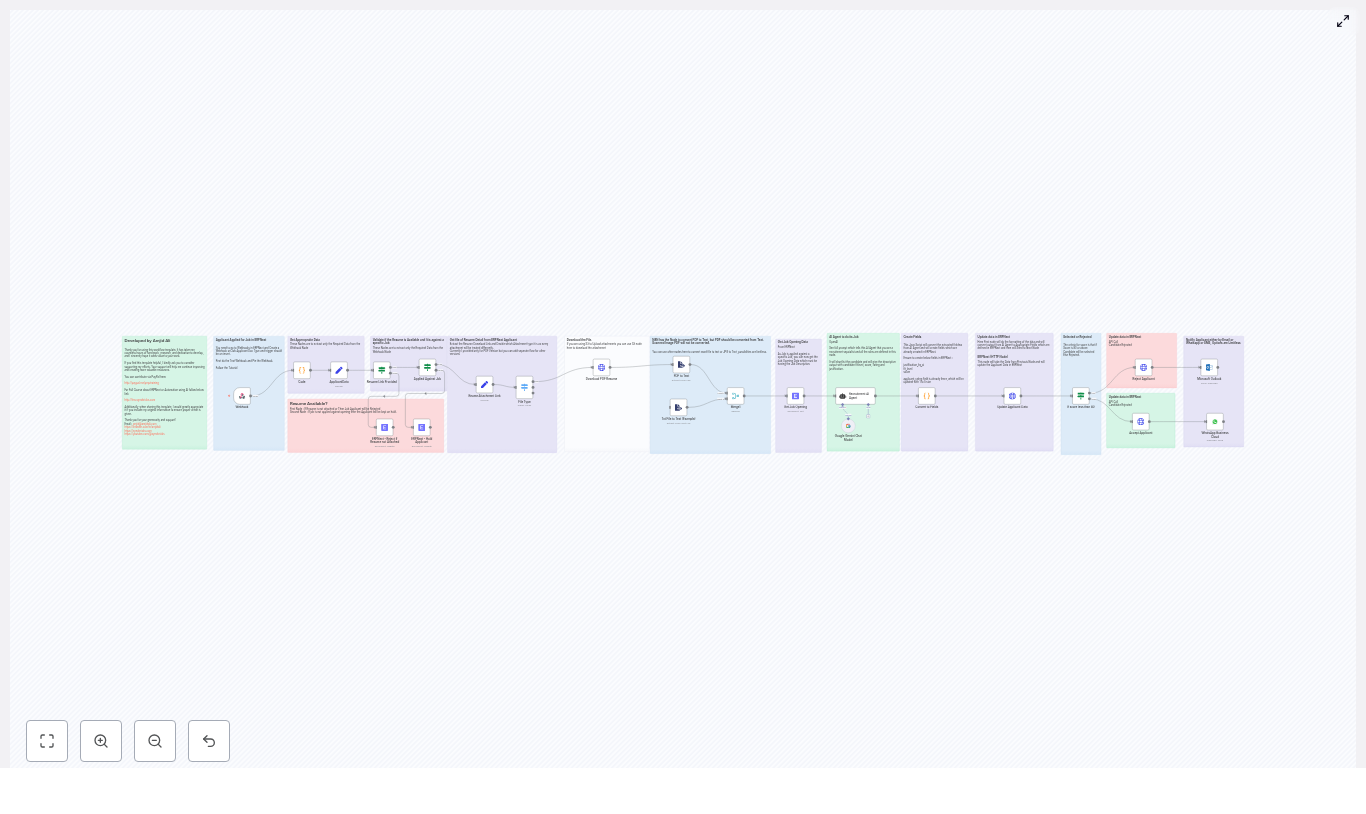
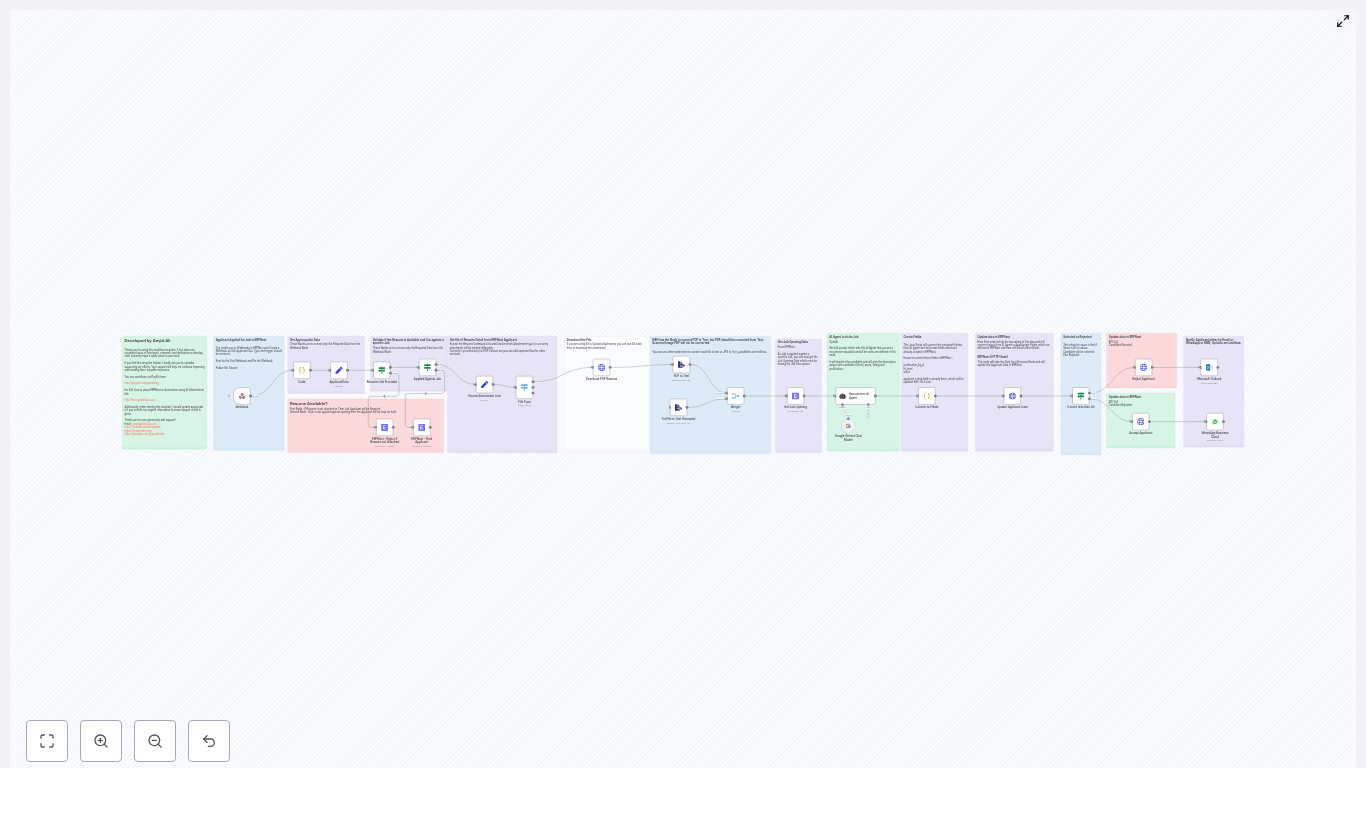
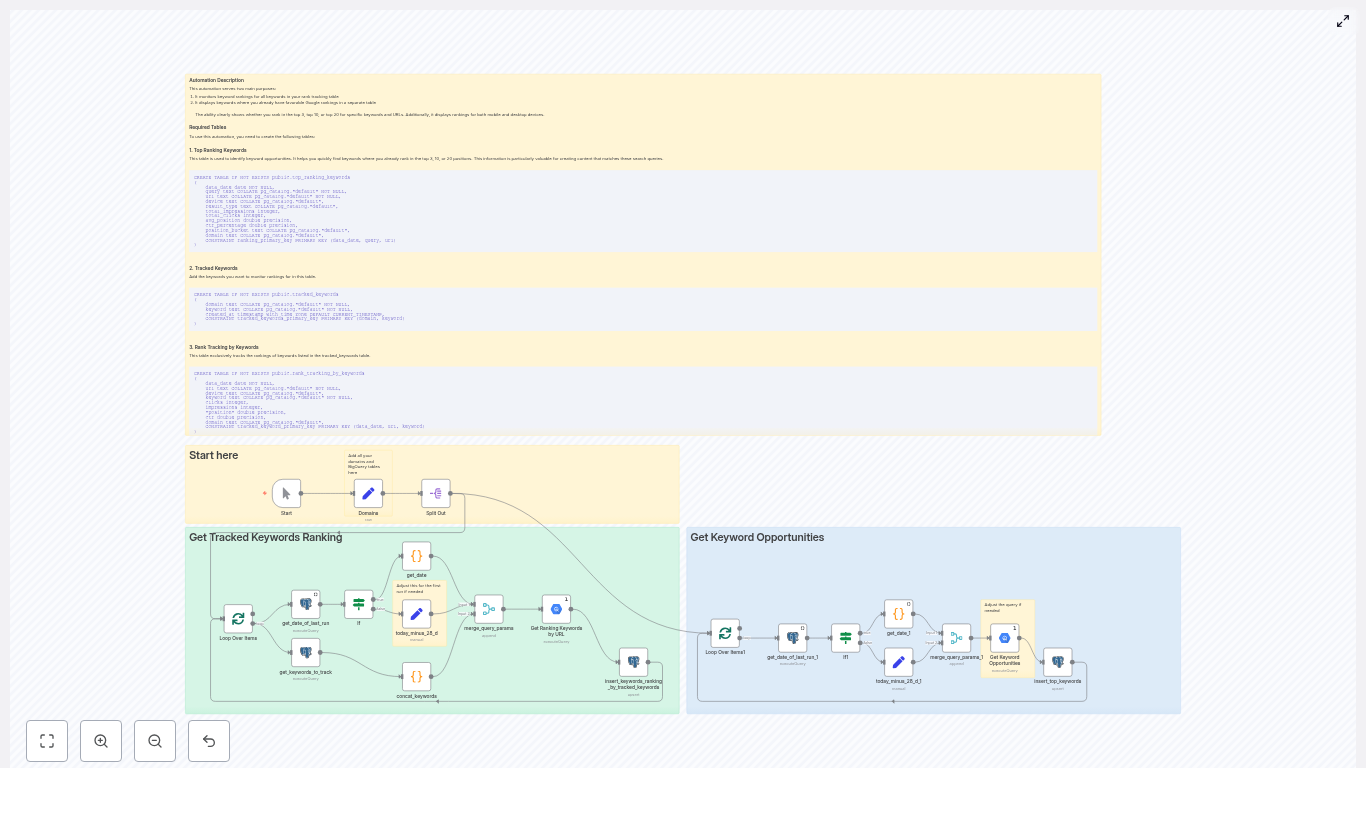
Mia had heard of n8n before, mostly as an automation tool developers liked. One afternoon, while searching for ways to automate SEO workflows, she stumbled on a template that promised to do exactly what she needed: combine n8n, LangChain or another LLM integration, Google BigQuery, and a Website Agent to act as a tireless SEO analyst.
The idea sounded almost too good to be true. This automated workflow would:
- Pull high-impression queries from Search Console data stored in BigQuery
- Crawl pages and analyze their actual content with n-gram analysis
- Compare what users search for with what the page says
- Generate prioritized, human-friendly recommendations for keyword integration
- Run at scale without repeating the same manual work every week
If it worked, Mia could stop drowning in exports and instead focus on strategy. So she decided to test the template on a handful of her most important landing pages.
Meet the cast: the tools behind Mia’s SEO Data Analyst
Before she could bring this automated analyst to life, Mia had to understand the main components that would power it.
