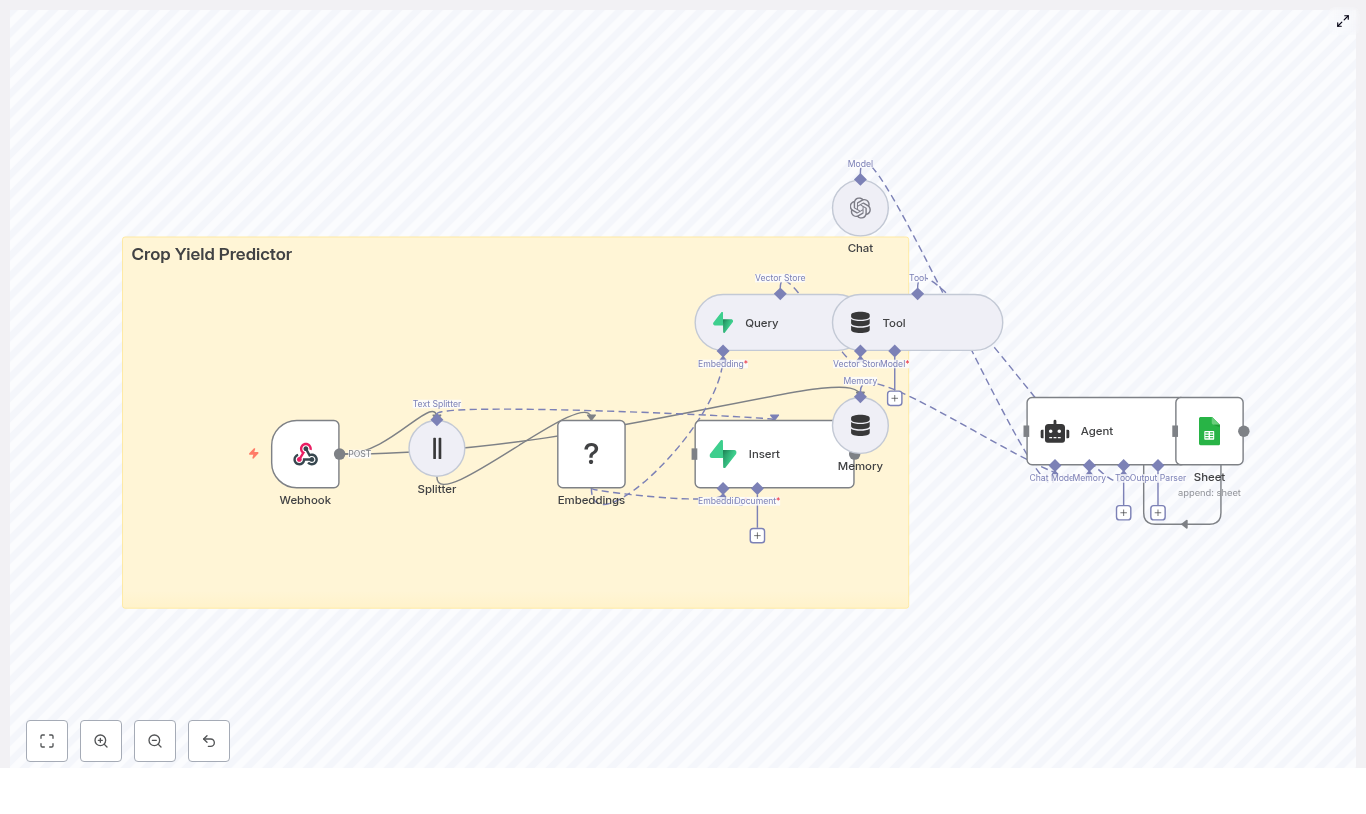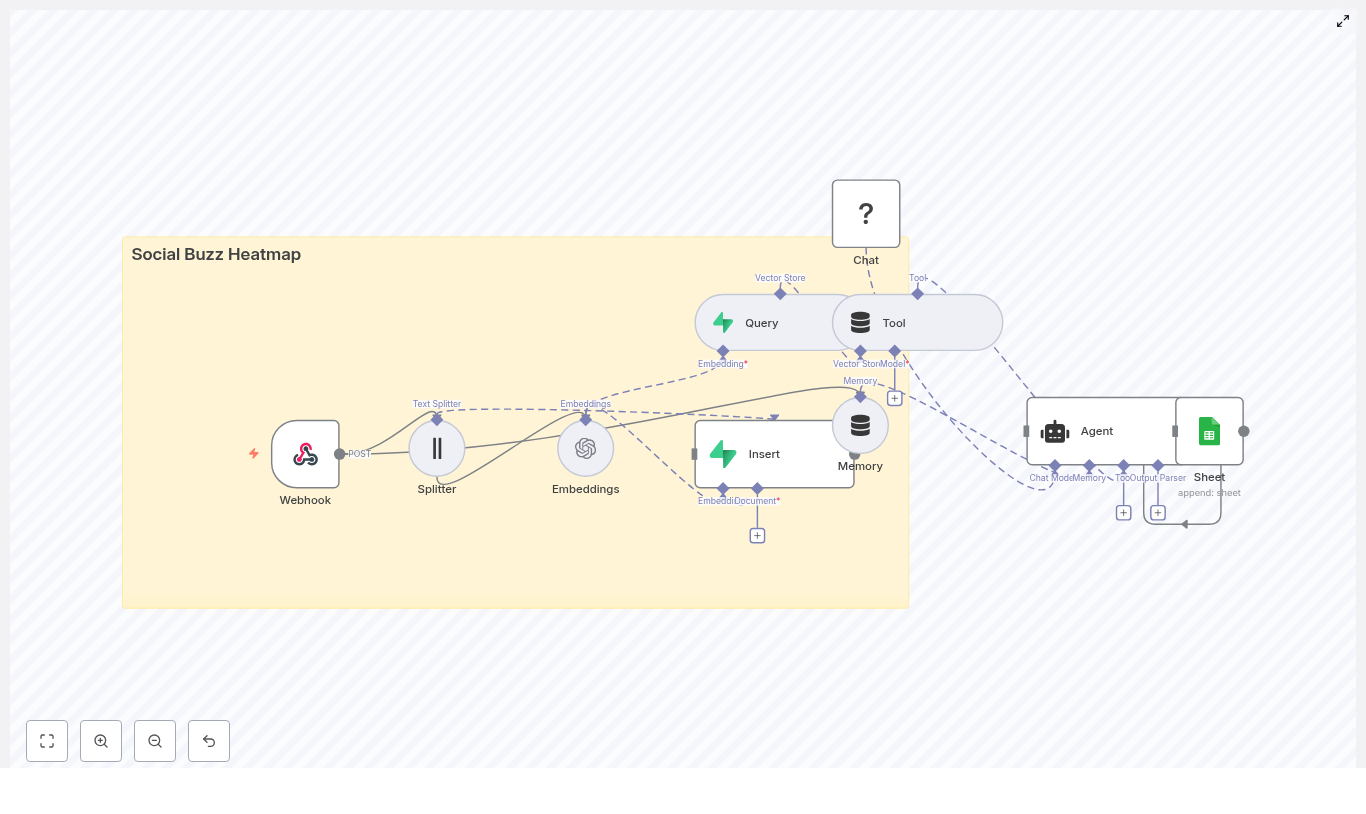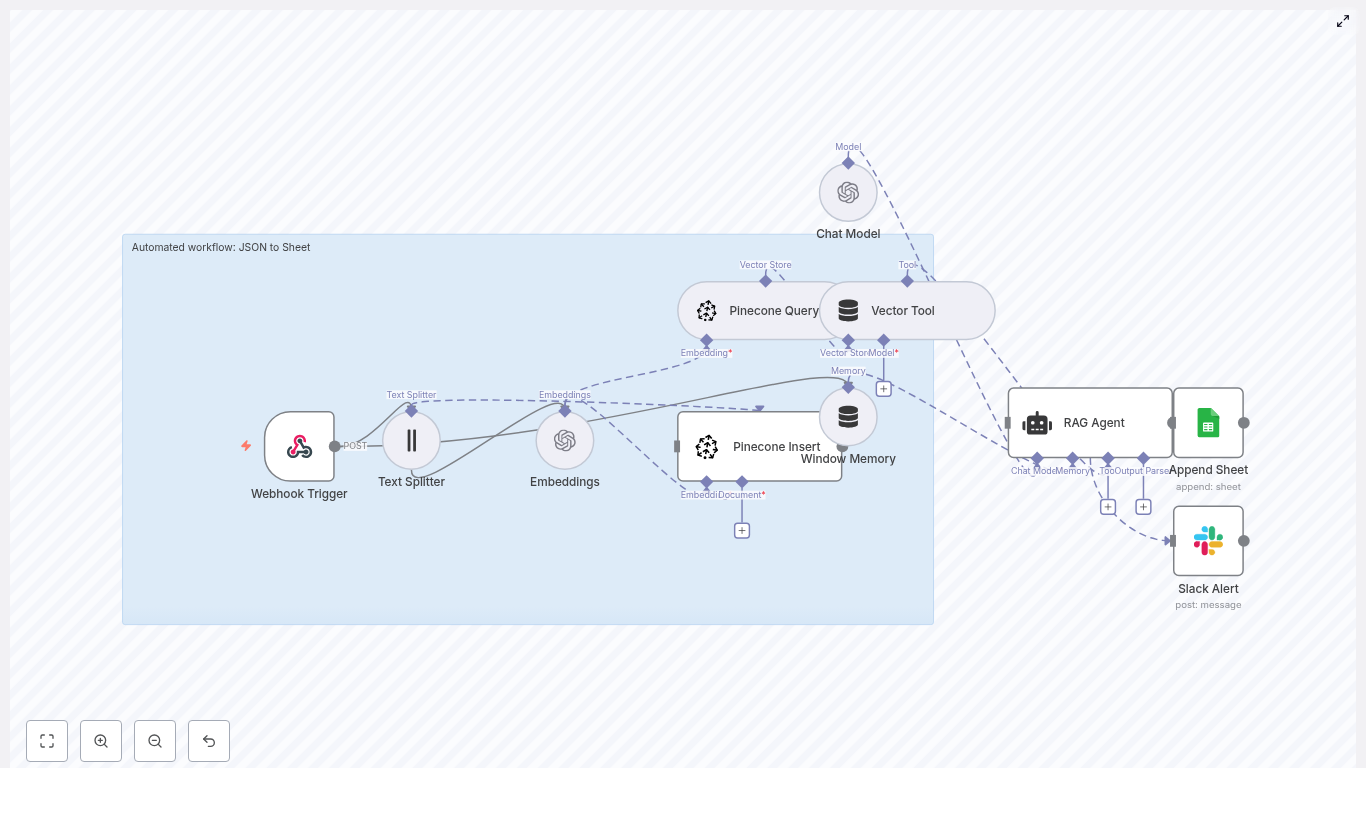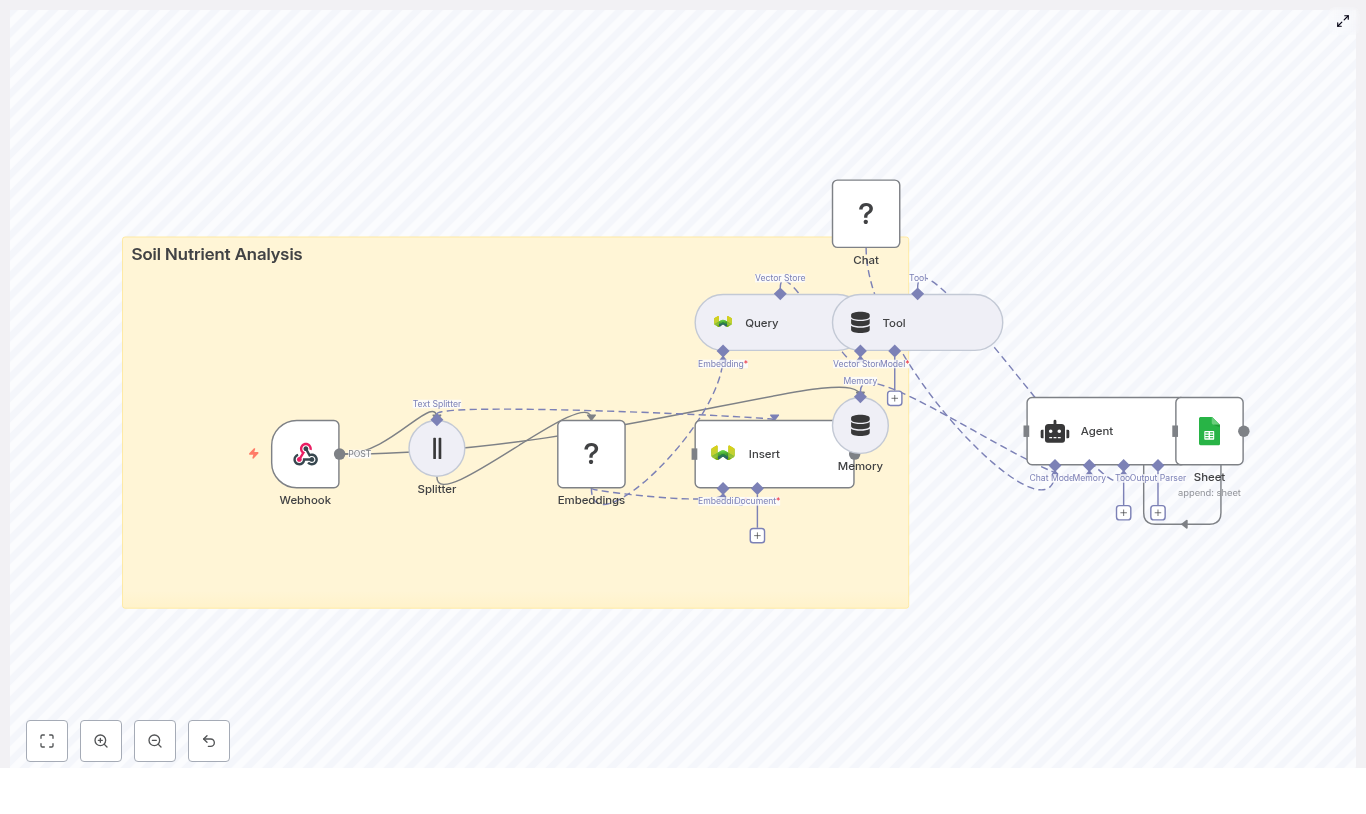
Automating soil nutrient analysis with n8n creates a robust bridge between agronomy workflows and modern data tooling. This guide presents a complete, production-ready n8n workflow template that ingests soil lab reports or raw test results, performs semantic text processing, stores vector embeddings in Weaviate, and uses an LLM-based agent to generate agronomic insights that are then logged to Google Sheets.
