Como um fluxo n8n com IA salvou o Instagram de um pequeno negócio
Quando a caixa de entrada do Instagram começou a virar um caos, Ana achou que estava perdendo o controle. Ela era dona de uma pequena agência de marketing digital, cuidava de vários perfis ao mesmo tempo e, como muita gente, acreditava que conseguiria responder manualmente a todos os comentários.
Por um tempo, funcionou. Mas, conforme os perfis cresceram, os comentários começaram a se acumular: dúvidas técnicas, elogios rápidos, reclamações, spam de promoções aleatórias. Ana começou a notar algo preocupante: comentários importantes ficavam sem resposta por dias, enquanto o algoritmo do Instagram “recompensava” perfis mais rápidos e consistentes na interação.
Foi nesse cenário de pressão, com clientes cobrando mais engajamento e menos tempo de resposta, que ela decidiu que precisava de algo mais inteligente do que simplesmente “tentar responder tudo”. Precisava de automação, mas não queria perder o tom humano da marca. Foi aí que encontrou um template de fluxo no n8n para automatizar respostas de comentários no Instagram usando IA.
O problema de Ana: engajamento crescendo, tempo acabando
Ana sabia que:
- Responder comentários rápido aumentava o engajamento e a percepção de cuidado.
- Manter um tom consistente em todas as respostas era quase impossível com várias pessoas ajudando.
- Spam e comentários irrelevantes tomavam tempo que deveria ser gasto com clientes reais.
Ela já tinha ouvido falar de n8n e de integrações com IA, mas nunca tinha montado um fluxo completo para redes sociais. A ideia de automatizar respostas com inteligência artificial, sem perder o controle, parecia perfeita. Só faltava entender como transformar isso em um fluxo real, seguro e escalável.
O encontro com o template de automação no n8n
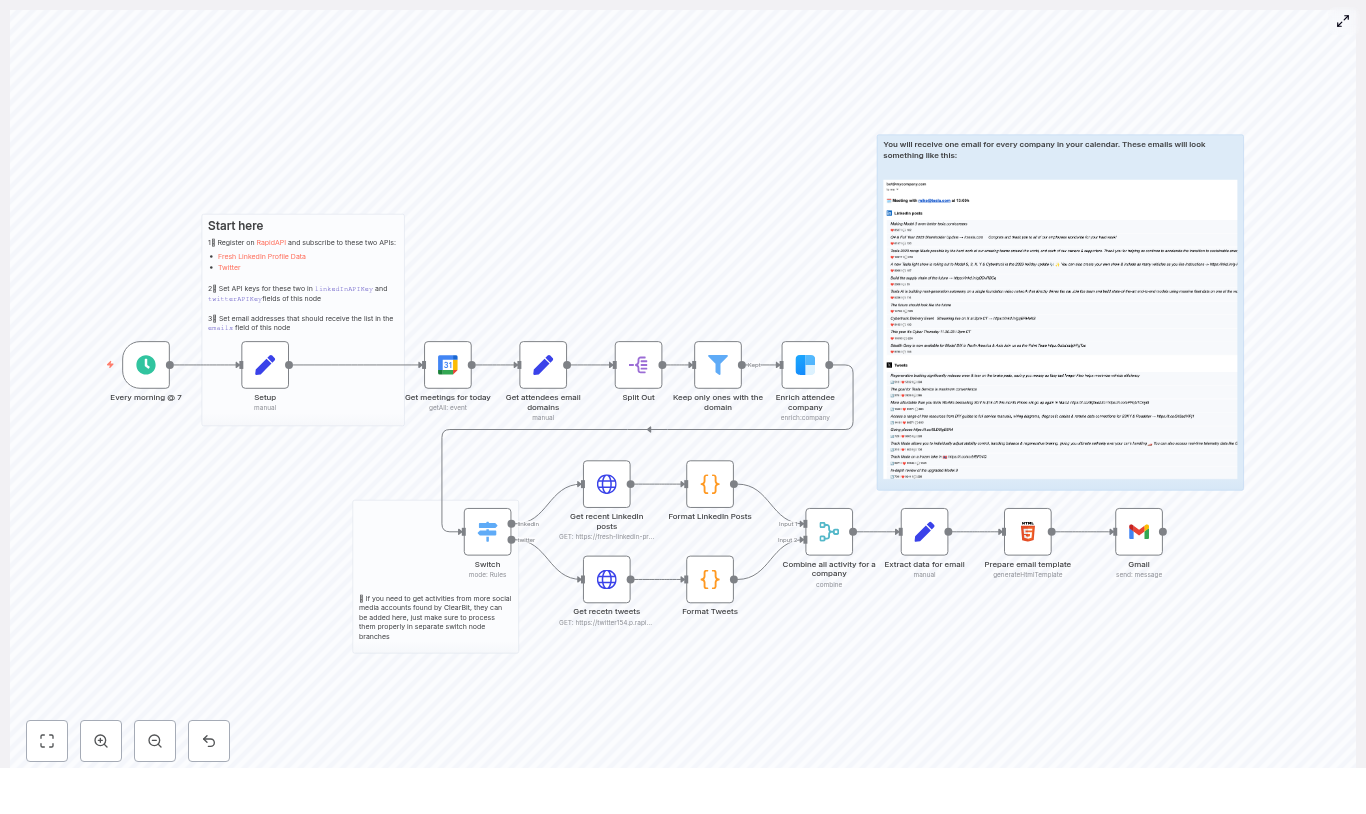
Em uma madrugada de pesquisa, Ana encontrou um template específico: um fluxo n8n que recebia webhooks do Instagram, filtrava comentários, enviava o texto para um modelo de IA via OpenRouter (como Gemini ou similar) e publicava automaticamente a resposta nos comentários.
Olhando a descrição, ela percebeu que não era apenas um “bot de respostas genéricas”, mas uma arquitetura bem pensada, com etapas claras:
- Receber eventos de comentários via Webhook do Instagram.
- Extrair e mapear os dados essenciais do payload.
- Validar para não responder aos próprios comentários do perfil.
- Enriquecer o contexto com dados do post, como a legenda.