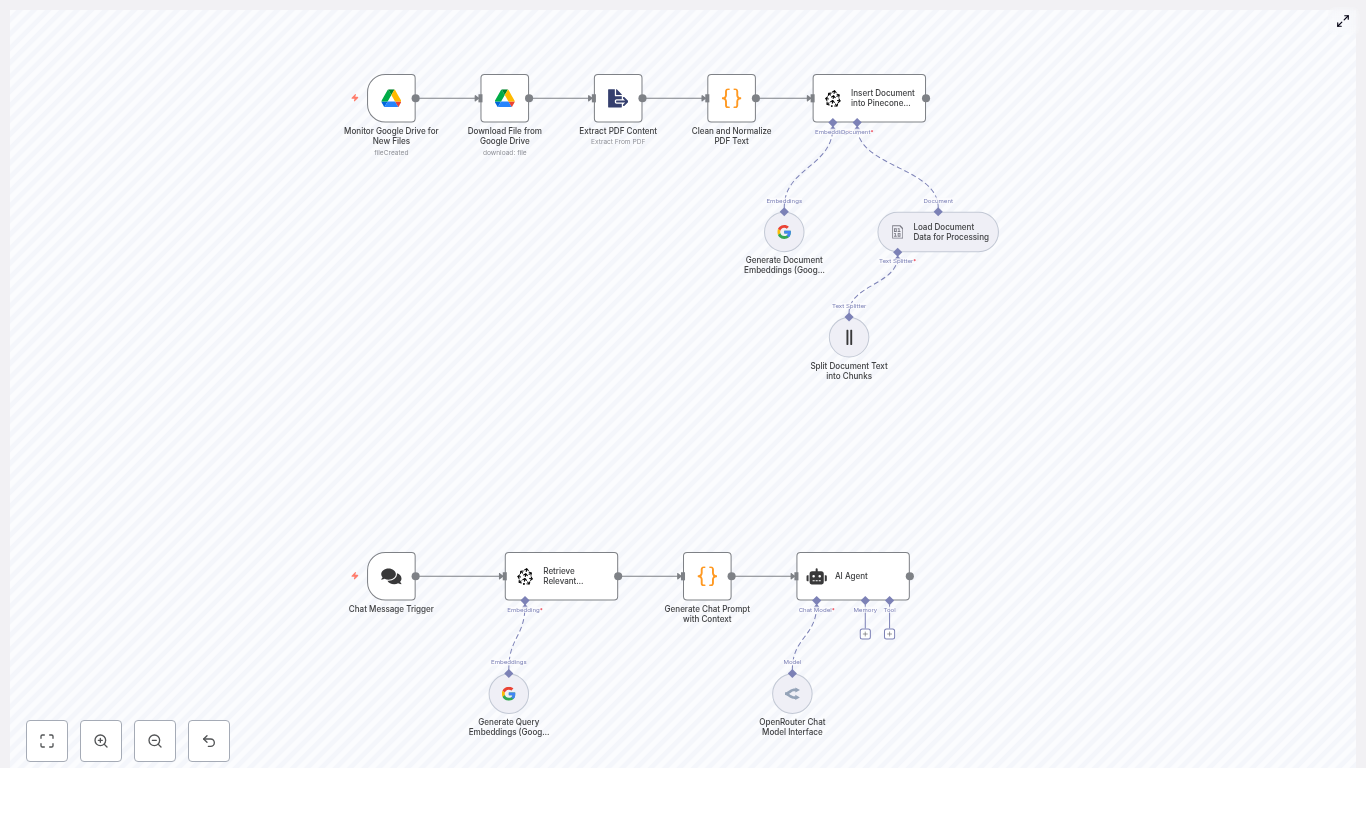
n8n as the conductor of the workflow
n8n would be the central orchestrator. Every step in the SEO audit would be represented as a node: triggers, API calls, LLM prompts, database queries, and crawler actions. With n8n she could:
- Trigger the workflow from a chat-like interface, a schedule, or a manual input
- Connect to OpenAI or another LLM via LangChain
- Run BigQuery queries to fetch Search Console data
- Call a Website Agent to crawl and analyze pages
Instead of juggling multiple tools separately, n8n would stitch them together into one cohesive automation.