Use case overview: automated soil nutrient intelligence
Soil test reports are often lengthy, heterogeneous in structure, and challenging to query at scale. By orchestrating ingestion, semantic indexing, retrieval, and language model reasoning in a single n8n workflow, agronomists, consultants, and farm managers can:
- Search past soil tests by nutrient levels, locations, or time periods
- Maintain a centralized and searchable vector database of historical analyses
- Automatically generate and archive summaries, recommendations, and action plans
- Standardize reporting across labs, formats, and regions
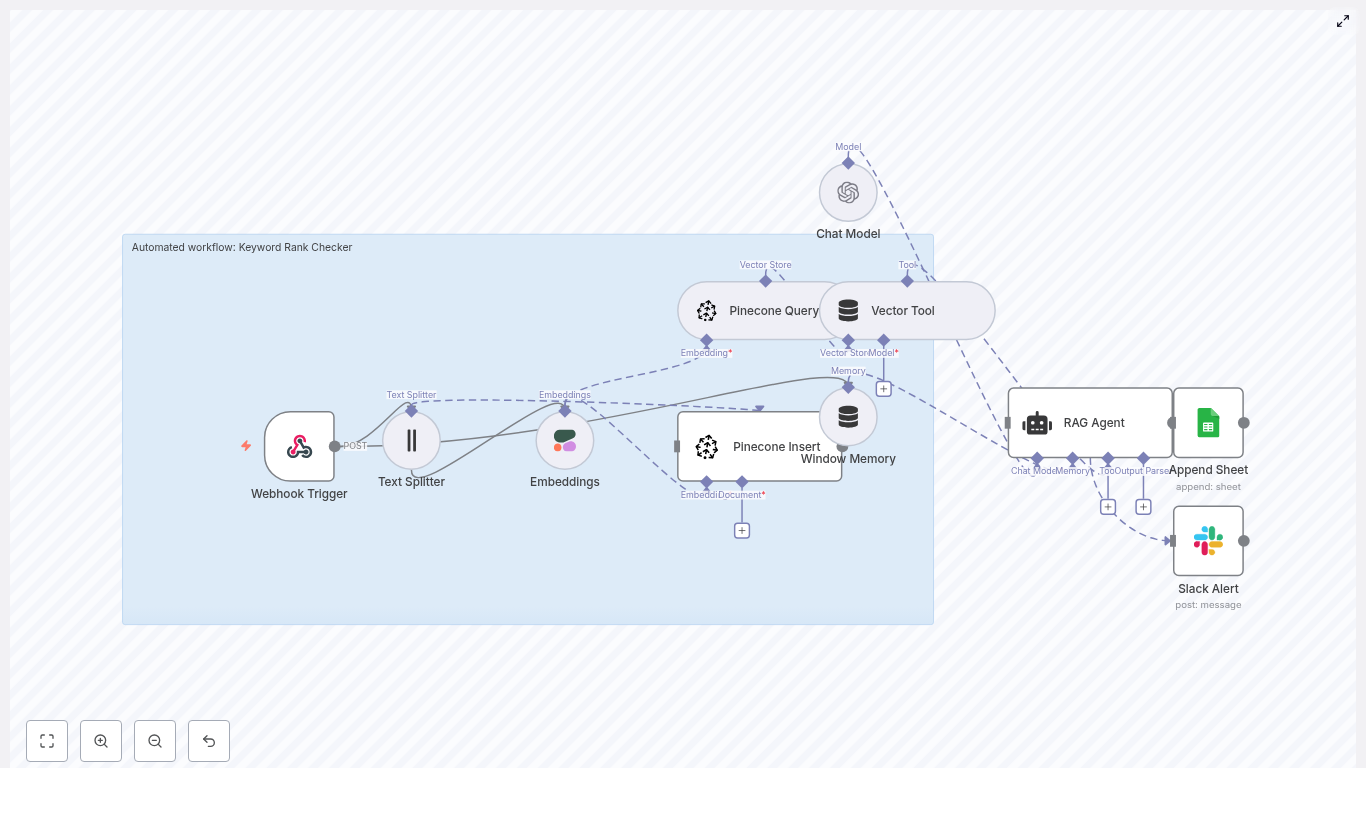
Architecture of the n8n soil nutrient workflow
The template is built as a modular pipeline that can be adapted to different lab formats and organizational requirements. At a high level, the workflow covers:
- Ingestion via a secure Webhook node
- Pre-processing with a text splitter for long reports
- Vectorization using HuggingFace embeddings
- Storage and retrieval in a Weaviate vector index
- Retrieval-augmented generation with an LLM agent that uses tools and memory
- Operational logging in Google Sheets for tracking and reporting
This architecture aligns with best practices for retrieval augmented generation (RAG) and provides a repeatable pattern for other agronomic or scientific document workflows.