- Enviar o comentário para um agente de IA com um prompt controlado.
- Publicar a resposta final via Instagram Graph API.
Era exatamente o que ela precisava. Mas, como toda boa história de automação, a jornada começou com a parte mais “chata” e crítica: o webhook.
Rising action: o dia em que o webhook começou a falar com o Instagram
Primeiro passo de Ana: fazer o Instagram confiar no fluxo
Para que o Instagram avisasse o n8n sempre que chegasse um novo comentário, Ana precisou configurar um Webhook. Ela descobriu que o primeiro contato do Facebook/Instagram não é um comentário real, mas uma verificação.
O Instagram envia uma requisição com três parâmetros importantes:
hub.modehub.challengehub.verify_token
No n8n, Ana criou um nó Webhook e, em seguida, um nó Respond to Webhook configurado para devolver exatamente o valor de hub.challenge quando o hub.verify_token correspondesse ao token configurado no app dela.
Ela usou a expressão:
={{ $json.query['hub.challenge'] }}
Com isso, o Instagram finalmente confirmou: “OK, vou começar a mandar eventos de comentários para este endpoint”. O fluxo de Ana estava oficialmente conectado ao mundo real.
Quando os primeiros comentários chegaram ao n8n
Assim que o primeiro comentário real entrou, Ana viu o payload bruto e percebeu que precisava organizar aqueles dados. O fluxo do template sugeria exatamente isso: usar um nó Set para extrair e padronizar as informações essenciais.
Ela mapeou campos como:
- conta.id: o ID do perfil que recebeu o comentário.
- usuario.id e usuario.name: o autor do comentário.
- usuario.message.id: o ID do comentário.
- usuario.message.text: o texto do comentário.
- usuario.media.id: o ID do post relacionado.
Esse objeto padronizado virou a base para todas as próximas decisões do fluxo. A partir daqui, o n8n sabia exatamente quem comentou, em qual post e o que foi escrito.
Um erro evitado a tempo: a conta respondendo a si mesma
Nos primeiros testes, Ana percebeu um risco óbvio: e se o próprio perfil da marca respondesse a um comentário e o fluxo tentasse responder de novo, gerando um loop infinito de “obrigado”, “de nada”, “obrigado”, “de nada”?
O template já trazia a solução. Ela implementou uma condição simples, porém essencial:
- conta.id != usuario.id
Em outras palavras, o fluxo só seguiria em frente se o comentário viesse de alguém que não fosse o próprio perfil. Isso impediu que a conta respondesse a si mesma e garantiu que apenas comentários de seguidores reais fossem processados.