LangChain or LLM integration as the analyst brain
The heart of Mia’s new system would be a language model. Through LangChain or a similar LLM integration, it would behave like an SEO analyst that never got tired. Inside the n8n workflow, this LLM would be invoked as an “agent” that could:
- Interpret Mia’s requests, such as “analyze this URL” or “give me a site-wide report”
- Summarize crawled page content into concise overviews
- Perform n-gram analysis on page text to detect common 1-3 word phrases
- Compare search queries to page content to find keyword gaps
- Produce clear, prioritized recommendations in natural language
Instead of handing Mia raw SQL or dense data tables, the LLM would translate everything into business-friendly insights.
Google BigQuery as the SEO data warehouse
Mia already had her Search Console exports flowing into Google BigQuery. This made it the ideal source of truth for search performance. In the new workflow, BigQuery would:
- Store aggregated query data from Search Console
- Provide metrics like impressions, clicks, CTR, and associated pages
- Allow filtering by date range, country, device, and anonymization flags
- Return only the most relevant queries for each URL or for the entire site
Instead of Mia manually writing SQL each time, the workflow would run standardized queries and feed summaries to the LLM.
Website Agent as the on-demand crawler
To understand how well a page matched search intent, Mia needed more than just keywords. She needed to see what was actually on the page. The Website Agent in her n8n workflow would:
- Scrape a given URL
- Extract the title and meta description
- Capture the main body content
- Run n-gram analysis to surface common 1-3 word phrases
This combination of structural data and phrase frequencies would make it easy for the LLM to see which search queries were already covered and which were missing entirely.
Rising action: Mia runs her first automated SEO audit
With the template connected to her BigQuery project and crawling service, Mia was ready. She decided to start small with five key landing pages that drove most of her signups.
Step 1 – A simple request starts the workflow
Instead of opening a spreadsheet, Mia opened n8n. The workflow was configured to accept different types of triggers:
- A chat-style message like “Analyze this URL”
- A scheduled job for weekly or monthly audits
- A manual input where she could paste a list of URLs
She entered one of her highest value URLs. Behind the scenes, the first node identified that she wanted a single-page analysis rather than a full site-wide report, then passed the URL to the next steps.
Step 2 – The Website Agent crawls and analyzes the page
Next, the Website Agent node spun into action. For that URL it returned:
- The current page title
- The meta description
- A summary of the main content
- N-gram frequencies showing the most common 1-3 word phrases
Mia had done this kind of analysis manually before, but now it appeared automatically in the workflow output. She could already see which phrases the page leaned on most heavily.
Step 3 – BigQuery reveals what users are actually searching
Then the BigQuery node kicked in. Using her Search Console exports, the workflow pulled:
- Top queries associated with that URL or the broader site
- Impressions and clicks for each query
- Filters based on her chosen date range, country, and device
- Exclusion of anonymized queries and discover data for cleaner insights
The workflow focused on high-impression, meaningful search terms. These were the keywords that represented real demand, and they would form the basis of the opportunity analysis.
Step 4 – The LLM compares content and queries
This was the part Mia had always wanted to automate. The LLM agent received two key inputs:
- The n-gram data from the crawled page
- The query performance data from BigQuery
It then compared the two, searching for gaps. If a query had high impressions but appeared rarely or not at all in the page content, it flagged it as a missed opportunity. If a query already matched the page well, it marked it as aligned and lower priority.
Instead of Mia manually scanning columns and highlighting cells, the LLM handled this comparison at machine speed.
Step 5 – Turning data into a human-friendly SEO report
The final step of the workflow was to deliver insights that Mia and her content team could actually act on. The LLM generated a structured, business-friendly report that included:
- A quick page analysis with title, meta description, and summary
- The top n-grams that defined the current content
- Top Search Console queries for the URL with clicks and impressions
- A list of recommended keywords to integrate
- Suggested locations to add those keywords, such as title, H2s, body copy, or meta description
- Priority scores based on impressions, clicks, and how poorly or well each query was currently covered
Instead of raw SQL or dense tables, Mia saw sentences like:
- “Queries with high impressions but low presence in page content: ‘SEO checklist’, ‘seo audit’ – suggested to add in H2 and a FAQ.”