Workflow components and data flow
1. Data ingestion with Webhook
The entry point is an n8n Webhook node configured with the POST method and a dedicated path, for example /soil_nutrient_analysis. This endpoint can receive JSON payloads from lab information systems, mobile sampling apps, or custom upload tools.
Example payload:
{ "sample_id": "FIELD-2025-001", "location": "Field A", "date": "2025-08-31", "report_text": "pH: 6.5\nN: 12 mg/kg\nP: 8 mg/kg\nK: 150 mg/kg\n…"
}
The report_text field can contain raw lab output, free text notes, or combined narrative and tabular content. Downstream nodes assume this field is the primary text for embedding and retrieval.
2. Text splitting for long soil reports
Soil reports can be several pages long, which is not optimal for embedding directly. The workflow uses a character text splitter node to break the report into smaller, semantically meaningful chunks. Recommended configuration:
- Chunk size: 400 characters
- Overlap: 40 characters
This configuration preserves context between chunks while controlling vector storage and retrieval costs. The output of the splitter is a list of text segments, each associated with the original sample metadata.
3. Embeddings with HuggingFace
The next stage uses a HuggingFace Embeddings node to convert each chunk into a numerical vector representation. Key configuration points:
- Select a sentence or semantic embedding model suitable for technical text
- Store the HuggingFace API key in n8n credentials for secure access
- Ensure the node is configured to process all chunks produced by the splitter
Each output item from this node contains both the original text chunk and its corresponding embedding vector, ready for insertion into Weaviate.
4. Vector storage in Weaviate
The workflow then uses a Weaviate node in insert mode to persist embeddings and associated metadata. The index (class) name is soil_nutrient_analysis, which should be preconfigured in your Weaviate instance.
A recommended Weaviate schema for this use case includes:
sample_id(keyword)location(text)text_chunk(text)date(date)
Weaviate stores both the vector and these structured fields, enabling hybrid search, filtering by metadata, and efficient semantic queries across large collections of soil reports.
5. Retrieval and tool integration for the agent
To support retrieval augmented generation, the workflow defines a Query node against the soil_nutrient_analysis index. This node performs semantic search over the stored vectors and can be configured to:
- Limit the number of results returned
- Apply filters on
sample_id,location, ordate - Use similarity thresholds to maintain relevance
The Query node is then connected to a Tool node. This exposes the Weaviate search capability as a callable tool to the agent, following a LangChain-style pattern. During execution, the agent can dynamically invoke this tool to retrieve the most relevant chunks for a given analytical question, for example:
“Show fields with low phosphorus levels in the last season.”
6. Memory management for multi-step analysis
To support conversational workflows and multi-step reasoning, the template includes a Memory buffer node. This node stores recent exchanges and intermediate results, which are then fed back into the agent as context.
Best practice is to keep the memory window relatively small to control token usage and maintain clear, focused prompts. This is particularly important when running frequent or batch analyses.
7. Agent configuration with HuggingFace LLM
At the core of the workflow is an Agent (Chat) node that uses a HuggingFace-supported LLM or another compatible chat model. The agent is configured with:
- The Weaviate Query tool for retrieval
- The Memory node for conversational state
- A carefully designed system prompt that describes the agronomic role and expected outputs
With this setup, the agent can synthesize information from retrieved chunks and generate:
- Concise, human-readable summaries of soil test results
- Prioritized nutrient deficiency or surplus assessments
- Specific recommendations, such as fertilizer types, approximate application rates, and sampling intervals
8. Logging outputs to Google Sheets
To close the loop and provide auditability, the workflow ends with a Google Sheets node that appends the agent output to a log sheet. Typical columns include:
timestampsample_idlocationsummaryrecommended_action
This creates a structured, chronological record of automated insights that can feed into dashboards, reporting tools, or downstream decision support systems.