O ponto de virada: quando a IA começou a responder como a marca
Buscando contexto no post original
Alguns clientes de Ana tinham posts educativos, outros eram mais promocionais, e alguns traziam perguntas nas legendas. A resposta certa a um comentário muitas vezes dependia do contexto do post.
Seguindo a arquitetura do template, Ana adicionou um passo de enriquecimento. Com o media.id em mãos, ela fez uma chamada ao Instagram Graph API para buscar dados relevantes do post, como:
- Caption (legenda do post).
- Hashtags principais.
Essas informações passaram a ser enviadas junto com o comentário para o modelo de IA, permitindo respostas mais inteligentes, alinhadas com o conteúdo original.
Desenhando a “personalidade” da IA
O momento mais delicado foi configurar o agente de IA. Ana não queria um robô genérico. Ela queria um assistente que soasse como a marca: amigável, profissional e direto ao ponto.
Seguindo as boas práticas do template, ela estruturou um prompt controlado com:
- Definição clara de tom: amigável, profissional e educacional quando necessário.
- Orientação para personalização: sempre mencionar o
@usuariono início da resposta. - Regras de spam: quando identificasse algo irrelevante ou spam, a IA deveria retornar apenas
[IGNORE]. - Limite de tamanho: respostas curtas, adequadas para comentários de Instagram.
Ela decidiu usar uma integração típica:
- n8n -> LangChain agent -> OpenRouter (com um modelo como Google Gemini ou similar).
O fluxo foi ajustado para receber apenas o texto final da resposta, sem metadados extras, pronto para publicação.
O prompt resumido que guiou tudo
Depois de alguns testes, Ana chegou a um prompt base em português, simples e direto:
Você é um assistente de IA para perfil de Inteligência Artificial e Automações. Responda em português brasileiro.
- Nome do usuário: {{username}}
- Comentário: {{comentário}}
Regras:
1) Inicie: "Olá @{{username}},"
2) Se for spam ou totalmente irrelevante, responda com: [IGNORE]
3) Seja conciso, útil e amigável. Máx. 2 frases.
A partir daqui, cada comentário que chegava era analisado, contextualizado e respondido pela IA, seguindo exatamente as regras da marca.
O fluxo fecha o ciclo: publicação automática no Instagram
Com a resposta pronta, faltava o passo final: publicar o comentário diretamente no Instagram.
O template orientava usar o endpoint /{comment_id}/replies do Instagram Graph API. Ana configurou um nó HTTP no n8n com:
- Autenticação via headers, usando o token de acesso armazenado em variáveis de ambiente.
- Corpo da requisição contendo o campo
messagecom o texto gerado pela IA.
Quando ela rodou o fluxo em modo de teste, viu o primeiro comentário respondido automaticamente, com um “Olá @usuario,” seguido de uma resposta útil e no tom da marca. Foi o ponto de virada: o que antes era ansiedade por não dar conta, virou alívio por ver o processo funcionando sozinho.
Os bastidores que mantêm tudo seguro e confiável
Ana sabia que não bastava “funcionar”. Precisava funcionar com segurança, controle e escalabilidade. O template ajudou com uma lista de práticas que ela passou a seguir.
Segurança e integridade das requisições
- Validação de assinaturas: ela passou a verificar os headers
x-hub-signatureoux-hub-signature-256para garantir que os eventos vinham realmente do Facebook/Instagram. - Tokens e permissões: os tokens de acesso foram guardados como variáveis de ambiente no n8n, e ela garantiu que as permissões certas estavam ativas, como
pages_manage_comments,instagram_basiceinstagram_manage_comments. - Rate limits: ela implementou uma lógica de retry com backoff exponencial para lidar com erros 429 da Graph API, evitando sobrecarregar o serviço.
- Idempotência: IDs de comentários já respondidos passaram a ser registrados, evitando respostas duplicadas em reexecuções.
- Logs e monitoramento: requests, respostas da IA e status de publicação começaram a ser armazenados para auditoria e diagnóstico.
- Privacidade: nenhum dado sensível ou informação pessoal identificável era exposto nas respostas.