- “Top-performing queries driving clicks to this page: ‘best seo tools’ (500 impressions, 30 clicks) – add related terms and an internal link to your tools comparison.”
All the technical data stayed inside the automation. What surfaced to Mia and her writers were clear, action-oriented recommendations.
The turning point: from manual audits to a scalable SEO analyst
After running the workflow on her first five landing pages, Mia noticed something important. The recommendations were not just accurate, they were consistent. The LLM suggested natural keyword integration, not awkward stuffing. It respected page context and tone, and it highlighted opportunities she had missed in previous manual audits.
She started to refine the workflow with a few best practices in mind:
- Filtering anonymized data: She made sure anonymized queries and discover data were excluded so recommendations focused on actionable keywords.
- Smart date ranges: By comparing the last 28 to 90 days, she could see recent trends and growth opportunities instead of outdated queries.
- Impressions and clicks as signals: High impressions told her where demand existed, while clicks showed relevance and potential.
- Natural language in content: She instructed the LLM to recommend organic keyword placement in headings, intros, and FAQs, not to push aggressive keyword stuffing.
- Regular audits at scale: She scheduled the workflow to run periodically so it could re-evaluate pages as user behavior changed.
With these refinements, Mia’s SEO Data Analyst became a trustworthy assistant she could rely on every week.
How Mia used the workflow across different SEO use cases
Closing content gaps on priority landing pages
First, Mia focused on her highest converting landing pages. By running the workflow, she quickly spotted high-impression queries that were not mentioned on those pages at all. Within a few days, her writers updated titles, headers, and body copy to match those search terms more closely, without sacrificing readability.
Finding new content ideas from under-served queries
Next, she pointed the workflow at a broader set of pages. By aggregating queries that appeared frequently in Search Console but were weakly covered across the site, she uncovered entire topic clusters that deserved new content. These gaps turned into new guides, FAQs, and comparison pages that targeted real user demand.
Automated SEO monitoring and quality assurance
Finally, Mia configured a scheduled version of the workflow. Every week, it checked key URLs and alerted her when:
- Important queries started losing visibility
- New high-impression queries appeared that the content did not yet cover
Instead of reactive firefighting, she had an early warning system that kept her SEO strategy aligned with evolving search behavior.
Lessons learned: implementing the n8n SEO Data Analyst template
Looking back, Mia was glad she did not try to automate everything at once. She followed a few practical guidelines that made the rollout smoother:
- Start small: She began with a handful of high-priority pages to validate that the workflow, BigQuery queries, and LLM prompts produced useful results.
- Secure credentials: She stored all BigQuery and crawling service credentials securely inside n8n so the automation could run safely.
- Deterministic LLM settings: She set a lower temperature for the LLM to keep the analysis consistent from run to run.
- Map URLs to owners: Internally, she kept a mapping of page URLs to content owners so the workflow’s recommendations could be routed directly to the right person.
With these foundations in place, scaling to more pages became straightforward.
Resolution: a repeatable, scalable SEO analyst in your stack
In a matter of weeks, Mia had turned a painful, manual audit process into an automated system that worked around the clock. Her SEO Data Analyst built with n8n and LangChain transformed raw Search Console signals into clear, prioritized content improvements.
By combining page-level content analysis with query performance data from BigQuery and a Website Agent crawler, she gained a reliable roadmap for integrating high-value keywords and improving organic performance. Her team stopped guessing which terms to target and started implementing changes backed by data and automation.
If you see yourself in Mia’s story, you can follow a similar path:
- Pick 5 high-priority landing pages
- Connect your Search Console data to Google BigQuery
- Use the n8n SEO Data Analyst template to run your first automated audit
Within a single afternoon, you can have your own SEO analyst quietly working in the background, surfacing opportunities you might otherwise miss.
Call to action: If you want a ready-to-run template or hands-on help adapting it to your stack, reach out to our team to customize and deploy the SEO Data Analyst workflow for your site.