Security and configuration best practices
Securing the webhook endpoint
For production deployments, the ingestion endpoint must not be exposed without protection. Recommended controls include:
- A shared secret header with validation logic inside n8n
- IP allowlists to restrict which systems can call the webhook
- Short-lived signed URLs for manual or ad hoc uploads
Combine multiple mechanisms where possible to reduce the risk of unauthorized data submission.
Choosing an embedding model
Model selection has a direct impact on the quality of semantic search. When configuring the HuggingFace embeddings node:
- Balance cost and latency against recall and precision
- Consider multilingual or domain-adapted models if you work across languages or have very specific agronomic terminology
- Validate performance with a representative set of soil reports and typical user queries
Optimizing the chunking strategy
The default configuration of 400 characters with 40 characters overlap works well for narrative reports and mixed text. For highly structured numeric tables or CSV-style outputs:
- Consider a pre-processing step that converts tabular data into explicit key-value JSON fields
- Use embeddings primarily for narrative interpretation or notes, while numeric fields are handled as structured attributes
This approach helps embeddings capture relationships more reliably and improves downstream reasoning.
Designing an effective Weaviate schema
A well designed schema is critical for fast, relevant retrieval. For the soil_nutrient_analysis class:
- Index
sample_id,date, andlocationfor efficient filtering - Use hybrid search that combines keyword filters with semantic similarity
- Plan for future attributes, such as crop type or management zone, if your use case will expand
Prompt engineering for the agent
To avoid generic outputs and ensure actionable recommendations, define clear instructions in the agent prompt. For example:
“Use the retrieved soil report chunks to produce a 3 line summary and 2 specific fertilizer recommendations with target rates. Reference any chunk IDs or sample identifiers used in your reasoning.”
Such constraints improve transparency, reproducibility, and user trust in the generated recommendations.
Testing, validation, and troubleshooting
Before moving to production, validate each component of the workflow independently and then as an integrated system.
- Embedding quality issues: If retrieval results appear weak or irrelevant, inspect input text cleanliness, verify chunk boundaries, and experiment with alternative embedding models.
- Weaviate insertion errors: Check schema definitions, authentication credentials, and network access rules, including CORS or private network settings.
- Unhelpful or generic agent responses: Refine the system prompt, adjust the number of retrieved chunks, or configure a higher relevance threshold for retrieval.
Practical scenarios and extensions
- Historical analysis: Batch ingest legacy lab PDFs converted to text, then run semantic queries across multiple seasons to identify long term nutrient trends.
- Field technician support: Allow field staff to query, for example, “Which fields require phosphorus in the next month?” and receive ranked, actionable lists derived from recent tests.
- Automated reporting: Schedule monthly runs that generate fertilizer recommendations and automatically append them to management spreadsheets for review.
Deployment strategy and next steps
Once the workflow performs as expected in a development environment, promote it to production with the following practices:
- Use environment specific credentials for HuggingFace embeddings, Weaviate, and Google Sheets.
- Enable logging and retry strategies in n8n to handle transient failures gracefully.
- Set up monitoring and alerts for Weaviate cluster health and embedding API usage.
For more advanced setups, you can enrich context before embedding by joining additional data sources, such as satellite NDVI indices or weather datasets. This can significantly improve the relevance and robustness of agronomic recommendations.
Getting started with the n8n template
To evaluate this approach in your own environment, import the soil nutrient analysis workflow template into an n8n instance and perform a controlled test:
- Secure the webhook endpoint using your preferred authentication method
- Adjust the splitter configuration and embedding model to match your report formats
- Send a sample payload and verify that the Google Sheet log captures the expected summary and recommendations
If you require assistance tailoring the workflow to specific lab formats, integrating with existing farm management systems, or deploying at scale, reach out to your automation team or solution provider for support.