Moderação e personalidade de marca
Com o fluxo estável, Ana começou a refinar o “jeito” da IA responder. Ela ajustou o prompt do agente para garantir:
- Que toda resposta começasse com uma saudação e o
@username(por exemplo, “Olá @usuario,”). - Que perguntas técnicas recebessem orientações práticas, enquanto dúvidas mais complexas direcionassem para um post ou conteúdo mais aprofundado.
- Que elogios fossem respondidos de forma curta, incentivando a seguir e acompanhar o perfil.
- Que, em casos de spam ou conteúdo fora de tópico, a IA retornasse apenas
[IGNORE], deixando a decisão de moderação manual para depois.
Assim, a automação não só respondia rápido, mas também refletia fielmente a voz das marcas que ela gerenciava.
Testando o fluxo antes de soltar na vida real
Antes de ligar o fluxo em produção, Ana decidiu seguir uma rotina de testes bem cuidadosa.
- Ambiente de teste: ela expôs temporariamente o endpoint local do n8n via ferramentas como ngrok ou exposr para validar a verificação do webhook.
- Simulação de payloads: enviou requisições de teste com exemplos reais de comentários: perguntas técnicas, elogios, apenas emojis e casos de spam.
- Métricas monitoradas: passou a acompanhar taxa de respostas, latência da IA, erros de publicação e o percentual de comentários marcados como
[IGNORE].
Isso deu confiança para colocar o fluxo em produção nos perfis dos clientes, sem medo de respostas erradas ou comportamentos inesperados.
Quando os comentários explodiram, o fluxo aguentou
Com o tempo, o trabalho de Ana começou a dar resultado: os perfis cresceram, o número de comentários disparou e o fluxo virou parte crítica da operação. Foi aí que ela começou a pensar em escalabilidade e custos.
Otimizando para volume e custo de IA
Ela aplicou algumas estratégias sugeridas pelo próprio template:
- Fila intermediária: considerou o uso de uma fila como RabbitMQ ou SQS para enfileirar pedidos de resposta e controlar a taxa de chamadas à IA.
- Batching: para comentários não urgentes, planejou agrupar solicitações e processá-las em lote, reduzindo o número de chamadas ao modelo.
- Cache de respostas comuns: identificou perguntas frequentes e passou a reutilizar respostas aprovadas, economizando tokens de IA.
- Prompt enxuto: manteve o prompt o mais curto possível, incluindo apenas o contexto essencial para reduzir o consumo de tokens.
Com isso, o fluxo não só manteve o desempenho, como também se tornou financeiramente viável à medida que os perfis cresciam.
O resultado: mais engajamento, menos sobrecarga
Meses depois, Ana percebeu que algo tinha mudado na rotina dela e dos clientes:
- Comentários passaram a ser respondidos em minutos, não em horas ou dias.
- O tom das respostas era consistente, refletindo a marca em cada interação.
- Spam deixou de consumir tempo, já que o fluxo ignorava automaticamente o que não valia a pena responder.
- O time dela pôde focar em estratégias, conteúdo e campanhas, em vez de apenas “apagar incêndio” na caixa de comentários.
Automatizar respostas com n8n e IA não substituiu o lado humano do trabalho de Ana. Pelo contrário, liberou espaço para que ela fosse mais estratégica, enquanto o fluxo cuidava do operacional repetitivo, com segurança e controle.
Quer repetir a jornada da Ana no seu perfil?
Se você também está sentindo o peso de responder comentários manualmente, mas não quer abrir mão de um tom humano e alinhado à marca, esse tipo de fluxo pode ser o que está faltando na sua operação.
Com um fluxo bem projetado – verificação de webhook, extração e mapeamento de dados, filtragem de comentários do próprio perfil, enriquecimento com dados do post, geração de resposta com IA e publicação automática – você ganha um sistema robusto, escalável e alinhado à sua estratégia de conteúdo.
Próximos passos sugeridos:
- Baixe o template e importe para o seu n8n.
- Teste em um ambiente controlado, com um perfil de teste ou posts específicos.
- Ajuste o prompt da IA para refletir a voz e personalidade da sua marca.
Call to action: Baixe o template, teste no seu n8n e comente abaixo se quiser que eu crie um prompt personalizado para o seu perfil. Se você prefere ajuda profissional para implementar tudo com segurança e boas práticas, entre em contato, ofereço consultoria especializada em automações com n8n e IA.